[toc]
# 一、Java基础
## 1、Java的基本数据类型
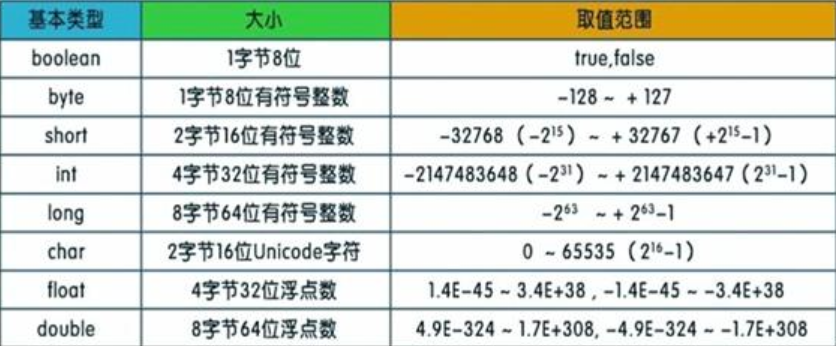
### 1.1 java 的8 型种基本数据类型
### 1.2 java 基本类型与引用类型的区别
基本类型保存原始值,引用类型保存的是引用值(引用值就是指对象在堆中所处的位置/地址)
### 1.3 基本数据类型的装箱和拆箱
自动装箱是 Java 编译器在基本数据类型和对应的对象包装类型之间做的一个转化。比
如:把 int 转化成 Integer,double 转化成 Double,等等。反之就是自动拆箱。
- 原始类型: boolean,char,byte,short,int,long,float,double
- 封装类型:Boolean,Character,Byte,Short,Integer,Long,Float,Double
### 1.4 short s1 = 1; s1 = s1 + 1;有什么错? short s1 = 1; s1+=1;有什么错?
- 1) 对于 `short s1=1;s1=s1+1` 来说,在 s1+1 运算时会自动提升表达式的类型为 int,
那么将 int 赋予给 short 类型的变量 s1 会出现类型转换误。
- 2) 对于 `short s1=1;s1+=1;` 来说 +=是 java 语言规定的运算符,java 编译器会对它
进行特殊处理,因此可以正确编译。
### 1.5 int和Integer的区别
> 1、Integer是int的包装类,int则是java的一种基本数据类型
> 2、Integer变量必须实例化后才能使用,而int变量不需要
> 3、Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值
> 4、Integer的默认值是null,int的默认值是0
延伸:
关于Integer和int的比较
1、由于Integer变量实际上是对一个Integer对象的引用,所以两个通过new生成的Integer变量永远是不相等的(因为new生成的是两个对象,其内存地址不同)。
```java
Integer i = new Integer(100);
Integer j = new Integer(100);
System.out.print(i == j); //false
```
2、Integer变量和int变量比较时,只要两个变量的值是向等的,则结果为true(因为包装类Integer和基本数据类型int比较时,java会自动拆包装为int,然后进行比较,实际上就变为两个int变量的比较)
```java
Integer i = new Integer(100);
int j = 100;
System.out.print(i == j); //true
```
3、非new生成的Integer变量和new Integer()生成的变量比较时,结果为false。(因为 ①当变量值在-128~127之间时,非new生成的Integer变量指向的是java常量池中的对象,而new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同;②当变量值在-128~127之间时,非new生成Integer变量时,java API中最终会按照new Integer(i)进行处理(参考下面第4条),最终两个Interger的地址同样是不相同的)
```java
Integer i = new Integer(100);
Integer j = 100;
System.out.print(i == j); //false
```
4、对于两个非new生成的Integer对象,进行比较时,如果两个变量的值在区间-128到127之间,则比较结果为true,如果两个变量的值不在此区间,则比较结果为false
```java
Integer i = 100;
Integer j = 100;
System.out.print(i == j); //true
Integer i = 128;
Integer j = 128;
System.out.print(i == j); //false
```
对于第4条的原因:
java在编译Integer i = 100 ;时,会翻译成为Integer i = Integer.valueOf(100);,而java API中对Integer类型的valueOf的定义如下:
```java
public static Integer valueOf(int i){
assert IntegerCache.high >= 127;
if (i >= IntegerCache.low && i <= IntegerCache.high){
return IntegerCache.cache[i + (-IntegerCache.low)];
}
return new Integer(i);
}
```
java对于-128到127之间的数,会进行缓存,Integer i = 127时,会将127进行缓存,下次再写Integer j = 127时,就会直接从缓存中取,就不会new了
### 1.6 float f=3.4;是否正确?
不正确。3.4 是双精度数,将双精度型(double)赋值给浮点型(float)属于下转型(down-casting,也称为窄化)会造成精度损失,因此需要强制类型转换 float f =(float)3.4; 或者写成 float f=3.4F;。
## 2、String类型
"String对象一旦被创建就是固定不变的了,对String对象的任何改变都不影响到原对象,相关的任何操作都会生成新的对象“。
1. 固定不变 - 从String 对象的源码中可以看出,String 类声明为 final,且它的属性和方法都被 final 所修饰
2. 任何操作都会生成新对象 - String:: subString(),String::concat() 等方法都会生成一个新的String对象,不会在原对象上进行操作
### 2.1 不可变性设计的初衷
- 字符串常量池的需要。String对象的不可变性为字符串常量池的实现提供了基础,使得常量池便于管理和优化。
- 多线程安全。同一个字符串对象可以被多个线程共享。
- 安全性考虑。字符串应用场景众多,设计成不可变性可以有效防止字符串被有意篡改。
- 由于String对象的不可变性,可以对其HashCode进行缓存,可以作为HashMap,HashTable等集合的key 值。
### 2.2 字符串常量池
**String 对象存在于堆中,字符串常量池存放了它们的引用**。因为 String 对象是不可变的,所以多个引用 "共享" 同一个String 对象是安全的,这种安全性就是 字符串常量池所带来的。
### 2.3 字面量的形式创建字符串
```java
public class ImmutableStrings{
public static void main(String[] args){
String one = "someString"; //one
String two = "someString"; //two
System.out.println(one.equals(two)); // true
System.out.println(one == two); //true
}
}
```
执行完上面的第一句代码之后,会在堆上创建一个String 对象,并把String 对象的引用存放到字符串常量池中,并把引用返回给 one,那当第二句代码执行时,字符串常量池已经有对应内容的引用了,直接返回对象引用给 two。one.equals(two) / one == two 都为true。 图形化如下所示:
<img src="https://i.loli.net/2020/12/20/vUbc8YFRuNAfpKs.png" alt="image-20201220210404446" style="zoom:50%;" />
### 2.4 new关键字创建字符串
```java
public class ImmutableStrings{
public static void main(String[] args) {
String one = "someString";
String two = new String("someString");
System.out.println(one.equals(two));//true
System.out.println(one == two);//false
}
}
```
在使用 new关键字时的情况会有稍微不同,关于这两个字符串的引用任然会存放字符串常量池中,但是关键字 new使得虚拟机在运行时会创建一个新的String对象,而不是使用字符串常量池中已经存在的引用,此时 two 指向 堆中这个新创建的对象,而one 是常量池中的引用。 one.equals(two) 为 true,而 one == two 都为false。
<img src="https://i.loli.net/2020/12/20/YvEhzwg9QHus5m7.png" alt="image-20201220210553909" style="zoom:50%;" />
如果想要one,two都引用同一个对象,则可以使用 String:: intern()方法 - 当调用intern()方法时,如果字符串常量池中已经有了这个字符串,那么直接返回字符串常量池中它的引用,如果没有,那就将它的引用保存一份到字符串常量池中,然后直接返回这个引用。这个方法是有返回值的,是返回引用。
```java
String one = "someString";
String two = new String("someString"); // 仍指向堆中new 出的新对象
String three = two.intern();
System.out.println(one.equals(two)); // true
System.out.println(one == two); // false
System.out.println(one == three); // true
System.out.println(two == three); // false
```
### 2.5 String 对象的创建和字符串常量池的放入
什么时候会创建String 对象?什么时候引用放入到字符串常量池中呢?先需要提出三个常量池的概念:
**静态常量池**:常量池表(Constant Pool table,存放在Class文件中),也可称作为静态常量池,里面存放编译器生成的各种字面量和符号引用。其中有两个重要的常量类型为CONSTANT_String_info和CONSTANT_Utf8_info类型(具体描述可以看看《深入理解Java虚拟机》的p 219 啦~)
**运行时常量池**:运行时常量池属于方法区的一部分,常量池表中的内容会在类加载时存放在方法区的运行时常量池,运行时常量池相比于Class文件常量池一个重要特征是 动态性,运行期间也可以将新的常量放入到 运行时常量池中
**字符串常量池**:在HotSpot 虚拟机中,使用StringTable来存储 String 对象的引用,即来实现字符串常量池,StringTable 本质上是HashSet<String>,所以里面的内容是不可以重复的。一般来说,说一个字符串存储到了字符串常量池也就是说在StringTable中保存了对这个String 对象的引用
执行过程
**在类的解析阶段,虚拟机便会在创建String 对象,并把String对象的引用存储到字符串常量池中**
- 当*.java 文件 编译为*.class 文件时,字符串会像其他常量一样存储到class 文件中的常量池表中,对应于CONSTANT_String_info和CONSTANT_Utf8_info类型;
- 类加载时,会把静态常量池中的内容存放到方法区中的运行时常量池中,其中CONSTANT_Utf8_info类型在类加载的时候就会全部被创建出来,即说明了加载类的时候,那些字符串字面量会进入到当前类的运行时常量池,但是此时StringTable(字符串常量池)并没有相应的引用,在堆中也没有相应的对象产生;
- 遇到ldc字节码指令(该指令将int、float或String型常量值从常量池中推送至栈顶)之前会触发解析阶段,进入到解析阶段,若在解析的过程中发现StringTable已经有与CONSTANT_String_info一样的引用,则返回该引用,若没有,则在堆中创建一个对应内容的String对象,并在StringTable中保存创建的对象的引用,然后返回;
其他值得关注的例子:
```java
String s1 = new String("hb");
String s2 = "hb";
System.out.println(s1 == s2); // false
String s3 = s1.intern(); // 从字符串串常量池中得到相应引用
System.out.println(s2 == s3); // true
System.out.println(" ===== 分割线 ===== ");
String s5 = "hb" + "haha"; // 虚拟机会优化进行优化, 当成一个整体 "hbhaha"成立, 而不会用StringBuild::append()处理
String s6 = "hbhaha";
System.out.println(s5 == s6); // true
System.out.println(" ===== 分割线 ===== ");
String temp = "hb";
String s7 = temp+"haha"; //采用StringBuilder::append()处理
System.out.println(s7 == s6); // false
String s8 = s7.intern(); //从字符串串常量池中得到相应引用
System.out.println(s8 == s6); // true
System.out.println(" ===== 分割线 ===== ");
String s9 = new String("hb") + new String("haha"); //采用StringBuilder::append()处理
System.out.println(s9 == s6); // false
String s10 = s9.intern(); //从字符串串常量池中得到相应引用
System.out.println(s10 == s6); // true
```
[Ref]https://www.jianshu.com/p/eba5f54bcf16?open_source=weibo_search
### 2.6 String 和 StringBuilder、StringBuffer 的区别?
* **StringBuilder** 不是线程安全的,效率高
* **StringBuffer** 是线程安全的,内部使用 synchronized 进行同步,效率低
### 2.7 new String("abc")创建几个对象
```java
String str=new String("abc")
在常量池里有一个"abc"
在堆里有一个"abc"
还有一个引用str
String str1=new String();
只有一个对象
一个引用str1
```
<img src="https://i.loli.net/2020/12/21/mQEDZRtx7fYngdb.jpg" alt="-w500" style="zoom: 67%;" />
String pool若已经存在,只会创建一个对象,如果不存在会创建两个(String pool 和堆中)
使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 "abc" 字符串对象)。
* "abc" 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 "abc" 字符串字面量;
* 而使用 new 的方式会在堆中创建一个字符串对象。
## 3、Java语法相关
### 3.1面向对象的特征有哪些方面?
抽象是将一类对象的共同特征总结出来构造类的过程, 包括数据抽象和行为抽象两方面。抽象只关注对象有哪些属性和行为,并不关注这些行为的细节是什么。
**一、继承:**
- 1.概念:继承是从已有的类中派生出新的类,新的类能吸收已有类的数据属性和行为,并能扩展新的能力
- 2.好处:提高代码的复用,缩短开发周期。
**二、多态:**
- 1.概念:多态(Polymorphism)按字面的意思就是“多种状态,即同一个实体同时具有多种形式。一般表现形式是程序在运行的过程中,同一种类型在不同的条件下表现不同的结果。多态也称为动态绑定,一般是在运行时刻才能确定方法的具体执行对象,这个过程也称为动态委派。
- 2.好处:
- 1)将接口和实现分开,改善代码的组织结构和可读性,还能创建可拓展的程序。
- 2)消除类型之间的耦合关系。允许将多个类型视为同一个类型。
- 3)一个多态方法的调用允许有多种表现形式
**三、封装:**
- 1.概念:就是把对象的属性和操作(或服务)结合为一个独立的整体,并尽可能隐藏对象的内部实现细节。
- 2.好处:
- (1)隐藏信息,实现细节。让客户端程序员无法触及他们不应该触及的部分。
- (2)允许可设计者可以改变类内部的工作方式而不用担心会影响到客户端程序员。
**五个基本原则:**
* <font color='darkred'>单一职责原则(Single-Resposibility Principle):</font>一个类,最好只做一件事,只有一个引起它的变化。单一职责原则可以看做是低耦合、高内聚在面向对象原则上的引申,将职责定义为引起变化的原因,以提高内聚性来减少引起变化的原因。
* <font color='darkred'>开放封闭原则(Open-Closed principle)</font>:软件实体应该是可扩展的,而不可修改的。也就是,对扩展开放,对修改封闭的。
* <font color='darkred'>Liskov替换原则(Liskov-Substituion Principle)</font>:子类必须能够替换其基类。这一思想体现为对继承机制的约束规范,只有子类能够替换基类时,才能保证系统在运行期内识别子类,这是保证继承复用的基础。
* <font color='darkred'>依赖倒置原则(Dependecy-Inversion Principle)</font>:依赖于抽象。具体而言就是高层模块不依赖于底层模块,二者都同依赖于抽象;抽象不依赖于具体,具体依赖于抽象。
* <font color='darkred'>接口隔离原则(Interface-Segregation Principle)</font>:使用多个小的专门的接口,而不要使用一个大的总接口
简单概括:
| 原则 | 描述 |
| ------------ | ---------------------------- |
| 单一职责原则 | 只做一件事 |
| 开放封闭原则 | 对扩展开放,对修改关闭 |
| 里氏替换原则 | 子类必须能够替换基类 |
| 依赖倒置原则 | 抽象不依赖具体,具体依赖抽象 |
| 接口隔离原则 | 多个专门接口,不是一个总的 |
**方法重载(overload)**实现的是编译时的多态性(也称为前绑定),而**方法重写(override)**实现的是运行时的多态性(也称为后绑定)。运行时的多态是面向对象最精髓的东西,要实现多态需要做两件事:
- 1). 方法重写(子类继承父类并重写父类中已有或抽象的方法);
- 2). 对象造型(用父类型引用引用子类型对象,这样同样引用调用同样的方法就会根据子类对象的不同而表现出不同的行为)。
### 3.2 访问修饰符 public,private,protected,以及不写(默认) 时的区别?
| 修饰符 | 当前类 | 同 包 | 子 类 | 其他包 |
| --------- | ------ | ----- | ----- | ------ |
| public | 能 | 能 | 能 | 能 |
| protected | 能 | 能 | 能 | - |
| default | 能 | 能 | - | - |
| private | 能 | - | - | - |
类的成员不写访问修饰时默认为 default。默认对于同一个包中的其他类相当于公 开(public),对于不是同一个包中的其他类相当于私有
(private)。受保护 (protected)对子类相当于公开,对不是同一包中的没有父子关系的类相当于私 有。Java 中,外部类的修饰符只能
是 public 或默认,类的成员(包括内部类)的 修饰符可以是以上四种。
### 3.3 重载和重写的区别
> **重写(Overwrite)**——从字面上看,重写就是重新写一遍的意思。其实就是在子类中把父类本身有的方法重新写一遍。子类继承了父类原有的方法,但有时子类并不想原封不动的继承父类中的某个方法,所以在方法名,参数列表,返回类型(除过子类中方法的返回值是父类中方法返回值的子类时)都相同的情况下, 对方法体进行修改或重写,这就是重写。但要注意子类函数的访问修饰权限不能少于父类的。
重写总结:
- 1.发生在父类与子类之间
- 2.方法名,参数列表,返回类型(除过子类中方法的返回类型是父类中返回类型的子类)必须相同
- 3.访问修饰符的限制一定要大于被重写方法的访问修饰符(public>protected>default>private)
- 4.重写方法一定不能抛出新的检查异常或者比被重写方法申明更加宽泛的检查型异常
> **重载(Overload)**在一个类中,同名的方法如果有不同的参数列表(**参数类型不同、参数个数不同甚至是参数顺序不同**)则视为重载。同时,重载对返回类型没有要求,可以相同也可以不同,**但不能通过返回类型是否相同来判断重载**。
重载总结:
- 1.重载Overload是一个类中多态性的一种表现
- 2.重载要求同名方法的参数列表不同(参数类型,参数个数甚至是参数顺序)
- 3.重载的时候,返回值类型可以相同也可以不相同。无法以返回型别作为重载函数的区分标准
### 3.4 equals与==的区别
(一)、**==:**== 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象。比较的是真正意义上的指针操作。
- 1、比较的是操作符两端的操作数是否是同一个对象。
- 2、两边的操作数必须是同一类型的(可以是父子类之间)才能编译通过。
- 3、比较的是地址,如果是具体的阿拉伯数字的比较,值相等则为true,如:
int a=10 与 long b=10L 与 double c=10.0都是相同的(为true),因为他们都指向地址为10的堆。
(二)、**equals:**equals用来比较的是两个对象的内容是否相等,由于所有的类都是继承自java.lang.Object类的,所以适用于所有对象,如果没有对该方法进行覆盖的话,调用的仍然是Object类中的方法,而Object中的equals方法返回的却是==的判断。
总结:
所有比较是否相等时,都是用equals 并且在对常量相比较时,把常量写在前面(“常量”.equals(obj)),因为使用object的equals object可能为null 则空指针在阿里的代码规范中只使用equals ,阿里插件默认会识别,并可以快速修改,推荐安装阿里插件来排查老代码使用“==”,替换成equals
hashCode() 方法是相应对象整型的 hash 值。它常用于基于 hash 的集合类,如 Hashtable、HashMap、LinkedHashMap 等等。它与equals() 方法关系特别紧密。根据 Java 规范,两个使用 equal() 方法来判断相等的对象,必须具有相同的 hash code。
### 3.5 java中是值传递引用传递?
> - 值传递(pass by value)是指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
> - 引用传递(pass by reference)是指在调用函数时将实际参数的地址直接传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数。
java中方法参数传递方式是按值传递。
如果参数是基本类型,传递的是基本类型的字面量值的拷贝。
如果参数是引用类型,传递的是该参量所引用的对象在堆中地址值的拷贝。
### 3.6 实例化数组后,能不能改变数组长度呢?
不能,数组一旦实例化,它的长度就是固定的
```java
public static void main(String[] args){
int num=5;
Student[] s2=new Student[num];
System.out.println(s2.length);//输出结果为:5
num=6;
System.out.println(s2.length);//输出结果为:5
}
```
### 3.7 形参与实参区别
- **实参(argument):**是在调用时传递给函数的参数. 实参可以是常量、变量、表达式、函数等, 无论实参是何种类型的量,<u>**在进行函数调用时,它们都必须具有确定的值, 以便把这些值传送给形参**</u>。
- **形参(parameter):**不是实际存在变量,所以又称虚拟变量。是在定义函数名和函数体的时候使用的参数,目的是用来接收调用该函数
时传入的参数.在调用函数时,实参将赋值给形参。因而,必须注意**<u>实参的个数,类型应与形参一一对应,并且实参必须要有确定的值</u>**。
说明:
- 1.形参变量只有在被调用时才分配内存单元,在调用结束时, 即刻释放所分配的内存单元。因此,形参只有在函数内部有效。 函数调用结束返回主调函数后则不能再使用该形参变量。
- 2.实参可以是常量、变量、表达式、函数等, 无论实参是何种类型的量,在进行函数调用时,它们都必须具有确定的值, 以便把这些值传送给形参。
- 3.实参和形参在数量上,类型上,顺序上应严格一致, 否则会发生“类型不匹配”的错误。
- 4.函数调用中发生的数据传送是单向的。 即只能把实参的值传送给形参,而不能把形参的值反向地传送给实参。 因此在函数调用过程中,形参的值发生改变,而实参中的值不会变化。
- 5.当形参和实参不是指针类型时,在该函数运行时,形参和实参是不同的变量,他们在内存中位于不同的位置,形参将实参的内容复制一
份,在该函数运行结束的时候形参被释放,而实参内容不会改变。
而如果函数的参数是指针类型变量,在调用该函数的过程中,传给函数的是实参的地址,在函数体内部使用的也是实参的地址,即使用的就是实参本身。所以在函数体内部可以改变实参的值。
### 3.8 Java中内部类和静态内部类的区别
```java
public class OuterClass {
private int numPrivate = 1;
public int numPublic = 2;
public static int numPublicStatic = 3;
private static int numPrivateStatic = 4;
public void nonStaticPublicMethod(){
System.out.println("using nonStaticPublicMethod");
}
private void nonStaticPrivateMethod(){
System.out.println("using nonStaticPrivateMethod");
}
public static void staticPublicMethod(){
System.out.println("using staticPublicMethod");
}
private static void staticPrivateMethod(){
System.out.println("using staticPrivateMethod");
}
class InnerClass{
//Inner class cannot have static declarations
//static int numInnerClass = 4;
//public static void test(){}
int numNonStaticInnerClass = 5;
public void print(){
System.out.println("using InnerClass");
System.out.println("access private field: "+numPrivate);
System.out.println("access public field: "+numPublic);
System.out.println("access public static field: "+numPublicStatic);
System.out.println("access private static field: "+numPrivateStatic);
System.out.println("access numNonStaticInnerClass: "+numNonStaticInnerClass);
nonStaticPrivateMethod();
nonStaticPublicMethod();
staticPrivateMethod();
staticPublicMethod();
}
}
static class StaticNestedClass{
static int numStaticNestedClass = 6;
int numNonStaticNestedClass = 7;
public void print(){
System.out.println("using StaticNestedClass");
System.out.println("access public static field: "+numPublicStatic);
System.out.println("access private static field: "+numPrivateStatic);
System.out.println("access numStaticNestedClass: "+numStaticNestedClass);
System.out.println("access numNonStaticNestedClass: "+numNonStaticNestedClass);
staticPrivateMethod();
staticPublicMethod();
}
}
public static void main(String[] args) {
//内部类实例对象
OuterClass outerClass = new OuterClass();
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
innerClass.print();
System.out.println("=====================");
//静态内部类实例化对象
OuterClass.StaticNestedClass nestedClass = new OuterClass.StaticNestedClass();
nestedClass.print();
}
}
```
结果:
```bash
using InnerClass
access private field: 1
access public field: 2
access public static field: 3
access private static field: 4
access numNonStaticInnerClass: 5
using nonStaticPrivateMethod
using nonStaticPublicMethod
using staticPrivateMethod
using staticPublicMethod
=====================
using StaticNestedClass
access public static field: 3
access private static field: 4
access numStaticNestedClass: 6
access numNonStaticNestedClass: 7
using staticPrivateMethod
using staticPublicMethod
```
#### 静态内部类使用方法
通过外部类访问静态内部类
```java
OuterClass.StaticNestedClass
```
创建静态内部类对象
```java
OuterClass.StaticNestedClass nestedObject = new OuterClass.StaticNestedClass();
```
#### 内部类的使用方法
必须先实例化外部类,才能实例化内部类
```java
OuterClass outerClass = new OuterClass();
OuterClass.InnerClass innerClass = outerClass.new InnerClass();
```
#### 两者区别
1. 内部类, 即便是私有的也能访问,无论静态还是非静态都能访问
- 可以访问封闭类(外部类)中所有的成员变量和方法
- 封闭类(外部类)中的私有private成员变量和方法也可以访问
- 内部类中不可以有静态的变量和静态的方法
2. 静态内部类
- 无权访问封闭类(外部类)的中的非静态变量或者非静态方法
- 封闭类(外部类)中的私有private的静态static成员变量和方法也可以访问
- 静态内部类中可以有静态的变量和静态的方法
3. 内部类可以被声明为private, public, protected, or package private. 但是封闭类(外部类)只能被声明为`public` or package private
#### 为什么使用内部类
- **这是一种对仅在一个地方使用的类进行逻辑分组的方法**:如果一个类仅对另一个类有用,那么将其嵌入该类并将两者保持在一起是合乎逻辑的。
- **它增加了封装**:考虑两个顶级类A和B,其中B需要访问A的成员,如果将A的成员声明为`private`则B无法访问。通过将类B隐藏在类A中,可以将A的成员声明为私有,而B可以访问它们。另外,B本身可以对外界隐藏。
- **这可能会导致代码更具可读性和可维护性**:在外部类中嵌套小类会使代码更靠近使用位置。
#### 序列化
**强烈建议不要对内部类(包括 本地和 匿名类)进行序列化。**
如果序列化一个内部类,然后使用其他JRE实现对其进行反序列化,则可能会遇到兼容性问题
### 3.9 Static关键字有什么作用?
- static可以修饰*属性,方法,代码段,内部类(静态内部类或者嵌套内部类)*
- static修饰的属性的初始化在编译期(类加载的时候),只执行一次,如果在主函数中,优先于主函数执行,**优先于对象存在,优先于构造器初始化**
- static修饰的属性、方法、代码段与具体对象无关,只跟类有关
- **静态方法只能访问静态成员,不可以访问非静态成员**,**静态内部只能使用静态的东西**
- 静态方法中**不能使用this,super**关键字(this和super与对象,即实例相关)
- **静态变量**存在于*方法区*中,**成员变量**存在于*堆内存*中
- 继承情况下,static修饰的变量及方法子类可以继承,但是无法展现多态特性(普通属性也可以继承,但是无法多态,只有普通方法可以多态)
- **不能与abstract关键字共存**(不能使用static abstract void test()),因为静态方法意味着可以直接调用,但是抽象方法不可以有实现,所以无法直接调用。(理解:static是静态,具体,不依赖实例。abstract,抽象,依赖继承类的具体实现)
### 3.10 final在java中的作用,有哪些用法?
- 1. 被final修饰的类不可以被继承
- 2. 被final修饰的方法不可以被重写
- 3. 被final修饰的变量不可以被改变.如果修饰引用,那么表示引用不可变,引用指向的内容可变.
<img src="https://i.loli.net/2020/01/31/bRdkYOoQZLz6IFt.jpg" style="zoom: 67%;" />
- 4. 被final修饰的方法,JVM会尝试将其内联,以提高运行效率
- 5. 被final修饰的常量,在编译阶段会存入常量池中.
除此之外,编译器对final域要遵守的两个重排序规则:
- 在构造函数内对一个final域的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这两个操作之间不能重排序
- 初次读一个包含final域的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序
**写final域重排序规则**
<img src="https://i.loli.net/2020/12/20/d39UVpmY4kIJHFe.png" alt="在这里插入图片描述" style="zoom:50%;" />
由于a,b之间没有数据依赖性,普通域(普通变量)a可能会被重排序到构造函数之外,线程B就有可能读到的是普通变量a初始化之前的值(零值),这样就可能出现错误。而final域变量b,根据重排序规则,会禁止final修饰的变量b重排序到构造函数之外,从而b能够正确赋值,线程B就能够读到final变量初始化后的值。
写final域的重排序规则可以确保:**在对象引用为任意线程可见之前,对象的final域已经被正确初始化过了,而普通域就不具有这个保障**。
**( 二)、读final域重排序规则**
<img src="https://i.loli.net/2020/12/20/37nvSGgjLTC5RbZ.png" alt="在这里插入图片描述" style="zoom:50%;" />
读对象的普通域被重排序到了读对象引用的前面就会出现线程B还未读到对象引用就在读取该对象的普通域变量,这显然是错误的操作。而final域的读操作就“限定”了在读final域变量前已经读到了该对象的引用,从而就可以避免这种情况。
读final域的重排序规则可以确保:**在读一个对象的final域之前,一定会先读这个包含这个final域的对象的引用。**
### 3.11 抽象类和接口的区别?
#### 抽象类: abstract( is a ,模板、可以有内容)
`抽象:不具体,看不明白。抽象类表象体现。`
>在不断抽取过程中,将**共性内容**中的方法声明**抽取**,但是方法不一样,没有抽取,**这时抽取到的方法,并不具体**,需要被指定关键字abstract所标示,声明为抽象方法。
>抽象方法所在类一定要标示为抽象类,也就是说该类需要被abstract关键字所修饰。
**抽象类的特点:**
- 1:抽象方法只能*定义在*抽象类或者接口中,由abstract关键字修饰(可以描述类和方法,*不可以描述变量*)。
- 2:抽象方法只定义方法*声明*,并不定义方法*实现*。
- 3:抽象类*不可以*实例化。
- 4:只有子类继承抽象类并**覆盖**了抽象类中的**所有抽象方法**后,该子类才可以实例化。
- 5: 抽象类里的抽象方法必须被子类**全部实现**(除非子类也是抽象类)
- 6: 可以有**构造器**(抽象类:本质也是一个类,提供一种模板的作用)
- 7: 可以**继承**一个类,**实现**多个接口
- 8: 可以没有抽象方法
- 9: 抽象方法不能为private,不然不能被子类继承实现
- 10:可以有静态代码块,静态方法
- 11: **抽象类实现一个接口时,可以不重写接口的方法**,同理,可以用一个抽象方法去重写接口中的方法,但是没什么意义
**抽象类的细节:**
<font color='darkred'>1:抽象类中是否有构造函数?</font>有,用于给子类对象进行初始化。
<font color='darkred'>2:抽象类中是否可以定义非抽象方法?(模板设计模式运用)</font>
可以。其实,抽象类和一般类没有太大的区别,都是在描述事物,只不过抽象类在描述事物时,有些功能不具体。所以抽象类和一般类在定义上,都是需要定义属性和行为的。只不过,比一般类多了一个抽象函数。而且比一般类少了一个创建对象的部分。
<font color='darkred'>3:抽象关键字abstract和哪些不可以共存?</font>final , private , static
<font color='darkred'>4:抽象类中可不可以不定义抽象方法?</font>可以。抽象方法目的仅仅为了不让该类创建对象。
**模板方法设计模式:**
解决的问题:当功能内部一部分实现时确定,一部分实现是不确定的。这时可以把不确定的部分暴露出去,让子类去实现。
```java
abstract class GetTime{
public final void getTime(){ //此功能如果不需要复写,可加final限定
long start = System.currentTimeMillis();
code(); //不确定的功能部分,提取出来,通过抽象方法实现
long end = System.currentTimeMillis();
System.out.println("毫秒是:"+(end-start));
}
public abstract void code(); //抽象不确定的功能,让子类复写实现
}
class SubDemo extends GetTime{
public void code(){ //子类复写功能方法
for(int y=0; y<1000; y++){
System.out.println("y");
}
}
}
```
#### 接 口( like a , 定义、契约)
- 1:是用关键字interface定义的。
```java
interface Inter{
public static final int x = 3;
public abstract void show();
}
```
- 2:接口中有抽象方法,说明接口**不可以实例化**。接口的子类必须实现了接口中**所有的抽象方法**后,该子类**才可以实例化***(Java8 以后可以不用实现全部,但是要用default去实现一个默认方法)*。否则,该子类还是一个抽象类。
- 3:接口和类不一样的地方,就是,接口可以被多实现,这就是多继承改良后的结果。java将多继承机制通过多现实来体现。
- 4:其实java中是有多继承的。接口可以多继承接口。*(类只能单继承,接口可以多继承)*
- 5: 没有构造方法;
- 6:可以有变量和方法,但是变量被隐式地指定为public static final(也只能是此种修饰,**必须被显式初始化**),方法被指定为public abstract。**所有的方法不能有实现。{}算作空实现。**
- JDK1.8中对接口增加了新的特性:
- 1、默认方法(default method):JDK 1.8允许给接口添加非抽象的方法实现,但必须使用default关键字修饰;**定义了default的方法可以不被实现子类所实现,但只能被实现子类的对象调用;如果子类实现了多个接口,并且这些接口包含一样的默认方法,则子类必须重写默认方法;**
- 2、静态方法(static method):JDK 1.8中允许使用static关键字修饰一个方法,并提供实现,称为接口静态方法。接口静态方法只能通过接口调用(接口名.静态方法名)
- 7: 不能有静态代码块以及静态方法
- 8: **接口可以继承多个接口,但是不能继承任何类,不能实现任何接口**
`抽象是重构的结果,接口是设计的结果。`从设计层面上看,抽象类提供了一种 IS-A 关系,那么就必须满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
从 Java 8 开始,接口也可以拥有默认的方法实现,这是因为不支持默认方法的接口的维护成本太高了。在 Java 8 之前,如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类。*(关键字: default 在接口中方法前面加上修饰符default 编译器就会认为该方法并非抽象方法,可以在接口中写实现。)
```java
interface jiekou{
default public int fun(){return 2;};
}
class AAA implements jiekou{//重写接口默认方法
@Override
public int fun() {return 0;}
}
class BBB implements jiekou{}
public class Main {
public static void main(String[] args) {
AAA aaa = new AAA();
System.out.println(aaa.fun());//0
BBB bbb = new BBB();
System.out.println(bbb.fun());//2
}
}
```
**接口的理解**
接口都用于设计上,设计上的特点:(可以理解主板上提供的接口)
1:接口是对外提供的规则。
2:接口是功能的扩展。
3:接口的出现降低了耦合性。
**抽象类与接口:**
`抽象类`:一般用于描述一个体系单元,将一组**共性内容**进行抽取,特点:可以在类中定义**抽象内容**让**子类实现**,可以定义**非抽象内容**让**子类直接使用**。它里面定义的都是一些体系中的基本内容。
`接口`:一般用于**定义**对象的**扩展功能**,是在继承之外还需这个对象具备的一些功能。
#### 抽象类和接口的共性:
都是不断向上抽取的结果。
#### 抽象类和接口的区别:
| 抽象类 | 接口 |
| ------------------------------------------------------------ | --------------------------------------------------------- |
| 成员修饰符**可自定义**,比如*抽象类的非抽象方法可以用private*。 | 成员修饰符是**固定的**。全都是**public**的 |
| 只能被继承,只能*单继承* | 需要被实现,可以*多实现* |
| 可以定义非抽象方法,子类可以直接继承使用 | 所有都抽象方法,需要子类去实现。(Java8以后可以有默认实现) |
| 使用的是 *is a*关系 | 使用的 *like a* 关系 |
| 可以有普通变量 | 不可以有,但可以有final static常量 |
| 可以有静态方法 | 不可以有静态方法 |
在开发之前,先定义规则,A和B分别开发,A负责实现这个规则,B负责使用这个规则。至于A是如何对规则具体实现的,B是不需要知道的。这样这个接口的出现就降低了A和B直接耦合性。
### 3.12 Hashcode的作用
java的集合有两类,一类是List,还有一类是Set。前者有序可重复,后者无序不重复。当我们在set中插入的时候怎么判断是否已经存在该
元素呢,可以通过equals方法。但是如果元素太多,用这样的方法就会比较满。
于是有人发明了哈希算法来提高集合中查找元素的效率。 这种方式将集合分成若干个存储区域,每个对象可以计算出一个哈希码,可以将
哈希码分组,每组分别对应某个存储区域,根据一个对象的哈希码就可以确定该对象应该存储的那个区域。
hashCode方法可以这样理解:它返回的就是根据对象的内存地址换算出的一个值。这样一来,当集合要添加新的元素时,先调用这个元素
的hashCode方法,就一下子能定位到它应该放置的物理位置上。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行
任何比较了;如果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。这
样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。
### 3.13 Java的四种引用,强弱软虚
#### 强引用
强引用是平常中使用最多的引用,强引用在程序内存不足(OOM)的时候也不会被回收,使用方式:
```java
String str = new String("str");
```
#### 软引用
软引用在程序内存不足时,会被回收,使用方式:
```java
// 注意:wrf这个引用也是强引用,它是指向SoftReference这个对象的,
// 这里的软引用指的是指向new String("str")的引用,也就是SoftReference类中T
SoftReference<String> wrf = new SoftReference<String>(new String("str"));
```
可用场景: 创建缓存的时候,创建的对象放进缓存中,当内存不足时,JVM就会回收早先创建的对象。
#### 弱引用
弱引用就是只要JVM垃圾回收器发现了它,就会将之回收,使用方式:
```java
WeakReference<String>wrf=newWeakReference<String>(str);
```
可用场景:Java源码中的java.util.WeakHashMap中的key就是使用弱引用,我的理解就是,
一旦我不需要某个引用,JVM会自动帮我处理它,这样我就不需要做其它操作。
#### 虚引用
虚引用的回收机制跟弱引用差不多,但是它被回收之前,会被放入ReferenceQueue中。注意哦,其它引用是被JVM回收后才被传入
ReferenceQueue中的。由于这个机制,所以虚引用大多被用于引用销毁前的处理工作。还有就是,虚引用创建的时候,必须带有
ReferenceQueue,使用
```java
PhantomReference<String>prf=newPhantomReference<String>(new String("str"),newReferenceQueue<>());
```
可用场景: 对象销毁前的一些操作,比如说资源释放等。** Object.finalize() 虽然也可以做这类动作,但是这个方式即不安全又低效
上诉所说的几类引用,都是指对象本身的引用,而不是指 Reference 的四个子类的引用( SoftReference 等)。
### 3.14 Java创建对象有几种方式?
java中提供了以下四种创建对象的方式:
1. new创建新对象
2. 通过反射机制
3. 采用clone机制
4. 通过序列化机制
### 3.15 有没有可能两个不相等的对象有相同的hashcode
有可能.在产生hash冲突时,两个不相等的对象就会有相同的 hashcode 值.当hash冲突产生时,一般有以下几种方式来处理:
1. 拉链法:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以
用这个单向链表进行存储.
2. 开放定址法:一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
3. 再哈希:又叫双哈希法,有多个不同的Hash函数.当发生冲突时,使用第二个,第三个….等哈希函数计算地址,直到无冲突.
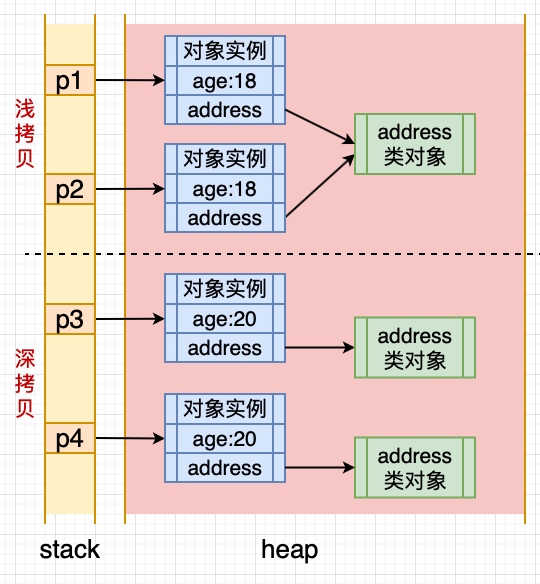
### 3.16 拷贝和浅拷贝的区别是什么?
`浅拷贝`:拷贝对象和原始对象的引用类型引用同一个对象。直接调用clone方法。
`深拷贝`:拷贝对象和原始对象的引用类型引用不同对象。**要克隆**的类和类中所有**非基本数据类型**的属性**对应的类**。先调用clone方法获得相关属性,再依次复制到自己的类中。
`clone的替代方案`:使用 clone() 方法来拷贝一个对象即复杂又有风险,它会抛出异常,并且还需要类型转换。Effective Java 书上讲到,最好不要去使用 clone(),可以使用拷贝构造函数或者`拷贝工厂`来拷贝一个对象。
### 3.17 a=a+b与a+=b有什么区别吗?
+= 操作符会进行隐式自动类型转换,此处a+=b隐式的将加操作的结果类型强制转换为持有结果的类型, 而a=a+b则不会自动进行类型转换.
如:
```java
byte a = 127;
byte b = 127;
b = a + b; // 报编译错误:cannot convert from int to byte
b += a;
```
以下代码是否有错,有的话怎么改?
```java
short s1= 1;
s1 = s1 + 1;
```
有错误.short类型在进行运算时会自动提升为int类型,也就是说 s1+1 的运算结果是int类型,而s1是short类型,此时编译器会报错.
```java
short s1= 1;
s1 += 1;//+=操作符会对右边的表达式结果强转匹配左边的数据类型,所以没错.
```
### 3.18 char 型变量中能不能存贮一个中文汉字,为什么?
char 类型可以存储一个中文汉字,因为 Java 中使用的编码是 Unicode(不选择任何特定的编码,直接使用字符在字符集中的编号,这是统一的唯一方法),一个 char 类型占 2 个字节(16 比特),所以放一个中文是没问题的。
### 3.19 如何实现对象克隆?
有两种方式:
1). 实现 Cloneable 接口并重写 Object 类中的 clone()方法;
2). 实现 Serializable 接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆,代码如下。
```java
public class MyUtil {
@SuppressWarnings("unchecked")
public static <T extends Serializable> T clone(T obj) throws Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new
ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
// 说明:调用 ByteArrayInputStream 或 ByteArrayOutputStream对象的 close 方法没有任何意义
// 这两个基于内存的流只要垃圾回收器清理对象就能够释放资源,这一点不同于对外部资源(如文件流)的释放
}
}
```
注意:基于 序列 化和 反序 列化 实现 的克 隆不 仅仅 是深 度克 隆, 更重 要的 是通 过泛型限 定, 可以 检查 出要 克隆 的对 象是 否支 持
序 列化 ,这 项检 查是 编译 器完 成的 ,不是 在运 行时 抛出 异常 ,这种 是方 案明 显优 于使 用 Object 类的 clone 方法 克隆 对象。 让问
题在 编译 的时 候暴 露出 来总 是好 过把 问题 留到 运行 时。
### 3.20 一个”.java”源文件中是否可以包含多个类(不是内部类)?有什么限制?
可以,但一个源文件中最多只能有一个公开类(public class)而且文件名必须和公开类的类名完全保持一致。
### 3.21 异或运算
& | ^
&& 和 ||具有短路功能
快速将某数扩大或缩小,使用<<< 或者>>> 无符号位移
test:不使用第三方变量进行两个值互换( ^ :相同为0,不同为1)
```java
int a =3,b=5;
a = a+b;
b = a-b;
a = a-b;
a = a^b;
b = a^b;
a = a^b;
```
### 3.22 switch语句相关
```java
switch(变量){
case 值:要执行的语句;break;
...
default:要执行的语句;
}
```
细节:
- 1)break是可以省略的,如果省略了就一直执行遇到break为止;
- 2)switch小括号中的变量为**char, byte, short, int, Character, Byte, Short, Integer, String,enum** *(注意long类型不可以,因为不能隐式转换为int,JDK7前:只有改数据类型可以自动转型为int时才可以,JDK7后,String类型也支持);*
- 3)default可以写在switch中的任意位置,如果将default放在第一行,不管expression与case中的value是否匹配,程序会从default开始执行到第一个break出现。
### 3.23 初始化顺序
1. 类中的属性都会被自动初始化(类加载的准备阶段,<font color='darkred'>基本类型为0,引用对象为null</font>),方法中的不会
2. **继承情况下初始化顺序**
```java
class Father {
Father() {System.out.println("父类的构造器");}
int i = fatherCommonMethod();
static String s = fatherStaticMethod();
static void fatherStaticMethod() {
System.out.println("父类的静态方法");
}
void fatherCommonMethod() {
System.out.println("父类的普通方法");
}
}
class Son extends Father {
Son(){System.out.println("子类的构造器");}
int j = sonCommonMethod();
static String s = sonStaticMethod();
static void sonStaticMethod() {
System.out.println("子类的静态方法");
}
void sonCommonMethod() {
System.out.println("子类的普通方法");
}
}
```
output
```java
父类的静态方法
子类的静态方法
父类的普通方法
父类的构造器
子类的普通方法
子类的构造器
```
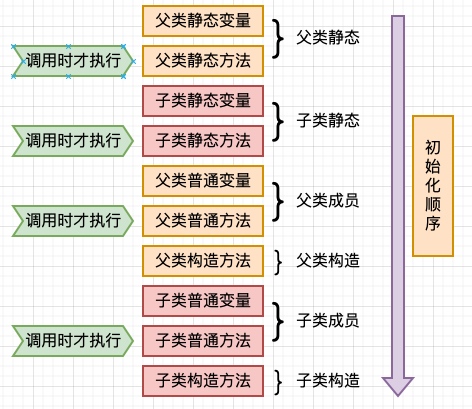
父类静态变量,父类静态代码块(并列优先级,按照代码中出现的先后顺序执行,且只有第一次加载时执行) -->子类静态变量,子类静态代码块(同上,按出现顺序) -->main方法 -->父变量,父初始块(按出现顺序) --> 父构造器 -->子变量,子初始块(按出现顺序) -->子构造器
### 3.24 泛型
jdk1.5之后出现的一种安全机制。表现格式:< >
只要带有<>的类或者接口,都属于带有类型参数的类或者接口,在使用这些类或者接口时,必须给<>中传递一个具体的引用数据类型。
`作用`:在编译期间确保了正确性
`好处`:
1:将运行时期的问题ClassCastException问题转换成了编译失败,体现在编译时期,程序员就可以解决问题。
2:避免了强制转换的麻烦。
```java
/*
第一个问题是有关get方法的,我们每次调用get方法都会返回一个Object对象,
每一次都要强制类型转换为我们需要的类型,这样会显得很麻烦;
第二个问题是有关add方法的,假如我们往聚合了String对象的ArrayList中
加入一个File对象,编译器不会产生任何错误提示,而这不是我们想要的。
*/
public class ArrayList {
public Object get(int i) { ... }
public void add(Object o) { ... }
...
private Object[] elementData;
}
```
所以,从Java 5开始,ArrayList在使用时可以加上一个类型参数(type parameter),这个类型参数用来指明ArrayList中的元素类型。类型参数的引入解决了以上提到的两个问题
```java
ArrayList<String> s = new ArrayList<String>();
s.add("abc");
String s = s.get(0); //无需进行强制转换
s.add(123); //编译错误,只能向其中添加String对象
...
```
`原理`:内部使用object对象或者指定的边界类型,在编译后变成强制转换。
`泛型擦除`:在编辑器检查泛型类型的正确性后,生成的类文件中是没有泛型的。
```java
//定义泛型
public class Pair<T, U> {
private T first;
private U second;
public Pair(T first, U second) {
this.first = first;
this.second = second;
}
public T getFirst() {return first;}
public U getSecond() {return second;}
public void setFirst(T newValue) {first = newValue;}
public void setSecond(U newValue) {second = newValue;}
}
// 实际上,从虚拟机的角度看,不存在“泛型”概念。
//比如上面我们定义的泛型类Pair,在虚拟机看来(即编译为字节码后),它长的是这样的:
public class Pair {
private Object first;
private Object second;
public Pair(Object first, Object second) {
this.first = first;
this.second = second;
}
public Object getFirst() {return first;}
public Object getSecond() {return second;}
public void setFirst(Object newValue) {first = newValue;}
public void setSecond(Object newValue) {second = newValue;}
}
```
简单地验证下,编译Pair.java后,键入“javap -c -s Pair”可得到:
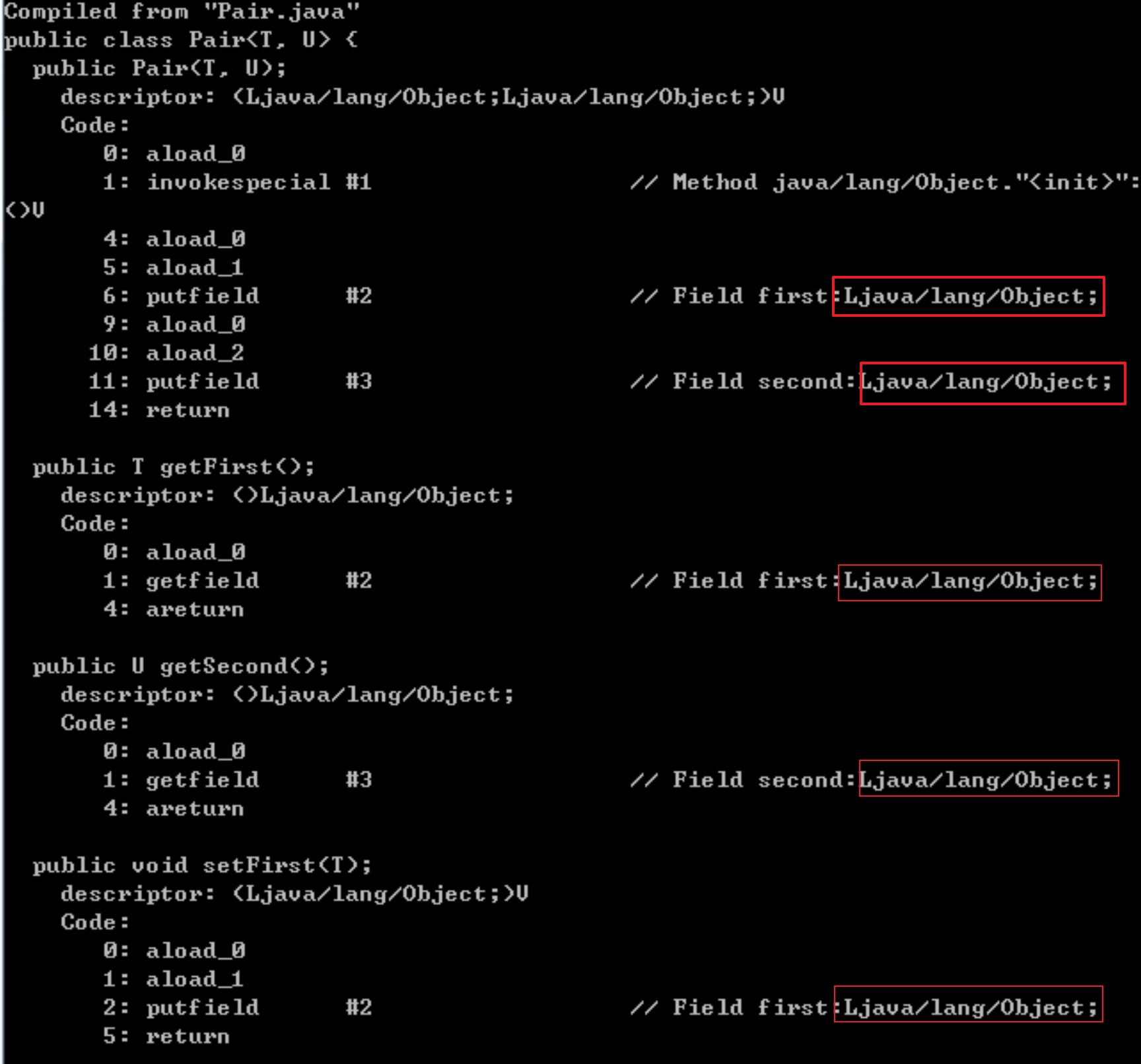
`泛型补偿`:在编译时已经确定是同一个类型的元素,在运行时内部进行一次转换,使用者无需再做转换动作。
由于在虚拟机中泛型类Pair变为它的raw type,因而getFirst方法返回的是一个Object对象,而从编译器的角度看,这个方法返回的是我们实例化类时指定的类型参数的对象。实际上, 是编译器帮我们完成了强制类型转换的工作。也就是说编译器会把对Pair泛型类中getFirst方法的调用转化为两条虚拟机指令:
```
第一条是对raw type方法getFirst的调用,这个方法返回一个Object对象;
第二条指令把返回的Object对象强制类型转换为当初我们指定的类型参数类型。
```
```java
public class Pair<T, U> {
//请见上面贴出的代码
public static void main(String[] args) {
String first = "first", second = "second";
Pair<String, String> p = new Pair<String, String>(first, second);
String result = p.getFirst();
}
}
```
看字节码
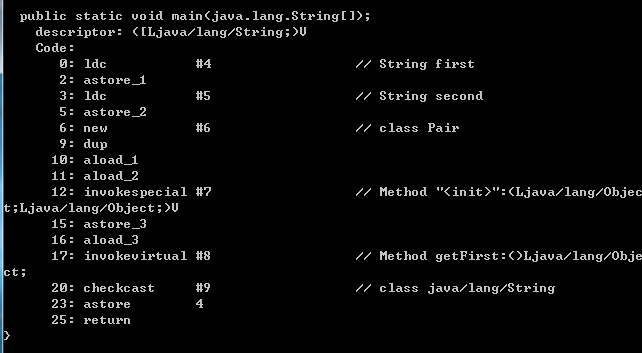
标着”17:"的那行,根据后面的注释,我们知道这是对getFirst方法的调用,可以看到他的返回类型的确是Object。标着“20:"的那行,是一个checkcast指令,字面上我们就可以知道这条指令的含义是检查类型转换是否成功,再看后面的注释,我们这里确实存在一个到String的强制类型转换。
#### 什么时候用泛型类呢?
当类中的操作的引用数据类型不确定的时候,以前用的Object来进行扩展的,现在可以用泛型来表示。这样可以避免强转的麻烦,而且将运行问题转移到的编译时期。
泛型在程序定义上的体现:
```java
//泛型类:将泛型定义在类上。
class Tool<Q> {
private Q obj;
public void setObject(Q obj) {
this.obj = obj;
}
public Q getObject() {
return obj;
}
}
//当方法操作的引用数据类型不确定的时候,可以将泛型定义在方法上。
public <W> void method(W w) {
System.out.println("method:"+w);
}
//静态方法上的泛型:静态方法无法访问类上定义的泛型。
//如果静态方法操作的引用数据类型不确定的时候,必须要将泛型定义在方法上。
public static <Q> void function(Q t) {
System.out.println("function:"+t);
}
//泛型接口.
interface Inter<T> {
void show(T t);
}
class InterImpl<R> implements Inter<R> {
public void show(R r) {
System.out.println("show:"+r);
}
}
```
`泛型中的通配符:`可以解决当具体类型不确定的时候,这个通配符就是 **?** ;当操作类型时,不需要使用类型的具体功能时,只使用Object类中的功能。那么可以用 ? 通配符来表未知类型。
#### 泛型限定:
`上限`:`?extends E`:可以接收E类型或者E的子类型对象。称为**通配符的子类型限定**
`下限`:`?super E`:可以接收E类型或者E的父类型对象。称为**通配符的超类型限定**
**上限什么时候用:**往集合中*添加元素*时,既可以添加E类型对象,又可以添加E的子类型对象。为什么?因为取的时候,E类型既可以接收E类对象,又可以接收E的子类型对象。
**下限什么时候用:**当从集合中*获取元素*进行操作的时候,可以用当前元素的类型接收,也可以用当前元素的父类型接收。
**不能有静态泛型变量**
a) 静态方法无法访问类上定义的泛型,如果静态方法操作的引用类型不确定时,必须要将泛型定义在静态方法上。
b) 不能构建泛型数组,只能构建object数组,再进行(E[])强制转换
c) 泛型类可以new,但是无法使用其方法
d) 不能抛出或者捕获泛型类对象,但是在异常规范中可以使用泛型变量
e) 泛型在指定类型后,可以存入其子类(ArrayList<father>中可以存入son)
`限定`:extends && super 可以有多个限定,限定类型用&分割,限定中最多只有一个类,且要放到限定的第一个
`?和T的区别`:?代表任意,T代表T这个类型,可以在类中使用此类型。T主要用于声明一个泛型类或者泛型方法,?主要用于使用泛型类或者泛型方法
? 声明的泛型中,不能写入,不能作为返回值
T 不支持 T super E这种,只能写 ? super E这种形式
介绍类型通配符前,首先介绍两点:
(1)假设Student是People的子类,Pair<Student, Student>却不是Pair<People, People>的子类,它们之间不存在"is-a"关系。
(2)Pair<T, T>与它的原始类型Pair之间存在”is-a"关系,Pair<T, T>在任何情况下都可以转换为Pair类型。
现在考虑这样一个方法:
```java
public static void printName(Pair<People, People> p) {
People p1 = p.getFirst();
System.out.println(p1.getName()); //假设People类定义了getName实例方法
}
```
在以上的方法中,我们想要同时能够传入Pair<Student, Student>和Pair<People, People>类型的参数,然而二者之间并不存在"is-a"关系。在这种情况下,Java提供给我们这样一种解决方案:使用Pair<? extends People>作为形参的类型。也就是说,Pair<Student, Student>和Pair<People, People>都可以看作是Pair<? extends People>的子类。
现在我们考虑下面这段代码:
```java
Pair<Student> students = new Pair<Student>(student1, student2);
Pair<? extends People> wildchards = students;
wildchards.setFirst(people1);
```
以上代码的第三行会报错,因为wildchards是一个Pair<? extends People>对象,它的setFirst方法和getFirst方法是这样的:
```java
void setFirst(? extends People)
? extends People getFirst()
```
对于setFirst方法来说,会使得编译器不知道形参究竟是什么类型(只知道是People的子类),而我们试图传入一个People对象,编译器无法判定People和形参类型是否是”is-a"的关系,所以调用setFirst方法会报错。而调用wildchards的getFirst方法是合法的,因为我们知道它会返回一个People的子类,而People的子类“always is a People”。(总是可以把子类对象转换为父类对象)
而对于通配符的超类型限定的情况下,调用getter方法是非法的,而调用setter方法是合法的。
除了子类型限定和超类型限定,还有一种通配符叫做无限定的通配符,它是这样的:<?>。这个东西我们什么时候会用到呢?考虑一下这个场景,我们调用一个会返回一个getPairs方法,这个方法会返回一组Pair<T, T>对象。其中既有Pair<Student, Student>, 还有Pair<Teacher, Teacher>对象。(Student类和Teacher类不存在继承关系)显然,这种情况下,子类型限定和超类型限定都不能用。这时我们可以用这样一条语句搞定它:
```java
Pair<?>[] pairs = getPairs(...);
```
对于无限定的通配符,调用getter方法和setter方法都是非法的。
PECS(Producer Extends Consumer Super)原则:
* 频繁往外读取内容的,适合用上界Extends(知道上界,取出来直接用父类执行取出的对象即可)
* 经常往里插入的,适合用下界Super(知道下界,那么存比下界小的元素都可以,往外取的时候只能存放到object对象中)
参考:
- http://www.ciaoshen.com/java/2016/08/21/superExtends.html
- http://www.ciaoshen.com/java/2016/08/21/wildcards.html
- http://www.cnblogs.com/absfree/p/5270883.html#undefined
### 3.25 枚举
使用关键字enum定义的枚举类型,在编译期后,也将转换成为一个实实在在的类(继承Enum类),而在该类中,会存在每个在枚举类型中定义好变量的对应实例对象,如上述的MONDAY枚举类型对应public static final Day MONDAY;,同时编译器会为该类创建两个方法,分别是values()和valueOf()。
- 1. **枚举不允许继承类。**Jvm在生成枚举时已经继承了Enum类,由于Java语言是单继承,不支持再继承额外的类(唯一的继承名额被Jvm用了)。
- 2. **枚举允许实现接口。**因为枚举本身就是一个类,类是可以实现多个接口的。
- 3. **枚举可以用等号比较。**Jvm会为每个枚举实例对应生成一个类对象,这个类对象是用public static final修饰的,在static代码块中初始化,是一个单例。
- 4. **不可以继承枚举。**因为Jvm在生成枚举类时,将它声明为final。
- 5. 枚举本身就是一种对**单例设计模式**友好的形式,它是实现单例模式的一种很好的方式。
- 6. 枚举类型的**compareTo()**方法比较的是枚举类对象的ordinal的值。
- 7. 枚举类型的**equals()**方法比较的是枚举类对象的内存地址,作用与等号等价。
```java
public enum EnumTest {
SUCESS("1","成功");
private String code;
private String desc;
EnumTest(String code, String desc) {
this.code = code;
this.desc = desc;
}
public String getCode(){
return code;
}
public String getDesc(){
return desc;
}
}
```
* 一定要把枚举变量的定义放在第一行,并且以分号结尾。
* 构造函数必须私有化。事实上,private是多余的,你完全没有必要写,因为它默认并强制是private,如果你要写,也只能写private,写public是不能通过编译的。
* 自定义变量与默认的ordinal属性并不冲突,ordinal还是按照它的规则给每个枚举变量按顺序赋值。
### 3.26 反射
>反射机制是在**运行状态**中,对于*任意一个类*,都能够知道这个类的所有*属性*和*方法*;对于*任意一个对象*,都能够调用它的任意一个*方法*和*属性*;这种**动态获取**的信息以及**动态调用**对象的方法的功能称为java语言的反射机制。
每一个类都有一个Class对象。Class对象是在类加载的时候由Java虚拟机以及通过调用类加载器中的 defineClass 方法自动构造的。hotspot虚拟机中class对象存在方法区中。
java源文件被编译成java字节码(class文件)时,会在这个字节码文件中加上一个Class对象。
类的class属性是Class类的实例,这个class对象的内容是类的信息
#### 3.26.1 反射机制中的类
* `java.lang.Class;` Class对象类
* `java.lang.reflect.Constructor;` 构造函数类
* `java.lang.reflect.Field;` 类属性类
* `java.lang.reflect.Method;` 方法类
* `java.lang.reflect.Modifier;` 修饰符类
#### 3.26.2 获取Class对象
* 调用某个对象的`getClass()`方法。
```java
Person p= new Person(); Class clazz=p.getClass();
```
* 调用某个类的`class属性`来获取该类对应的Class对象。
```java
Class clazz = Person.class;
```
* 使用Class类中的`forName()`静态方法。
```java
Class clazz = Class.forName(“类的全路径”)。
```
#### 3.26.3 获取属性&方法&构造函数
```java
Method[] method=clazz.getDeclaredMethods();
Field[] field=clazz.getDeclaredFields();
Constructor[] constructor=clazz.getDeclaredConstructors();
```
#### 3.26.4 创建对象
* 1. 使用 Class 对象的 `newInstance()`方法来创建该 Class 对象对应类的实例,但是这种方法要求该 Class 对象对应的类有**默认的空构造器**。
* 2. 先使用 Class 对象获取指定的 `Constructor对象`,再调用 Constructor 对象的 newInstance()方法来创建 Class 对象对应类的实例,通过这种方法可以选定构造方法创建实例。
```java
Constructor c=
clazz.getDeclaredConstructor(String.class,String.class,int.class);
Person p1=(Person) c.newInstance("李四","男",20);
```
#### 3.26.5 设置属性&调用方法
调用类方法:**invoke(Object obj, Object... args)**,obj是类对象,args是方法中的可变参数列表
```java
Class<?> clazz = Class.forName("net.xsoftlab.baike.TestReflect");
// 调用TestReflect类中的reflect1方法
Method method = clazz.getMethod("reflect1");
method.invoke(clazz.newInstance());
```
field.set(Object obj, Object value):**obj是对象实例,value是要设置的属性值**
```java
Class<?> clazz = Class.forName("net.xsoftlab.baike.TestReflect");
Object obj = clazz.newInstance();
// 可以直接对 private 的属性赋值
Field field = clazz.getDeclaredField("proprety");
field.setAccessible(true);
field.set(obj, "Java反射机制");
```
* `ClassforName(...)` 方法,除了将类的 `.class` 文件加载到JVM 中之外,还会对类进行解释,执行类中的 `static` 块。
* ClassLoader 只干一件事情,就是将 `.class` 文件加载到 JVM 中,不会执行 `static` 中的内容,只有在 newInstance 才会去执行 `static` 块。
#### 3.26.6 反射机制的优缺点:
**优点:**
1)能够运行时动态获取类的实例,提高灵活性;
2)与动态编译结合
Class.forName('com.mysql.jdbc.Driver.class');//加载MySQL的驱动类
**缺点:**
1)使用反射性能较低,需要解析字节码,将内存中的对象进行解析。
**解决方案:**
1、通过setAccessible(true)关闭JDK的安全检查来提升反射速度;
2、多次创建一个类的实例时,有缓存会快很多
3、ReflflectASM工具类,通过字节码生成的方式加快反射速度
2)相对不安全,破坏了封装性(因为通过反射可以获得私有方法和属性)
#### 3.26.7 反射使用步骤(获取 Class 对象、调用对象方法)
1. 获取想要操作的类的 Class 对象,他是反射的核心,通过 Class 对象我们可以任意调用类的方法。
2. 调用 Class 类中的方法,既就是反射的使用阶段。
3. 使用反射 API 来操作这些信息。
### 3.27 序列化
序列化就是将一个对象转换成字节序列,方便存储和传输。
* 序列化:`ObjectOutputStream.writeObject()`
* 反序列化:`ObjectInputStream.readObject()`
**不会对静态变量进行序列化**,*因为序列化只是保存对象的状态,静态变量属于类的状态。*
序列化的类需要实现 `Serializable 接口`,它只是一个标准,没有任何方法需要实现,但是如果不去实现它的话而进行序列化,会抛出异常。
`transient` 关键字可以使一些属性不会被序列化。
ArrayList 中存储数据的数组 elementData 是用 transient 修饰的,因为这个数组是动态扩展的,并不是所有的空间都被使用,因此就**不需要所有的内容都被序列化**。通过重写序列化和反序列化方法,使得可以只序列化数组中有内容的那部分数据。
```java
transient Object[] elementData;
//重写序列化方法
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
int expectedModCount = modCount;
s.defaultWriteObject();
s.writeInt(size);
for (int i=0; i<size; i++) {
s.writeObject(elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
}
//反序列化方法
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
s.readInt();
if (size > 0) {
SharedSecrets.getJavaObjectInputStreamAccess()
.checkArray(s, Object[].class, size);
Object[] elements = new Object[size];
for (int i = 0; i < size; i++) {
elements[i] = s.readObject();
}
elementData = elements;
} else if (size == 0) {
elementData = EMPTY_ELEMENTDATA;
} else {
throw new java.io.InvalidObjectException("Invalid size: " + size);
}
}
```
### 3.28 Object的方法
#### 概览
```java
public native int hashCode()
public boolean equals(Object obj)
protected native Object clone() throws CloneNotSupportedException
public String toString()
public final native Class<?> getClass()
protected void finalize() throws Throwable {}
public final native void notify()
public final native void notifyAll()
public final native void wait(long timeout) throws InterruptedException
public final void wait(long timeout, int nanos) throws InterruptedException
public final void wait() throws InterruptedException
```
#### equals
**1. 等价关系**
* `自反性`:x.equals(x); // true
* `对称性`:x.equals(y) == y.equals(x); // true
* `传递性`:if (x.equals(y) && y.equals(z)){ x.equals(z);} // true;
* `一致性`:多次调用结果不变。x.equals(y) == x.equals(y); // true
* `与null比较`:对任何不是 null 的对象 x 调用 x.equals(null) 结果都为 false
**2. 等价与相等**
默认的equals实现是 return == 比较两个对象是否为同一个对象
* 对于`基本类型`,== 判断两个值是否相等,基本类型没有 equals() 方法。
* 对于`引用类型`,== 判断两个变量是否引用同一个对象,而 equals() 判断引用的对象是否等价(需要自己重写)。
#### hashCode
- hashCode() 返回散列值,而 equals() 是用来判断两个对象是否等价。等价的两个对象散列值一定相同,但是散列值相同的两个对象不一定等价。
- 在覆盖 equals() 方法时应当总是覆盖 hashCode() 方法,保证等价的两个对象散列值也相等。
#### toString
默认返回 ToStringExample@4554617c 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示。
#### clone
clone() 是 Object 的 protected 方法,它不是 public,一个类不显式去重写 clone(),其它类就不能直接去调用该类实例的 clone() 方法。应该注意的是,clone() 方法并不是 Cloneable 接口的方法,而是 Object 的一个 protected 方法。Cloneable 接口只是规定,如果一个类没有实现 Cloneable 接口又调用了 clone() 方法,就会抛出 CloneNotSupportedException。
#### finalize
`final`用于声明属性,方法和类,分别表示**属性不可变,方法不可覆盖,类不可继承**。
`finally`是异常处理语句结构的一部分,表示总是执行。
`finalize`是Object类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源的回收,例如关闭文件等。垃圾收集器会先执行对象的finalize方法,但不保证会执行完毕(死循环或执行很缓慢的情况会被强行终止),此为第一次标记。第二次检查时,如果对象仍然不可达,才会执行回收
### 3.29 异常
java异常类层次结构
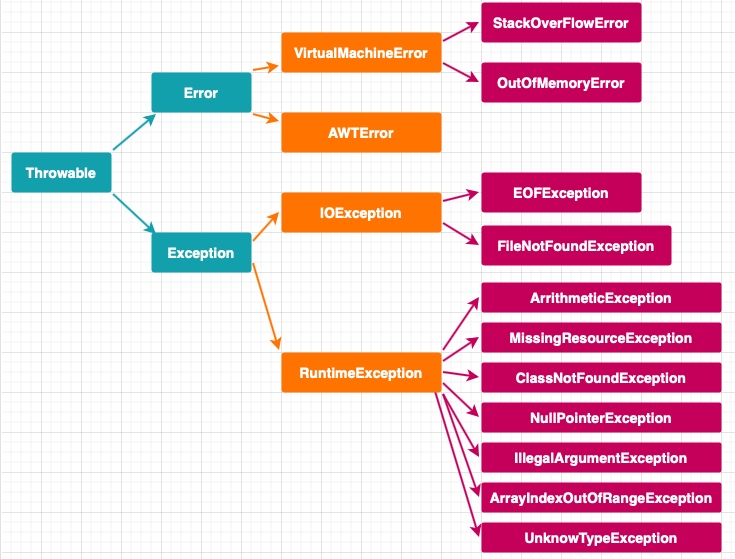
祖先java.lang包中的 **Throwable类**。Throwable: 有两个重要的子类:**Exception(异常)** 和 **Error(错误)** ,二者都是 Java 异常处理的重要子类,各自都包含大量子类。
**Error(错误):是程序无法处理的错误**,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java中,错误通过Error的子类描述。
**Exception(异常):是程序本身可以处理的异常**。Exception 类有一个重要的子类 **RuntimeException**。RuntimeException 异常由Java虚拟机抛出。**NullPointerException**(要访问的变量没有引用任何对象时,抛出该异常)、**ArithmeticException**(算术运算异常,一个整数除以0时,抛出该异常)和 **ArrayIndexOutOfBoundsException** (下标越界异常)。
**注意:异常和错误的区别:异常能被程序本身可以处理,错误是无法处理。**
throw是抛出具体的异常,throws是用于在方法上指定没有处理的异常。
#### try catch fifinally,try里有return,finally还执行么?
执行,并且finally的执行早于try里面的return
结论:
1、不管有木有出现异常,finally块中代码都会执行;
2、当try和catch中有return时,finally仍然会执行;
3、finally是在return后面的表达式运算后执行的(此时并没有返回运算后的值,而是先把要返回的值保存起来,管finally中的代码怎么样,
返回的值都不会改变,任然是之前保存的值),所以函数返回值是在finally执行前确定的;
4、finally中最好不要包含return,否则程序会提前退出,返回值不是try或catch中保存的返回值。
#### Thow与thorws区别
**位置不同**
1. throws 用在函数上,后面跟的是异常类,可以跟多个;而 throw 用在函数内,后面跟的
是异常对象。
**功能不同:**
1. throws 用来声明异常,让调用者只知道该功能可能出现的问题,可以给出预先的处理方
式;throw 抛出具体的问题对象,执行到 throw,功能就已经结束了,跳转到调用者,并
将具体的问题对象抛给调用者。也就是说 throw 语句独立存在时,下面不要定义其他语
句,因为执行不到。
2. throws 表示出现异常的一种可能性,并不一定会发生这些异常;throw 则是抛出了异常,
执行 throw 则一定抛出了某种异常对象。
3. 两者都是消极处理异常的方式,只是抛出或者可能抛出异常,但是不会由函数去处理异
常,真正的处理异常由函数的上层调用处理。