
  类型化数组(Typed Array)是一种处理二进制数据的特殊数组,它可像C语言那样直接操纵字节,不过得先用ArrayBuffer对象创建数组缓冲区(Array Buffer),再映射到指定格式的视图(view)之后,才能读写其中的数据。总共有两类视图,分别是特定类型的TypedArray和通用类型的DataView。在ES6引入类型化数组之后,大大提升了JavaScript数学运算的性能。
## 一、ArrayBuffer
  虽然ArrayBuffer对象可以开辟一片固定大小的内存区域(即数组缓冲区),但它不能直接读写所存储的数据,需要借助视图才行。通过构造函数ArrayBuffer()可以分配指定字节数量的缓冲区,如下代码所示,分配了一段8个字节的内存区域,每个字节的默认值都为0。有一点要注意,缓冲区的容量在指定后,就不可再修改。
~~~
var buffer = new ArrayBuffer(8);
~~~
  利用ArrayBuffer对象的只读属性byteLength,可以获取缓冲区的字节长度。而通过它的slice()方法可创建一个指定范围的缓冲区副本。还有一个静态方法ArrayBuffer.isView(),用来检测是否是一个视图实例,具体如下所示。
~~~
buffer.byteLength; //8
buffer.slice(2, 4);
ArrayBuffer.isView(buffer); //false
~~~
## 二、TypedArray
**1)数据类型**
  视图的行为类似于数组,但并不是真正的数组。视图可根据指定的数值类型解读缓冲区中的二进制数据,而TypedArray包含9种特定类型的视图(即类型化数组),如表8所示(引用自ES6规范的[22.2小节](https://www.ecma-international.org/ecma-262/6.0/#sec-typedarray-objects))。
:-: 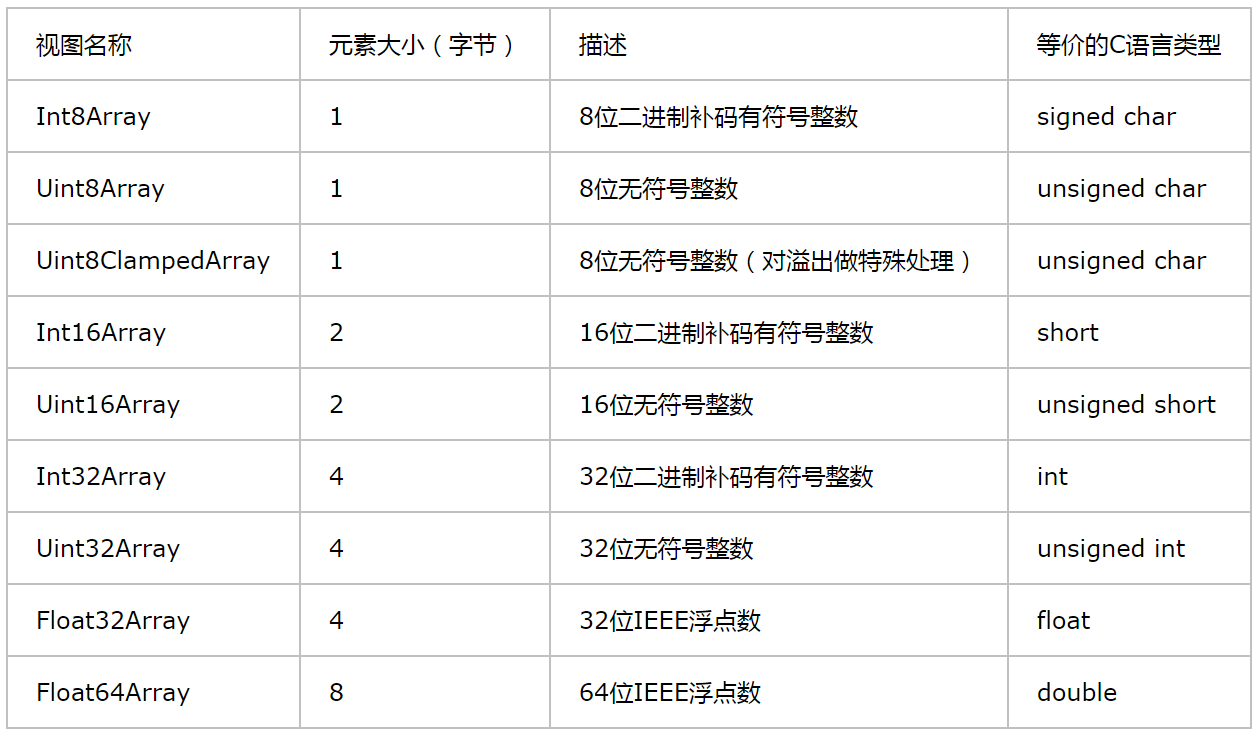
:-: 表8 九种特定类型的视图
  表中的9种视图都继承自TypedArray对象,而每种视图都只能处理一种数值类型的数据(例如Float32Array只能处理float类型的数值),并且视图中的元素大小(即所占的字节数)也与数值类型有关,例如Float32Array的1个元素包含4个字节。由于各个视图的元素都会有规定的数值范围,因此超出该范围就会溢出。其中对Uint8ClampedArray的溢出处理较为特殊,它的数值范围在0到255之间,如果缓冲区所存的值超出该范围,那么就会替换这个值,例如小于0的数值被转换成0,而大于255的数值则被转换成255,如下所示。
~~~
var view = new Uint8ClampedArray(2);
view[0] = -1;
view[1] = 256;
console.log(view); //Uint8ClampedArray(2) [0, 255]
~~~
**2)创建**
  每种特定类型的视图都有一个构造函数,每个构造函数都有4种参数的组合,即共有4种方式创建类型化数组,具体如下所列,每一种创建方式的后面都会给出相应的示例代码。
  (1)3个参数,第一个是数组缓冲区,第二个是可选的字节偏移量,第三个是可选的需要包含的元素个数。注意,偏移量需要是元素大小的倍数。
~~~
var buffer = new ArrayBuffer(16),
view1 = new Int16Array(buffer), //Int16Array(8) [0, 0, 0, 0, 0, 0, 0, 0]
view2 = new Int16Array(buffer, 4, 2); //Int16Array(2) [0, 0]
~~~
  利用这组参数,可以让一个缓冲区关联多个视图,如下代码所示。
~~~
var view1 = new Int8Array(buffer, 0, 4),
view2 = new Int16Array(buffer, 4, 4),
view3 = new Int32Array(buffer, 12, 1);
view1.buffer === view2.buffer; //true
view2.buffer === view3.buffer; //true
~~~
  三个视图分别占据了前4个字节、中间8个字节以及后4个字节的缓冲区。视图的buffer属性指向了它所处的缓冲区,两组全等比较的结果都为真,由此可知,它们使用了同一个缓冲区。
  (2)1个数值,表示类型化数组的元素个数,将该参数乘以每个元素的大小即可得到缓冲区的容量,前面描述Uint8ClampedArray特性的示例就用到了这种创建方式。注意,此时构造函数会自动创建合适容量的缓冲区。
~~~
var view = new Int16Array(7); //Int16Array(7) [0, 0, 0, 0, 0, 0, 0]
~~~
  (3)1个类型化数组,它的元素会被复制到新的类型化数组中,虽然元素个数保持不变,但使用了不同的缓冲区。
~~~
var view1 = new Int16Array(6),
view2 = new Int8Array(view1); //Int8Array(6) [0, 0, 0, 0, 0, 0]
~~~
  (4)1个对象,只要不是TypedArray或ArrayBuffer就行,例如数组、类数组等对象。
~~~
var view = new Int16Array([1, 2, 3]); //Int16Array(3) [1, 2, 3]
~~~
**3)与常规数组的异同**
  类型化数组与常规数组有许多相似点,下面仅列出其中的三点:
  (1)都可以通过数字类型的索引来访问某个位置的元素。
  (2)通过length属性可获取包含的元素个数。
  (3)都包含slice()、of()、from()、copyWithin()等数组方法。
  虽然两者之间的共性不少,但是类型化数组的特点又很鲜明,例如:
  (1)每种类型化数组都包含一个BYTES\_PER\_ELEMENT属性,能获取每个元素所占的字节(即元素大小),如下代码所示。
~~~
Int8Array.BYTES_PER_ELEMENT; //1
Int16Array.BYTES_PER_ELEMENT; //2
Int32Array.BYTES_PER_ELEMENT; //4
~~~
  (2)由于类型化数组无法维护自己的长度,因此将length属性定义为只读,并且缺少pop()、push()、shift()等会更改数组长度的方法。
  (3)包含独有的属性和方法,如表9所列。
:-: 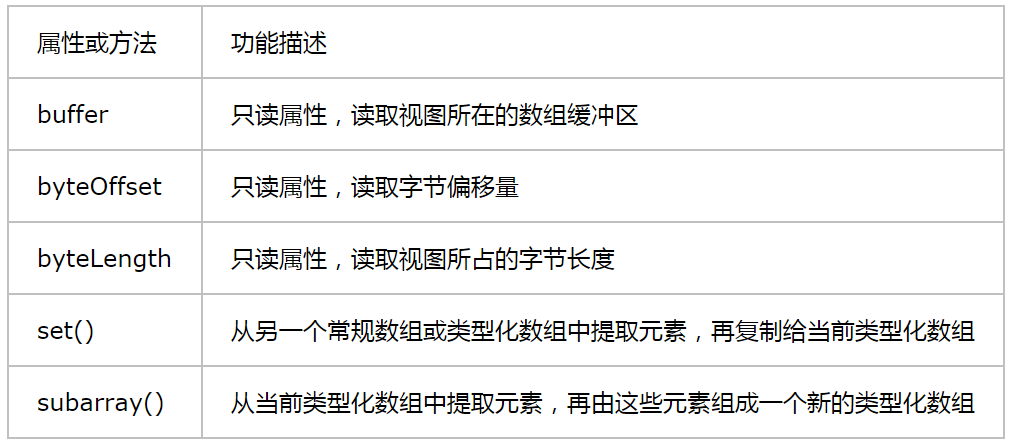
:-: 表9 类型化数组的属性和方法
  byteOffset属性等于构造函数的第二个参数,而byteLength属性等于构造函数的第三个参数与元素大小相乘的积,如下所示。
~~~
var buffer = new ArrayBuffer(8),
view = new Int16Array(buffer, 2, 3);
view.buffer; //ArrayBuffer(8) {}
view.byteOffset; //2
view.byteLength; //6
~~~
  set()方法可接收2个参数,第一个是被提取的常规数组或类型化数组,第二个是可选的参数,表示当前类型化数组的偏移量,即从这个位置开始覆盖它的元素。subarray()方法也能接收2个参数,但都是可选的索引参数,第一个是开始提取的位置,第二个是结束提取的位置,注意,该位置上的元素不会被提取。关于两个方法的使用,可参考下面的代码。
~~~
view.set([8], 1);
console.log(view); //Int16Array(3) [0, 8, 0]
view.subarray(1, 2); //Int16Array [8]
~~~
## 三、DataView
  DataView只有一个身份(即视图),而之前的类型化数组有双重身份,既是视图,也是类数组。如果要使用DataView视图,那么需要先创建数组缓冲区,类似于类型化数组的第一种创建方式,只不过它的构造函数中的第三个可选的参数换成需要包含的字节长度,如下代码所示。根据全等比较的结果可知,两个视图处在同一个缓冲区中。
~~~
var buffer = new ArrayBuffer(16),
view1 = new DataView(buffer),
view2 = new DataView(buffer, 4, 6);
view1.buffer === view2.buffer; //true
~~~
**1)写入和读取**
  想要通过DataView视图读写缓冲区的数据,需要先为其指定数据类型,而它支持8种数据类型(除了Uint8Clamped)。DataView提供了8对原型方法,每对方法分别以“set”和“get”作为名称前缀,前者用于写入,后者用于读取,在前缀的后面会跟着数据类型,例如setInt16()和getInt16()。
  写入方法的第一个参数是字节偏移量,第二个参数是要定义的数值。而读取方法的第一个参数也是字节偏移量,如下代码所示,两张视图被指定了不同的数据类型。
~~~
view1.setInt8(2, 8);
view1.getInt8(0); //0
view1.getInt8(2); //8
view2.setInt16(0, 16);
view2.getInt16(0); //16
view2.getInt16(2); //0
~~~
**2)小端序**
  除了Int8和Uint8类型,其它类型的写入和读取方法都还包含一个可选的布尔参数:littleEndian,表示是否启用小端序,默认为true。在了解小端序之前,需要先了解一下端序。端序又称字节序(Endianness),表示多字节中的字节排列方式。小端序是指字节的最低有效位在最高有效位之前(大端序正好与之相反),例如数字10,如果用16位二进制表示,那么它就变为0000 0000 0000 1010,换算成16进制就是000A,用小端序存储的话,该值会被表示成0A00。虽然大端序更符合人类的阅读习惯,但英特尔处理器和多数浏览器采用的都是小端序。引入该参数后,能更灵活的处理不同存储方式的数据。
*****
> 原文出处:
[博客园-ES6躬行记](https://www.cnblogs.com/strick/category/1372951.html)
[知乎专栏-ES6躬行记](https://zhuanlan.zhihu.com/pwes6)
已建立一个微信前端交流群,如要进群,请先加微信号freedom20180706或扫描下面的二维码,请求中需注明“看云加群”,在通过请求后就会把你拉进来。还搜集整理了一套[面试资料](https://github.com/pwstrick/daily),欢迎浏览。

推荐一款前端监控脚本:[shin-monitor](https://github.com/pwstrick/shin-monitor),不仅能监控前端的错误、通信、打印等行为,还能计算各类性能参数,包括 FMP、LCP、FP 等。
- ES6
- 1、let和const
- 2、扩展运算符和剩余参数
- 3、解构
- 4、模板字面量
- 5、对象字面量的扩展
- 6、Symbol
- 7、代码模块化
- 8、数字
- 9、字符串
- 10、正则表达式
- 11、对象
- 12、数组
- 13、类型化数组
- 14、函数
- 15、箭头函数和尾调用优化
- 16、Set
- 17、Map
- 18、迭代器
- 19、生成器
- 20、类
- 21、类的继承
- 22、Promise
- 23、Promise的静态方法和应用
- 24、代理和反射
- HTML
- 1、SVG
- 2、WebRTC基础实践
- 3、WebRTC视频通话
- 4、Web音视频基础
- CSS进阶
- 1、CSS基础拾遗
- 2、伪类和伪元素
- 3、CSS属性拾遗
- 4、浮动形状
- 5、渐变
- 6、滤镜
- 7、合成
- 8、裁剪和遮罩
- 9、网格布局
- 10、CSS方法论
- 11、管理后台响应式改造
- React
- 1、函数式编程
- 2、JSX
- 3、组件
- 4、生命周期
- 5、React和DOM
- 6、事件
- 7、表单
- 8、样式
- 9、组件通信
- 10、高阶组件
- 11、Redux基础
- 12、Redux中间件
- 13、React Router
- 14、测试框架
- 15、React Hooks
- 16、React源码分析
- 利器
- 1、npm
- 2、Babel
- 3、webpack基础
- 4、webpack进阶
- 5、Git
- 6、Fiddler
- 7、自制脚手架
- 8、VSCode插件研发
- 9、WebView中的页面调试方法
- Vue.js
- 1、数据绑定
- 2、指令
- 3、样式和表单
- 4、组件
- 5、组件通信
- 6、内容分发
- 7、渲染函数和JSX
- 8、Vue Router
- 9、Vuex
- TypeScript
- 1、数据类型
- 2、接口
- 3、类
- 4、泛型
- 5、类型兼容性
- 6、高级类型
- 7、命名空间
- 8、装饰器
- Node.js
- 1、Buffer、流和EventEmitter
- 2、文件系统和网络
- 3、命令行工具
- 4、自建前端监控系统
- 5、定时任务的调试
- 6、自制短链系统
- 7、定时任务的进化史
- 8、通用接口
- 9、微前端实践
- 10、接口日志查询
- 11、E2E测试
- 12、BFF
- 13、MySQL归档
- 14、压力测试
- 15、活动规则引擎
- 16、活动配置化
- 17、UmiJS版本升级
- 18、半吊子的可视化搭建系统
- 19、KOA源码分析(上)
- 20、KOA源码分析(下)
- 21、花10分钟入门Node.js
- 22、Node环境升级日志
- 23、Worker threads
- 24、低代码
- 25、Web自动化测试
- 26、接口拦截和页面回放实验
- 27、接口管理
- 28、Cypress自动化测试实践
- 29、基于Electron的开播助手
- Node.js精进
- 1、模块化
- 2、异步编程
- 3、流
- 4、事件触发器
- 5、HTTP
- 6、文件
- 7、日志
- 8、错误处理
- 9、性能监控(上)
- 10、性能监控(下)
- 11、Socket.IO
- 12、ElasticSearch
- 监控系统
- 1、SDK
- 2、存储和分析
- 3、性能监控
- 4、内存泄漏
- 5、小程序
- 6、较长的白屏时间
- 7、页面奔溃
- 8、shin-monitor源码分析
- 前端性能精进
- 1、优化方法论之测量
- 2、优化方法论之分析
- 3、浏览器之图像
- 4、浏览器之呈现
- 5、浏览器之JavaScript
- 6、网络
- 7、构建
- 前端体验优化
- 1、概述
- 2、基建
- 3、后端
- 4、数据
- Web优化
- 1、CSS优化
- 2、JavaScript优化
- 3、图像和网络
- 4、用户体验和工具
- 5、网站优化
- 6、优化闭环实践
- 数据结构与算法
- 1、链表
- 2、栈、队列、散列表和位运算
- 3、二叉树
- 4、二分查找
- 5、回溯算法
- 6、贪心算法
- 7、分治算法
- 8、动态规划
- 程序员之路
- 大学
- 2011年
- 2012年
- 2013年
- 2014年
- 项目反思
- 前端基础学习分享
- 2015年
- 再一次项目反思
- 然并卵
- PC网站CSS分享
- 2016年
- 制造自己的榫卯
- PrimusUI
- 2017年
- 工匠精神
- 2018年
- 2019年
- 前端学习之路分享
- 2020年
- 2021年
- 2022年
- 日志
- 2020