
  在网络工程中,路由能保证信息从源地址传输到正确地目的地址,避免在互联网中迷失方向。而前端应用中的路由,其功能与之类似,也是保证信息的准确性,只不过来源变成URL,目的地变成HTML页面。
  在传统的前端应用中,每个HTML页面都会对应一条URL地址,当访问某个页面时,会先请求服务器,然后服务器根据发送过来的URL做出处理,再把响应内容回传给浏览器,最终渲染整个页面。这是典型的多页面应用的访问过程,由服务器控制页面的路由,而其中最令人诟病的是整页刷新,不仅存在着资源的浪费(像导航栏、侧边栏等通用部分不需要每次加载),并且让用户体验也变得不再流畅。
  为了弥补多页面应用的不足,有人提出了另一种网站模型:单页面应用(Single Page Application,简称SPA)。SPA类似于一个桌面应用程序,能根据URL分配控制器(即由JavaScript负责路由),动态加载适当的内容到页面中,减少与服务器之间的通信次数,不再因为页面切换而打断用户体验。虽然名称中包含“单页”两字,但浏览器中的URL地址还是会发生改变,在视觉上与多页面保持同步。而实现SPA的关键就是路由系统,在React的技术栈中,官方给出了支持的路由库:React Router,后文将会着重分析该库。
  当然,SPA也存在着自身的缺陷,例如不利于SEO、增加开发成本等,使用与否还是得看具体项目。
## 一、版本
  在2015年的11月,官方发布了React Router的第一个版本,实现了声明式的路由。随后在2016年,主版本号进行了两次升级,一次是在2月的v2;另一次是在10月的v3。v3能够兼容v2,删除了一些会引起警告的弃用代码,在未来只修复错误,所有的新功能都被添加到了2017年3月发布的v4版本中。
  v4不能兼容v3,在内部完全重写,推崇组件式应用开发,放弃了之前的静态路由而改成动态路由的设计思路。所谓静态路由是指事先定义好一堆路由配置,在应用启动时,再将其加载,从而构建出一张路由表,记录URL和组件之间的映射关系。虽然v4版本精简了许多API,降低了学习成本,但是增加了项目升级的难度。
  目前最新的版本已到v5,但官方团队本来只是想发布v4.4版本。由于人为的操作失误,导致不得不撤销v4.4,直接改成v5,因此其API能完全兼容v4.x版本。React Router被拆分成了4个库(包),如表3所列。
:-: 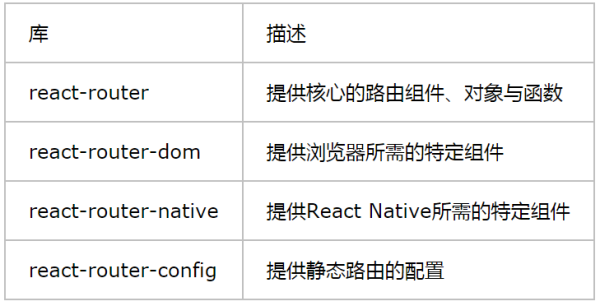
:-: 表3 React Router的四个库
  当运行在浏览器环境中时,只需要安装react-router-dom即可。因为react-router-dom会依赖react-router,所以默认就能使用react-router提供的API。
  v5版本的React Router提供了三大类组件:路由器、路由和导航,将它们组合起来就能实现一套完整的路由系统,如图11所示。首先根据URL导航到路由器中相应的路由,然后再渲染出指定的组件。
:-: 
图11 路由系统
## 二、路由器
  Router是React Router提供的基础路由器组件,一般不会直接使用。在浏览器运行环境中,通常引用的是封装了Router的高级路由器组件:BrowserRouter或HashRouter。以BrowserRouter为例,其部分源码如下所示。
~~~
class BrowserRouter extends React.Component {
history = createBrowserHistory(this.props);
render() {
return <Router history={this.history} children={this.props.children} />;
}
}
~~~
  在v4.x的版本中,路由器组件可以包裹任意类型的子元素,但数量只能是一个,而在v5.0版本中已经解除了这个限制。下面的BrowserRouter组件包含了两个子元素,如果将其执行于v4.x中,那么将抛出错误。
~~~
<BrowserRouter>
<div>1</div>
<div>2</div>
</BrowserRouter>
~~~
**1)history**
  每个路由器组件都会创建一个history对象,由它来管理会话历史。history不但会监听URL的变化,还能将其解析成location对象,触发路由的匹配和相应组件的渲染。
  history有三种形式,各自对应一种创建函数,应用于不同的路由器组件,具体如表4所示。其中MemoryRouter适用于非浏览器环境,例如React Native。
:-: 
:-: 表4 history的三种形式
  history会将浏览过的页面组织成有序的堆栈,无论使用哪种history,其属性和方法大部分都能保持一致。表5列出了history通用的API。
:-: 
:-: 表5 history的属性和方法
~~~
{
key: "z4ihbf", //唯一标识
pathname: "/libs/d.html" //路径和文件名
search: "?page=1", //查询字符串
hash: "#form", //锚点
state: { //状态对象
count: 10
}
}
~~~
**2)BrowserRouter**
  此组件会通过HTML5提供的History来保持页面和URL的同步,其创建的URL格式如下所示。
~~~
http://pwstrick.com/page.html
~~~
  如果使用BrowserRouter组件,那么需要服务器配合部署。以上面的URL为例,当页面刷新时,浏览器会向服务器请求根目录下的page.html,但根本就没有这个文件,于是页面就会报404的错误。若要避免这种情况,就需要配置Web服务器软件(例如Nginx、自建的Node服务器等),具体参数的配置可参考网上的资料。
  BrowserRouter组件包含5个属性,接下来将一一讲解。
  (1)basename属性用于设置根目录,URL的首部需要一个斜杠,而尾部则省略,例如“/pwstrick”,如下所示。
~~~
<BrowserRouter basename="/pwstrick" />
<Link to="/article" /> //渲染为<a href="/pwstrick/article">
~~~
  (2)forceRefresh是一个布尔属性,只有当浏览器不支持HTML5的History时,才会设为true,从而可刷新整个页面。
  (3)keyLength属性是一个数字,表示location.key的长度。
  (4)children属性保存着组件的子元素,这是所有的React组件都自带的属性。
  (5)getConfirmation属性是一个确认函数,可拦截Prompt组件,注入自定义逻辑。以下面代码为例,  当点击链接企图离开当前页面时,会执行action()函数,弹出里面的确认框,其提示就是Prompt组件message属性的值,只有点击确定后才能进行跳转(即导航)。
~~~
const action = (message, callback) => {
const allowTransition = window.confirm(message);
callback(allowTransition);
}
<BrowserRouter getUserConfirmation={action}>
<div>
<Prompt message="确认要离开吗?" />
<Link to="page.html">首页</Link>
</div>
</BrowserRouter>
~~~
**3)HashRouter**
  此组件会通过window.location.hash来保持页面和URL的同步,其创建的URL格式比较特殊,需要包含井号(#),如下所示。
~~~
http://pwstrick.com/#/page.html
~~~
  在使用HashRouter时,不需要配置服务器。因为服务器会忽略锚点(即#/page.html),只会处理锚点之前的部分,所以刷新上面的URL也不会报404的错误。
  HashRouter组件包含4个属性,其中3个与BrowserRouter组件相同,分别是basename、children和getUserConfirmation。独有的hashType属性用来设置hash类型,有三个关键字可供选择,如下所列。
  (1)slash:默认值,井号后面跟一个斜杠,例如“#/page”。
  (2)noslash:井号后面没有斜杠,例如“#page”。
  (3)hashbang:采用Google风格,井号后面跟感叹号和斜杠,例如“#!/page”。
## 三、路由
  Route是一个配置路由信息的组件,其职责是当页面的URL能匹配Route组件的path属性时,就渲染出对应的组件,而渲染方式有三种。接下来会讲解Route组件的属性、渲染方式以及其它的相关概念。
**1)路径**
  与路径相关的属性有3个,分别是path、exact和strict,接下来会一一讲解。
  (1)path是一个记录路由匹配路径的属性,当路由器是BrowserRouter时,path会匹配location中的pathname属性;而当路由器是HashRouter时,path会匹配location中的hash属性。
  path属性的值既可以是普通字符串,也可以是能被path-to-regexp解析的正则表达式。下面是一个示例,如果没有特殊说明,默认使用的路由器是BrowserRouter。
~~~
<Route path="/main" component={Main} />
<Route path="/list/:page+" component={List} />
~~~
  第一个Route组件能匹配“/main”或以“/main”为前缀的pathname属性,下面两条URL能正确匹配。
~~~
http://www.pwstrick.com/main
http://www.pwstrick.com/main/article
~~~
  第二个Route组件能匹配以“/list”为前缀的pathname属性,下面两条URL只能匹配第二条。
~~~
http://www.pwstrick.com/list
http://www.pwstrick.com/list/1
~~~
  React Router内部依赖了path-to-regexp库,此库定义了一套正则语法,例如命名参数、修饰符(\*、+或?)等,具体规则可参考[官方文档](https://github.com/pillarjs/path-to-regexp),本文不做展开。
  在“/list/:page+”中,带冒号前缀的“:page”是命名参数,类似于一个函数的形参,可以传递任何值;正则末尾的加号要求至少匹配一个命名参数,没有命名参数就匹配失败。
  注意,如果省略path属性,那么路由将总是匹配成功。
  (2)exact是一个布尔属性,当设为true时,路径要与pathname属性完全匹配,如表6所示。
:-: 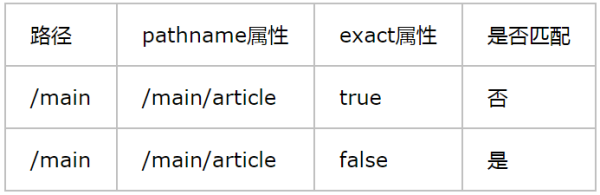
:-: 表6 exact属性匹配说明
  (3)strict也是一个布尔属性,当设为true时,路径末尾如果有斜杠,那么pathname属性匹配到的部分也得包含斜杠。在表7的第三行中,虽然pathname属性的末尾没有斜杠,但是依然能正确匹配。
:-: 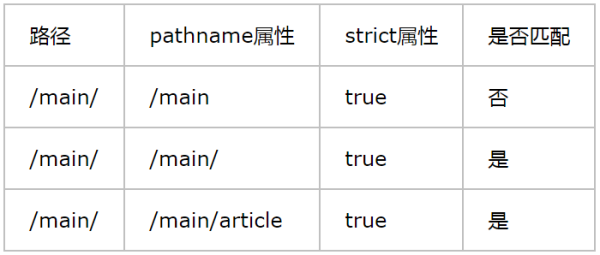
:-: 表7 strict属性匹配说明
  如果将strict和exact同时设为true,那么就可强制pathname属性的末尾不能包含斜杠。例如pathname属性的值为“/main/”,路径为“/main”,此时匹配会失败。
**2)渲染方式**
  Route组件提供了3个用来渲染组件的属性:component、render和children,每个属性对应一种渲染方式,每种方式传递的props都会包含3个路由属性:match、location和history。
  (1)component属性的值是一个组件(如下代码所示),当路由匹配成功时,会创建一个新的React元素(调用了React.createElement()方法)。
~~~
<Route path="/name" component={Name} />
~~~
  如果组件以内联函数的方式传给component属性,那么会产生不必要的重新挂载。对于内联渲染,可以用render属性替换。
  (2)render属性的值是一个返回React元素的内联函数,当路由匹配成功时,会调用这个函数,此时可以传递额外的参数进来,如下代码所示。由于React元素不会被反复创建,因此不会出现重新挂载的情况。
~~~
<Route path="/name" render={(props) => {
return <Name {...props} age="30">Strick</Name>
}}/>
~~~
  (3)children属性的值也是一个返回React元素的内联函数,它的一大特点是无论路由是否匹配成功,这个函数都会被调用,该属性的工作方式与render属性基本一致。注意,当匹配不成功时,props的match属性的值为null。
  不要将3个渲染属性应用于同一个Route组件,因为三种渲染方式有先后顺序,component的优先级最高,其次是render,最后是children。
  三个路由属性除了match之外,另外两个location和history已在前文做过讲解,接下来将重点分析match属性。
  Route会将路由匹配后的信息记录到match对象中,然后将此对象作为props的match属性传递给被渲染的组件。match对象包含4个属性,在表8中,不仅描述了各个属性的作用,还在第三列记录了点击read链接后,各个属性被赋的值。
~~~
<Link to="/list/article/1">read</Link>
<Route path="/list/:type" component={Name} />
~~~
:-: 
:-: 表8 match对象的属性
**3)Switch**
  如果将一堆Route组件放在一起(如下代码所示),那么会对每个Route组件依次进行路由匹配,例如当前pathname的属性值是“/age”,那么被渲染的组件是Age1和Age3。
~~~
<Route path='/' component={Age1} />
<Route path='/article' component={Age2} />
<Route path='/:list' component={Age3} />
~~~
  而如果将这三个Route用Switch组件包裹(如下代码所示),那么只会对第一个路径匹配的组件进行渲染。
~~~
<Switch>
<Route path='/' component={Age1} />
<Route path='/article' component={Age2} />
<Route path='/:list' component={Age3} />
</Switch>
~~~
  Switch的子元素既可以是Route,也可以是Redirect。其中Route元素匹配的是path属性,而Redirect元素匹配的是from属性。
**4)嵌套路由**
  从v4版本开始,嵌套路由不再通过多个Route组件相互嵌套实现,而是在被渲染的组件中声明另外的Route组件,以这种方式实现嵌套路由。下面用一个例子来演示嵌套路由,首先用Switch组件包裹两个Route组件,第一个只有当处在根目录时才会渲染Main组件,第二个路径匹配成功渲染的是Children组件。
~~~
<Switch>
<Route exact path='/' component={Main} />
<Route path='/list/:article' component={Children} />
</Switch>
~~~
  然后定义Children组件,它也包含一个Route组件,从而形成了嵌套路由。注意,其路径读取了match对象的path属性,通过沿用父路由中要匹配的路径,可减少许多重复代码。
~~~
let Children = (props) => {
return <Route path={`${props.match.path}/:id`} component={Article} />;
};
let Article = (props) => {
return <h5>文章内容</h5>;
};
~~~
  当pathname的属性值是“/list/article/1”时,就能成功渲染出Article组件。
## 四、导航
  当需要在页面之间进行切换时,就该轮到Link、NavLink和Redirect三个导航组件登场了。其中Link和NavLink组件最终会被解析成HTML中的元素。
**1)Link**
  当点击Link组件时会渲染匹配路由中的组件,并且能在更新URL时,不重载页面。它有两个属性:to和replace,其中to属性用于定义导航地址,其值的类型既可以是字符串,也可以是location对象(包含pathname、search等属性),如下所示。
~~~
<Link to="/main">字符串</Link>
<Link to={{pathname: "/main", search: "?type=1"}}>对象</Link>
~~~
  replace是一个布尔属性,默认值为false,当设为true时,能用新地址替换掉会话历史里的原地址。
**2)NavLink**
  它是一个封装了的Link组件,其功能包括定义路径匹配成功后的样式、限制匹配规则、优化无障碍阅读等,接下来将依次讲解多出的属性。
  首先是activeClassName和activeStyle,两个属性都会在路径匹配成功时,赋予元素样式(如下代码所示)。其中前者定义的是CSS类,默认值为“active”;后者定义的是内联样式,书写规则可参照React元素的style属性。
~~~
<style>
.btn {
color: blue;
}
</style>
<NavLink to="/list" activeClassName="btn">CSS类</NavLink>
<NavLink to="/list" activeStyle={{color: "blue"}}>内联样式</NavLink>
~~~
  然后是exact和strict,两个布尔属性的功能可分别参考Route元素的exact和strict,它们的用法相同。如果将exact和strict设为true(如下代码所示),那么匹配规则会改变,其中前者要路径完全匹配,后者得符合strict的路径匹配规则。只有当匹配成功时,才能将activeClassName或activeStyle属性的值赋予元素。
~~~
<NavLink to="/list" exact>完全</NavLink>
<NavLink to="/list" strict>斜杠</NavLink>
~~~
  接着是函数类型的isActive属性,此函数能接收2个对象参数:match和location,返回一个布尔值。在函数体中可添加路径匹配时的额外逻辑,当返回值是true时,才能赋予元素定义的匹配样式。注意,无论匹配是否成功,isActive属性中的函数都会被回调一次,因此如果要使用match参数,那么需要做空值判断(如下代码所示),以免出错。
~~~
let fn = (match, location) => {
if (!match) {
return false
}
return match.url.indexOf("article") >= 0;
};
<NavLink to="/list" isActive={fn}>函数</NavLink>
~~~
  最后是两个特殊功能的属性:location和aria-current,前者是一个用于比对的location对象;后者是一个为存在视觉障碍的用户服务的ARIA属性,用于标记屏幕阅读器可识别的导航类型,例如页面、日期、位置等。可供选择的关键字包括page、step、location、date、time和true,默认值为page。
**3)Redirect**
  此组件用于导航到一个新地址,类似于服务端的重定向(HTTP的状态码为3XX),其属性如表9所示。
:-: 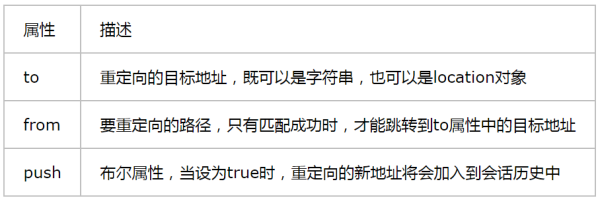
:-: 表9 Redirect元素的属性
  Redirect可与Switch搭配使用,如下代码所示,当URL与“/main”匹配时,重定向到“/page”,并渲染Page组件。
~~~
<Switch>
<Redirect from="/main" to="/page" />
<Route path="/page" component={Page} />
</Switch>
~~~
## 五、集成Redux
   [第11篇](https://www.cnblogs.com/strick/p/10775503.html)中对Redux做过详细讲解,本节将通过一个示例分三步来描述React Router集成Redux的过程,第一步是创建Redux的三个组成部分:Action、Reducer和Store,如下所示。
~~~
function caculate(previousState = {digit: 0}, action) { //Reducer
let state = Object.assign({}, previousState);
switch (action.type) {
case "ADD":
state.digit += 1;
break;
case "MINUS":
state.digit -= 1;
}
return state;
}
function add() { //Action创建函数
return {type: "ADD"};
}
let store = createStore(caculate); //Store
~~~
**1)withRouter**
  在说明第二步之前,需要先了解一下React Router提供的一个高阶组件:withRouter。它能将history、location和match三个路由对象传递给被包装的组件,其中match对象来自于离它最近的父级Route组件的match属性。
  正常情况下,只有Route要渲染的组件(例如下面的List)会自带这三个对象,但如果List组件还有一个子组件,那么这个子组件就无法自动获取到这三个对象了,除非显式地传递。
~~~
<Route path="/" component={List} />
~~~
  在使用withRouter后,就能避免逐级传递。并且当把withRouter应用于react-redux库中的connect()函数后(如下代码所示),就能让函数返回的容器组件监听到路由的变化。
~~~
withRouter(connect(...)(MyComponent))
~~~
**2)路由**
  第二步就是创建路由,并自定义三个组件:Btn、List和Article。在Btn组件中声明了Link和Route两个组件,其中路由匹配成功后会渲染List组件;在List组件中声明了WithArticle组件,而WithArticle就是通过withRouter包装后的Article组件。
~~~
class Btn extends React.Component {
render() {
return (
<div>
<Link to="/list">列表</Link>
<Route path="/list" component={List} />
<button onClick={this.props.add}>提交</button>
</div>
);
}
}
let List = (props) => {
return <WithArticle content="内容"/>;
};
let Article = (props) => {
const { match, location, history } = props;
return <h5>{props.content}</h5>;
};
let WithArticle = withRouter(Article); //withRouter包装后的Article组件
~~~
**3)渲染**
  第三步就是用react-redux库中的Provider组件包裹BrowserRouter组件(即连接路由器),并注入Store,最后将众组件渲染到页面中。
~~~
let Smart = connect(state => state, { add })(Btn); //容器组件
let Router = <Provider store={store}>
<BrowserRouter>
<Smart />
</BrowserRouter>
</Provider>;
ReactDOM.render(Router, document.getElementById("container"));
~~~
*****
> 原文出处:
[博客园-React躬行记](https://www.cnblogs.com/strick/category/1455720.html)
[知乎专栏-React躬行记](https://zhuanlan.zhihu.com/pwreact)
已建立一个微信前端交流群,如要进群,请先加微信号freedom20180706或扫描下面的二维码,请求中需注明“看云加群”,在通过请求后就会把你拉进来。还搜集整理了一套[面试资料](https://github.com/pwstrick/daily),欢迎浏览。

推荐一款前端监控脚本:[shin-monitor](https://github.com/pwstrick/shin-monitor),不仅能监控前端的错误、通信、打印等行为,还能计算各类性能参数,包括 FMP、LCP、FP 等。
- ES6
- 1、let和const
- 2、扩展运算符和剩余参数
- 3、解构
- 4、模板字面量
- 5、对象字面量的扩展
- 6、Symbol
- 7、代码模块化
- 8、数字
- 9、字符串
- 10、正则表达式
- 11、对象
- 12、数组
- 13、类型化数组
- 14、函数
- 15、箭头函数和尾调用优化
- 16、Set
- 17、Map
- 18、迭代器
- 19、生成器
- 20、类
- 21、类的继承
- 22、Promise
- 23、Promise的静态方法和应用
- 24、代理和反射
- HTML
- 1、SVG
- 2、WebRTC基础实践
- 3、WebRTC视频通话
- 4、Web音视频基础
- CSS进阶
- 1、CSS基础拾遗
- 2、伪类和伪元素
- 3、CSS属性拾遗
- 4、浮动形状
- 5、渐变
- 6、滤镜
- 7、合成
- 8、裁剪和遮罩
- 9、网格布局
- 10、CSS方法论
- 11、管理后台响应式改造
- React
- 1、函数式编程
- 2、JSX
- 3、组件
- 4、生命周期
- 5、React和DOM
- 6、事件
- 7、表单
- 8、样式
- 9、组件通信
- 10、高阶组件
- 11、Redux基础
- 12、Redux中间件
- 13、React Router
- 14、测试框架
- 15、React Hooks
- 16、React源码分析
- 利器
- 1、npm
- 2、Babel
- 3、webpack基础
- 4、webpack进阶
- 5、Git
- 6、Fiddler
- 7、自制脚手架
- 8、VSCode插件研发
- 9、WebView中的页面调试方法
- Vue.js
- 1、数据绑定
- 2、指令
- 3、样式和表单
- 4、组件
- 5、组件通信
- 6、内容分发
- 7、渲染函数和JSX
- 8、Vue Router
- 9、Vuex
- TypeScript
- 1、数据类型
- 2、接口
- 3、类
- 4、泛型
- 5、类型兼容性
- 6、高级类型
- 7、命名空间
- 8、装饰器
- Node.js
- 1、Buffer、流和EventEmitter
- 2、文件系统和网络
- 3、命令行工具
- 4、自建前端监控系统
- 5、定时任务的调试
- 6、自制短链系统
- 7、定时任务的进化史
- 8、通用接口
- 9、微前端实践
- 10、接口日志查询
- 11、E2E测试
- 12、BFF
- 13、MySQL归档
- 14、压力测试
- 15、活动规则引擎
- 16、活动配置化
- 17、UmiJS版本升级
- 18、半吊子的可视化搭建系统
- 19、KOA源码分析(上)
- 20、KOA源码分析(下)
- 21、花10分钟入门Node.js
- 22、Node环境升级日志
- 23、Worker threads
- 24、低代码
- 25、Web自动化测试
- 26、接口拦截和页面回放实验
- 27、接口管理
- 28、Cypress自动化测试实践
- 29、基于Electron的开播助手
- Node.js精进
- 1、模块化
- 2、异步编程
- 3、流
- 4、事件触发器
- 5、HTTP
- 6、文件
- 7、日志
- 8、错误处理
- 9、性能监控(上)
- 10、性能监控(下)
- 11、Socket.IO
- 12、ElasticSearch
- 监控系统
- 1、SDK
- 2、存储和分析
- 3、性能监控
- 4、内存泄漏
- 5、小程序
- 6、较长的白屏时间
- 7、页面奔溃
- 8、shin-monitor源码分析
- 前端性能精进
- 1、优化方法论之测量
- 2、优化方法论之分析
- 3、浏览器之图像
- 4、浏览器之呈现
- 5、浏览器之JavaScript
- 6、网络
- 7、构建
- 前端体验优化
- 1、概述
- 2、基建
- 3、后端
- 4、数据
- Web优化
- 1、CSS优化
- 2、JavaScript优化
- 3、图像和网络
- 4、用户体验和工具
- 5、网站优化
- 6、优化闭环实践
- 数据结构与算法
- 1、链表
- 2、栈、队列、散列表和位运算
- 3、二叉树
- 4、二分查找
- 5、回溯算法
- 6、贪心算法
- 7、分治算法
- 8、动态规划
- 程序员之路
- 大学
- 2011年
- 2012年
- 2013年
- 2014年
- 项目反思
- 前端基础学习分享
- 2015年
- 再一次项目反思
- 然并卵
- PC网站CSS分享
- 2016年
- 制造自己的榫卯
- PrimusUI
- 2017年
- 工匠精神
- 2018年
- 2019年
- 前端学习之路分享
- 2020年
- 2021年
- 2022年
- 日志
- 2020