
# 7.2.1 Android XML数据解析
## 本节引言:
> 前面两节我们对Android内置的Http请求方式:HttpURLConnection和HttpClient,本来以为OkHttp 已经集成进来了,然后想讲解下Okhttp的基本用法,后来发现还是要导第三方,算了,放到进阶部分 吧,而本节我们来学习下Android为我们提供的三种解析XML数据的方案!他们分别是: SAX,DOM,PULL三种解析方式,下面我们就来对他们进行学习!
## 1.XML数据要点介绍
首先我们来看看XML数据的一些要求以及概念:
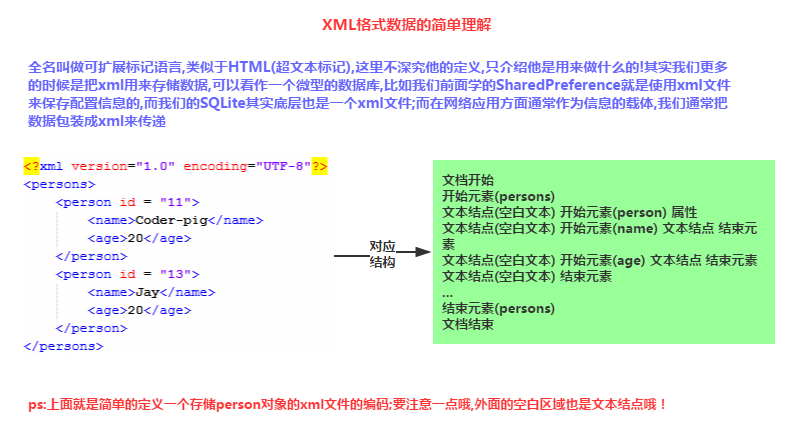
## 2.三种解析XML方法的比较

## 3.SAX解析XML数据

**核心代码**:
SAX解析类:**SaxHelper.java**:
```
/**
* Created by Jay on 2015/9/8 0008.
*/
public class SaxHelper extends DefaultHandler {
private Person person;
private ArrayList<Person> persons;
//当前解析的元素标签
private String tagName = null;
/**
* 当读取到文档开始标志是触发,通常在这里完成一些初始化操作
*/
@Override
public void startDocument() throws SAXException {
this.persons = new ArrayList<Person>();
Log.i("SAX", "读取到文档头,开始解析xml");
}
/**
* 读到一个开始标签时调用,第二个参数为标签名,最后一个参数为属性数组
*/
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
if (localName.equals("person")) {
person = new Person();
person.setId(Integer.parseInt(attributes.getValue("id")));
Log.i("SAX", "开始处理person元素~");
}
this.tagName = localName;
}
/**
* 读到到内容,第一个参数为字符串内容,后面依次为起始位置与长度
*/
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
//判断当前标签是否有效
if (this.tagName != null) {
String data = new String(ch, start, length);
//读取标签中的内容
if (this.tagName.equals("name")) {
this.person.setName(data);
Log.i("SAX", "处理name元素内容");
} else if (this.tagName.equals("age")) {
this.person.setAge(Integer.parseInt(data));
Log.i("SAX", "处理age元素内容");
}
}
}
/**
* 处理元素结束时触发,这里将对象添加到结合中
*/
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if (localName.equals("person")) {
this.persons.add(person);
person = null;
Log.i("SAX", "处理person元素结束~");
}
this.tagName = null;
}
/**
* 读取到文档结尾时触发,
*/
@Override
public void endDocument() throws SAXException {
super.endDocument();
Log.i("SAX", "读取到文档尾,xml解析结束");
}
//获取persons集合
public ArrayList<Person> getPersons() {
return persons;
}
}
```
然后我们在MainActivity.java中写上写上这样一个方法,然后要解析XML的时候调用下 就好了~
```
private ArrayList<Person> readxmlForSAX() throws Exception {
//获取文件资源建立输入流对象
InputStream is = getAssets().open("person1.xml");
//①创建XML解析处理器
SaxHelper ss = new SaxHelper();
//②得到SAX解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
//③创建SAX解析器
SAXParser parser = factory.newSAXParser();
//④将xml解析处理器分配给解析器,对文档进行解析,将事件发送给处理器
parser.parse(is, ss);
is.close();
return ss.getPersons();
}
```
**一些其他的话**:
嗯,对了,忘记给大家说下我们是定义下面这样一个person1.xml文件,然后放到assets目录下的! 文件内容如下:**person1.xml**
```
<?xml version="1.0" encoding="UTF-8"?>
<persons>
<person id = "11">
<name>SAX解析</name>
<age>18</age>
</person>
<person id = "13">
<name>XML1</name>
<age>43</age>
</person>
</persons>
```
我们是把三种解析方式都糅合到一个demo中,所以最后才贴全部的效果图,这里的话,贴下打印的Log, 相信大家会对SAX解析XML流程更加明了:

另外,外面的空白文本也是文本节点哦!解析的时候也会走这些节点!
## 4.DOM解析XML数据

**核心代码**:
**DomHelper.java**
```
/**
* Created by Jay on 2015/9/8 0008.
*/
public class DomHelper {
public static ArrayList<Person> queryXML(Context context)
{
ArrayList<Person> Persons = new ArrayList<Person>();
try {
//①获得DOM解析器的工厂示例:
DocumentBuilderFactory dbFactory = DocumentBuilderFactory.newInstance();
//②从Dom工厂中获得dom解析器
DocumentBuilder dbBuilder = dbFactory.newDocumentBuilder();
//③把要解析的xml文件读入Dom解析器
Document doc = dbBuilder.parse(context.getAssets().open("person2.xml"));
System.out.println("处理该文档的DomImplemention对象=" + doc.getImplementation());
//④得到文档中名称为person的元素的结点列表
NodeList nList = doc.getElementsByTagName("person");
//⑤遍历该集合,显示集合中的元素以及子元素的名字
for(int i = 0;i < nList.getLength();i++)
{
//先从Person元素开始解析
Element personElement = (Element) nList.item(i);
Person p = new Person();
p.setId(Integer.valueOf(personElement.getAttribute("id")));
//获取person下的name和age的Note集合
NodeList childNoList = personElement.getChildNodes();
for(int j = 0;j < childNoList.getLength();j++)
{
Node childNode = childNoList.item(j);
//判断子note类型是否为元素Note
if(childNode.getNodeType() == Node.ELEMENT_NODE)
{
Element childElement = (Element) childNode;
if("name".equals(childElement.getNodeName()))
p.setName(childElement.getFirstChild().getNodeValue());
else if("age".equals(childElement.getNodeName()))
p.setAge(Integer.valueOf(childElement.getFirstChild().getNodeValue()));
}
}
Persons.add(p);
}
} catch (Exception e) {e.printStackTrace();}
return Persons;
}
}
```
**代码分析**:
> 从代码我们就可以看出DOM解析XML的流程,先整个文件读入Dom解析器,然后形成一棵树, 然后我们可以遍历节点列表获取我们需要的数据!
## 5.PULL解析XML数据

**使用PULL解析XML数据的流程**:

**核心代码**:
```
public static ArrayList<Person> getPersons(InputStream xml)throws Exception
{
//XmlPullParserFactory pullPaser = XmlPullParserFactory.newInstance();
ArrayList<Person> persons = null;
Person person = null;
// 创建一个xml解析的工厂
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
// 获得xml解析类的引用
XmlPullParser parser = factory.newPullParser();
parser.setInput(xml, "UTF-8");
// 获得事件的类型
int eventType = parser.getEventType();
while (eventType != XmlPullParser.END_DOCUMENT) {
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
persons = new ArrayList<Person>();
break;
case XmlPullParser.START_TAG:
if ("person".equals(parser.getName())) {
person = new Person();
// 取出属性值
int id = Integer.parseInt(parser.getAttributeValue(0));
person.setId(id);
} else if ("name".equals(parser.getName())) {
String name = parser.nextText();// 获取该节点的内容
person.setName(name);
} else if ("age".equals(parser.getName())) {
int age = Integer.parseInt(parser.nextText());
person.setAge(age);
}
break;
case XmlPullParser.END_TAG:
if ("person".equals(parser.getName())) {
persons.add(person);
person = null;
}
break;
}
eventType = parser.next();
}
return persons;
}
```
**使用Pull生成xml数据的流程**:

**核心代码**:
```
public static void save(List<Person> persons, OutputStream out) throws Exception {
XmlSerializer serializer = Xml.newSerializer();
serializer.setOutput(out, "UTF-8");
serializer.startDocument("UTF-8", true);
serializer.startTag(null, "persons");
for (Person p : persons) {
serializer.startTag(null, "person");
serializer.attribute(null, "id", p.getId() + "");
serializer.startTag(null, "name");
serializer.text(p.getName());
serializer.endTag(null, "name");
serializer.startTag(null, "age");
serializer.text(p.getAge() + "");
serializer.endTag(null, "age");
serializer.endTag(null, "person");
}
serializer.endTag(null, "persons");
serializer.endDocument();
out.flush();
out.close();
}
```
## 6.代码示例下载:
**运行效果图**:
**代码下载**: **XMLParseDemo.zip**:[下载 XMLParseDemo.zip](/try/download/XMLParseDemo.zip)
## 本节小结:
> 本节介绍了Android中三种常用的XML解析方式,DOM,SAX和PULL,移动端我们建议用后面这 两种,而PULL用起来更加简单,这里就不多说了,代码是最好的老师~本节就到这里,下节我们 来学习Android为我们提供的扣脚Json解析方式!谢谢~
- 1.0 Android基础入门教程
- 1.0.1 2015年最新Android基础入门教程目录
- 1.1 背景相关与系统架构分析
- 1.2 开发环境搭建
- 1.2.1 使用Eclipse + ADT + SDK开发Android APP
- 1.2.2 使用Android Studio开发Android APP
- 1.3 SDK更新不了问题解决
- 1.4 Genymotion模拟器安装
- 1.5.1 Git使用教程之本地仓库的基本操作
- 1.5.2 Git之使用GitHub搭建远程仓库
- 1.6 .9(九妹)图片怎么玩
- 1.7 界面原型设计
- 1.8 工程相关解析(各种文件,资源访问)
- 1.9 Android程序签名打包
- 1.11 反编译APK获取代码&资源
- 2.1 View与ViewGroup的概念
- 2.2.1 LinearLayout(线性布局)
- 2.2.2 RelativeLayout(相对布局)
- 2.2.3 TableLayout(表格布局)
- 2.2.4 FrameLayout(帧布局)
- 2.2.5 GridLayout(网格布局)
- 2.2.6 AbsoluteLayout(绝对布局)
- 2.3.1 TextView(文本框)详解
- 2.3.2 EditText(输入框)详解
- 2.3.3 Button(按钮)与ImageButton(图像按钮)
- 2.3.4 ImageView(图像视图)
- 2.3.5.RadioButton(单选按钮)&Checkbox(复选框)
- 2.3.6 开关按钮ToggleButton和开关Switch
- 2.3.7 ProgressBar(进度条)
- 2.3.8 SeekBar(拖动条)
- 2.3.9 RatingBar(星级评分条)
- 2.4.1 ScrollView(滚动条)
- 2.4.2 Date & Time组件(上)
- 2.4.3 Date & Time组件(下)
- 2.4.4 Adapter基础讲解
- 2.4.5 ListView简单实用
- 2.4.6 BaseAdapter优化
- 2.4.7ListView的焦点问题
- 2.4.8 ListView之checkbox错位问题解决
- 2.4.9 ListView的数据更新问题
- 2.5.0 构建一个可复用的自定义BaseAdapter
- 2.5.1 ListView Item多布局的实现
- 2.5.2 GridView(网格视图)的基本使用
- 2.5.3 Spinner(列表选项框)的基本使用
- 2.5.4 AutoCompleteTextView(自动完成文本框)的基本使用
- 2.5.5 ExpandableListView(可折叠列表)的基本使用
- 2.5.6 ViewFlipper(翻转视图)的基本使用
- 2.5.7 Toast(吐司)的基本使用
- 2.5.8 Notification(状态栏通知)详解
- 2.5.9 AlertDialog(对话框)详解
- 2.6.0 其他几种常用对话框基本使用
- 2.6.1 PopupWindow(悬浮框)的基本使用
- 2.6.2 菜单(Menu)
- 2.6.3 ViewPager的简单使用
- 2.6.4 DrawerLayout(官方侧滑菜单)的简单使用
- 3.1.1 基于监听的事件处理机制
- 3.2 基于回调的事件处理机制
- 3.3 Handler消息传递机制浅析
- 3.4 TouchListener PK OnTouchEvent + 多点触碰
- 3.5 监听EditText的内容变化
- 3.6 响应系统设置的事件(Configuration类)
- 3.7 AnsyncTask异步任务
- 3.8 Gestures(手势)
- 4.1.1 Activity初学乍练
- 4.1.2 Activity初窥门径
- 4.1.3 Activity登堂入室
- 4.2.1 Service初涉
- 4.2.2 Service进阶
- 4.2.3 Service精通
- 4.3.1 BroadcastReceiver牛刀小试
- 4.3.2 BroadcastReceiver庖丁解牛
- 4.4.2 ContentProvider再探——Document Provider
- 4.5.1 Intent的基本使用
- 4.5.2 Intent之复杂数据的传递
- 5.1 Fragment基本概述
- 5.2.1 Fragment实例精讲——底部导航栏的实现(方法1)
- 5.2.2 Fragment实例精讲——底部导航栏的实现(方法2)
- 5.2.3 Fragment实例精讲——底部导航栏的实现(方法3)
- 5.2.4 Fragment实例精讲——底部导航栏+ViewPager滑动切换页面
- 5.2.5 Fragment实例精讲——新闻(购物)类App列表Fragment的简单实现
- 6.1 数据存储与访问之——文件存储读写
- 6.2 数据存储与访问之——SharedPreferences保存用户偏好参数
- 6.3.1 数据存储与访问之——初见SQLite数据库
- 6.3.2 数据存储与访问之——又见SQLite数据库
- 7.1.1 Android网络编程要学的东西与Http协议学习
- 7.1.2 Android Http请求头与响应头的学习
- 7.1.3 Android HTTP请求方式:HttpURLConnection
- 7.1.4 Android HTTP请求方式:HttpClient
- 7.2.1 Android XML数据解析
- 7.2.2 Android JSON数据解析
- 7.3.1 Android 文件上传
- 7.3.2 Android 文件下载(1)
- 7.3.3 Android 文件下载(2)
- 7.4 Android 调用 WebService
- 7.5.1 WebView(网页视图)基本用法
- 7.5.2 WebView和JavaScrip交互基础
- 7.5.3 Android 4.4后WebView的一些注意事项
- 7.5.4 WebView文件下载
- 7.5.5 WebView缓存问题
- 7.5.6 WebView处理网页返回的错误码信息
- 7.6.1 Socket学习网络基础准备
- 7.6.2 基于TCP协议的Socket通信(1)
- 7.6.3 基于TCP协议的Socket通信(2)
- 7.6.4 基于UDP协议的Socket通信
- 8.1.1 Android中的13种Drawable小结 Part 1
- 8.1.2 Android中的13种Drawable小结 Part 2
- 8.1.3 Android中的13种Drawable小结 Part 3
- 8.2.1 Bitmap(位图)全解析 Part 1
- 8.2.2 Bitmap引起的OOM问题
- 8.3.1 三个绘图工具类详解
- 8.3.2 绘图类实战示例
- 8.3.3 Paint API之—— MaskFilter(面具)
- 8.3.4 Paint API之—— Xfermode与PorterDuff详解(一)
- 8.3.5 Paint API之—— Xfermode与PorterDuff详解(二)
- 8.3.6 Paint API之—— Xfermode与PorterDuff详解(三)
- 8.3.7 Paint API之—— Xfermode与PorterDuff详解(四)
- 8.3.8 Paint API之—— Xfermode与PorterDuff详解(五)
- 8.3.9 Paint API之—— ColorFilter(颜色过滤器)(1/3)
- 8.3.10 Paint API之—— ColorFilter(颜色过滤器)(2-3)
- 8.3.11 Paint API之—— ColorFilter(颜色过滤器)(3-3)
- 8.3.12 Paint API之—— PathEffect(路径效果)
- 8.3.13 Paint API之—— Shader(图像渲染)
- 8.3.14 Paint几个枚举/常量值以及ShadowLayer阴影效果
- 8.3.15 Paint API之——Typeface(字型)
- 8.3.16 Canvas API详解(Part 1)
- 8.3.17 Canvas API详解(Part 2)剪切方法合集
- 8.3.18 Canvas API详解(Part 3)Matrix和drawBitmapMash
- 8.4.1 Android动画合集之帧动画
- 8.4.2 Android动画合集之补间动画
- 8.4.3 Android动画合集之属性动画-初见
- 8.4.4 Android动画合集之属性动画-又见
- 9.1 使用SoundPool播放音效(Duang~)
- 9.2 MediaPlayer播放音频与视频
- 9.3 使用Camera拍照
- 9.4 使用MediaRecord录音
- 10.1 TelephonyManager(电话管理器)
- 10.2 SmsManager(短信管理器)
- 10.3 AudioManager(音频管理器)
- 10.4 Vibrator(振动器)
- 10.5 AlarmManager(闹钟服务)
- 10.6 PowerManager(电源服务)
- 10.7 WindowManager(窗口管理服务)
- 10.8 LayoutInflater(布局服务)
- 10.9 WallpaperManager(壁纸管理器)
- 10.10 传感器专题(1)——相关介绍
- 10.11 传感器专题(2)——方向传感器
- 10.12 传感器专题(3)——加速度/陀螺仪传感器
- 10.12 传感器专题(4)——其他传感器了解
- 10.14 Android GPS初涉
- 11.0《2015最新Android基础入门教程》完结散花~