
## 1. **B树和B+树**
一般来说,数据库的存储引擎都是采用B树或者B+树来实现索引的存储。首先来看B树,如图所示。
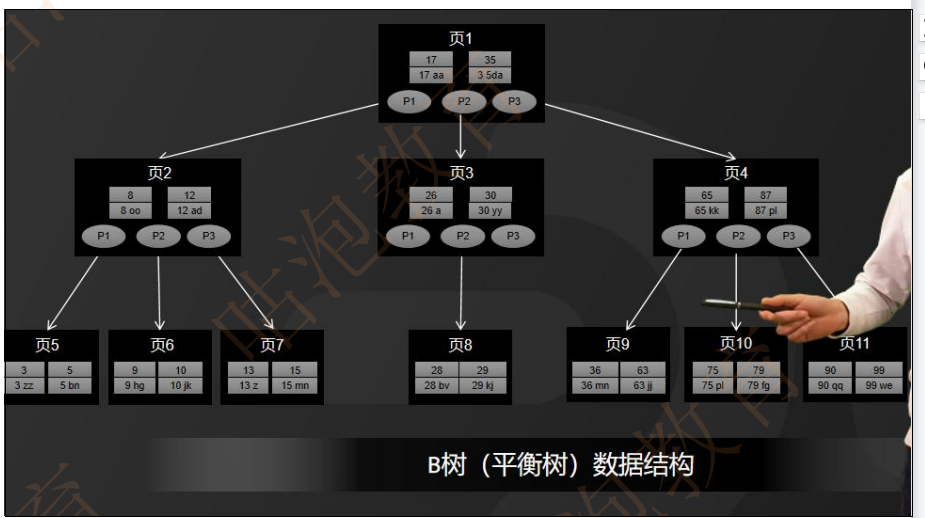
B树是一种多路平衡树,用这种存储结构来存储大量数据,它的整个高度会相比二叉树来说,会矮很多。
而对于数据库而言,所有的数据都将会保存到磁盘上,而磁盘I/O的效率又比较低,特别是在随机磁盘I/O的情况下效率更低。
所以 高度决定了磁盘I/O的次数,磁盘I/O次数越少,对于性能的提升就越大,这也是为什么采用B树作为索引存储结构的原因,如图所示。
而MySQL的InnoDB存储引擎,它用了一种增强的B树结构,也就是B+树来作为索引和数据的存储结构。
相比较于B树结构来说,B+树做了两个方面的优化,如图所示。
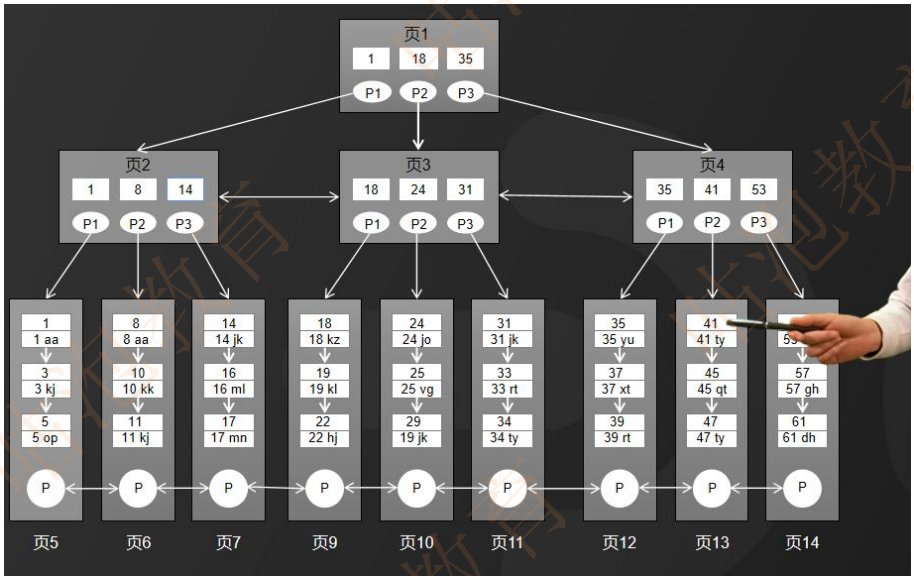
1. B+树的所有数据都存储在叶子节点,非叶子节点只存储索引。
2. 叶子节点中的数据使用双向链表的方式进行关联。
## 2. **原因分析**
我认为,MySQL索引结构采用B+树,有以下4个原因:

1. **从磁盘I/O效率方面来看:**
B+树的非叶子节点不存储数据,所以树的每一层就能够存储更多的索引数量,也就是说,B+树在层高相同的情况下,比B树的存储数据量更多,间接会减少磁盘I/O的次数。
2. **从范围查询效率方面来看:**
在MySQL中,范围查询是一个比较常用的操作,而B+树的所有存储在叶子节点的数据使用了双向链表来关联,所以B+树在查询的时候只需查两个节点进行遍历就行,而B树需要获取所有节点,因此,B+树在范围查询上效率更高。
3. **从全表扫描方面来看:**
因为,B+树的叶子节点存储所有数据,所以B+树的全局扫描能力更强一些,因为它只需要扫描叶子节点。而B树需要遍历整个树。
4. **从自增ID方面来看:**
基于B+树的这样一种数据结构,如果采用自增的整型数据作为主键,还能更好的避免增加数据的时候,带来叶子节点分裂导致的大量运算的问题。
## 3. **总结**
总体来说,我认为技术方案的选型,更多的要根据具体的业务场景来决定,并不一定是说B+树就是最好的选择,就像MongoDB里面采用B树结构,本质上来说,其实是关系型数据库和非关系型数据库的差异
- 开发语言
- java
- Java基础篇
- Java多线程篇
- 进程和线程的区别,进程间如何通信
- 什么是线程上下文切换
- 什么是死锁
- 死锁的必要条件
- Synchrpnized和lock的区别
- 什么是AQS锁
- 为什么AQS使用的双向链表
- 有哪些常见的AQS锁
- sleep()和wait()的区别
- yield()和join()区别
- Java线程池
- SpringBoot
- spring boot 项目开发常用目录结构
- Mybatis-Plus
- MyBatisPlus的CRUD操作
- Mybatis-Plus主键ID生成策略
- JVM
- JVM组成
- 字节码文件的组成
- 类的生命周期
- JVM、JRE和JDK
- arthas
- 使用阿里arthas不停机解决线上问题
- Java IO
- php
- 安装swoole
- composer部分
- windows安装composer
- composer PSR-4映射
- swoole部分
- swoole安装
- thrift部分
- linux下安装thrift
- PHP使用Thrift
- lnmp部分
- 架构的工作原理
- tp5框架生命周期
- zookeeper部分
- zookeeper安装
- sort
- TCP和UDP的区别
- 软件
- xdebug
- vscode+phpstudy+xdebug无法断点(踩坑记)
- Hyperf框架
- 注解
- 开发方案
- 抖音
- 抖音达人视频发布与统计
- 安全问题
- 微信
- 微信公众平台怎样实现用户点击链接向公众号发消息
- CDN加速OSS计费说明
- 程序设计
- 正则表达式
- 面向对象
- 设计模式
- 创建型模式
- 工厂模式
- 单例模式
- 结构型模式
- 适配器模式
- 行为型模式
- 策略模式
- 观察者模式
- 算法部分
- 位运算
- 排序算法
- 双指针
- 贪心算法
- 动态规划
- 二分查找
- 华为题库
- 技术栈
- mq
- MQ 的优势和劣势
- rabbitmq部分
- windows安装rabbitmq
- RabbitMQ 简介
- 工作模式
- 高级特性-消息可靠投递-confirm
- 高级特性-消息可靠投递-return
- 高级特性-Consumer Ack
- 高级特性-消费端限流
- 高级特性-TTL
- 高级特性-死信队列
- Centos7下安装rabbitmq
- 数据库
- MongoDB
- MongoDB 相关概念
- Mysql
- 索引总结
- MySQL架构图
- InnoDB和MyISAM的区别
- 索引设计与优化
- 悲观锁和乐观锁
- mysql如何解除死锁状态
- 查询慢
- 数据库主键的优缺点
- MySQL锁详解
- SQL语句分类
- 开查询账号
- 数据库迁移
- MySQL实战知识点
- mysql清理binlog日志
- 面试总结
- 事务隔离
- 聚集索引与非聚集索引
- B树和B+树
- docker
- docker-desktop安装的坑点
- docker在linux平台下安装
- Ubuntu安装Docker
- 常用命令
- 适用于 Linux 的 Windows 子系统没有已安装的分发版
- docker核心架构图
- docker安装lnmp环境
- docker安装redis
- dockerfile
- docker-compose
- linux
- Ubuntu 更换国内源
- centos
- 常用命令
- virtualbox
- 关于VirtualBox安装Ubuntu时界面显示不全,没有下一步选项
- linux复制当前目录到其子目录下
- 命令
- cat和>、>>
- crontab命令
- 查看当前目录的文件大小
- shell登录和非shell登录
- nginx
- 正向代理
- 反向代理
- 负载均衡
- 分割Nginx的access.log日志并保留30天一个月时长,自动删除多余的日志
- linux安装nginx
- git
- 生成秘钥
- 常用命令
- Linux中git保存用户名密码
- git清除账号密码
- 设置git store 存储账号密码
- git submodule 使用小结
- 微服务
- 微服务技术栈
- nacos
- Nacos服务分级存储模型
- Nacos配置管理-配置热更新
- Nacos集群搭建
- 微服务保护
- 初识Sentinel
- 隔离和降级
- es
- DSL查询语法-相关性算法
- DSL查询语法-FunctionScoreQuery
- DSL查询语法-BooleanQuery
- 搜索结果处理-排序
- es深度分页问题
- 自动补全
- elasticsearch 设置密码
- redis
- redis简介
- 安装redis扩展
- redis数据类型
- redis常见问题
- PHP 使用 Redis 实现分布式锁
- 缓存更新策略
- [ Redis ] AOF 和 RDB 的相关介绍以及相关配置
- 分布式锁的8大坑
- 分布式锁-Redisson
- 内存回收
- UV统计
- Redis主从集群
- redis哨兵
- Redis安装目录下常见文件
- 通讯原理概述
- linux安装redis
- windows
- Win系统端口被占用
- Windows10 WSL2限制cpu和内存
- jekins
- 持续集成
- centos卸载gitlab
- jenkins搭配gitlab的webhook实现自动化部署
- 大数据
- Linux集群分发脚本xsync
- hadoop
- hadoop安装
- hadoop配置文件
- clickhouse
- ClickHouse 安装部署
- flink
- 数据仓库
- zookeeper
- zookeeper分布式安装
- ZK集群启动停止脚本
- kafka
- kafka分布式安装
- kafka集群启动停止脚本
- flume
- flume分布式安装
- Flume配置
- Flume使用
- maxwell
- Maxwell简介
- Maxwell部署
- Maxwell使用
- MaxwellBootstrapUtility - Connections could not be acquired from the underlying database
- 线上事故