## 一、简介
Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
**Hive的表对应HDFS的目录(或文件夹);Hive表中的数据对应HDFS的文件**。
**特点**:
1. 简单、容易上手 (提供了类似 sql 的查询语言 hql),使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析;
2. 灵活性高,可以自定义用户函数 (UDF) 和存储格式;
3. 为超大的数据集设计的计算和存储能力,集群扩展容易;
4. 统一的元数据管理,可与 presto/impala/sparksql 等共享数据;
5. 执行延迟高,不适合做数据的实时处理,但适合做海量数据的离线处理。]
## 二、Hive的体系架构
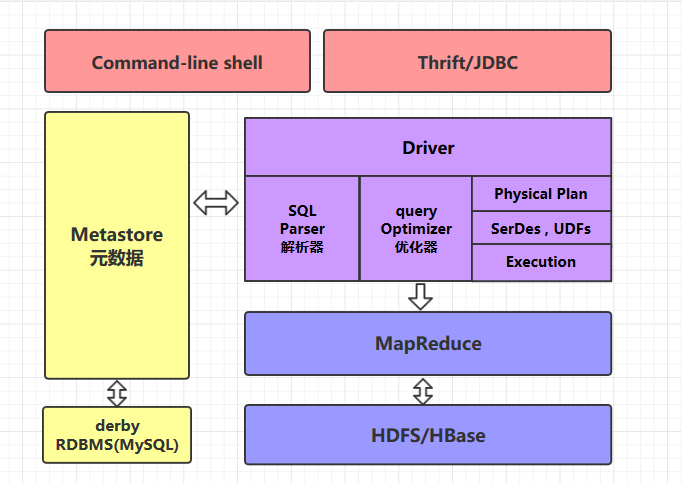
### 2.1 command-line shell & thrift/jdbc
可以用 command-line shell 和 thrift/jdbc 两种方式来操作数据:
* **command-line shell**:通过 hive 命令行的的方式来操作数据;
* **thrift/jdbc**:通过 thrift 协议按照标准的 JDBC 的方式操作数据。
### 2.2 Metastore
在 Hive 中,表名、表结构、字段名、字段类型、表的分隔符等统一被称为元数据。所有的元数据默认存储在 Hive 内置的 derby 数据库中,但由于 derby 只能有一个实例,也就是说不能有多个命令行客户端同时访问,所以在实际生产环境中,通常使用 MySQL 代替 derby。
Hive 进行的是统一的元数据管理,就是说你在 Hive 上创建了一张表,然后在 presto/impala/sparksql 中都是可以直接使用的,它们会从 Metastore 中获取统一的元数据信息,同样的你在 presto/impala/sparksql 中创建一张表,在 Hive 中也可以直接使用。
### 2.3 HQL的执行流程
Hive 在执行一条 HQL 的时候,会经过以下步骤:
1. 语法解析:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象 语法树 AST Tree;
2. 语义解析:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
3. 生成逻辑执行计划:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
4. 优化逻辑执行计划:逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少 shuffle 数据量;
5. 生成物理执行计划:遍历 OperatorTree,翻译为 MapReduce 任务;
6. 优化物理执行计划:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
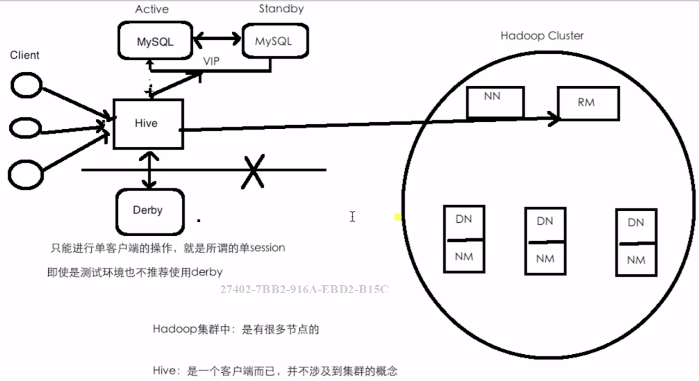
### 三、部署架构
### 四、下载
[cdh下载地址](http://archive.cloudera.com/cdh5/cdh/5/)
`wget http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.15.1.tar.gz`
* 解压到~/app/
### 五、修改配置
**1. hive-env.sh**
进入安装目录下的 `conf/` 目录,拷贝 Hive 的环境配置模板 `flume-env.sh.template`
~~~shell
cp hive-env.sh.template hive-env.sh
~~~
修改 `hive-env.sh`,指定 Hadoop 的安装路径:
~~~shell
HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
~~~
**2\. hive-site.xml**
新建 hive-site.xml 文件,内容如下,主要是配置存放元数据的 MySQL 的地址、驱动、用户名和密码等信息:
<?xml version="1.0"?>
```shell
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<connfiguration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://bizzbee:3306/hadoop_hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
```
* 拷贝数据库驱动
将 MySQL 驱动包拷贝到 Hive 安装目录的 `lib` 目录下, MySQL 驱动的下载地址为:[https://dev.mysql.com/downloads/connector/j/](https://dev.mysql.com/downloads/connector/j/) , 在本仓库的[resources](https://github.com/heibaiying/BigData-Notes/tree/master/resources) 目录下我也上传了一份,有需要的可以自行下载。
* 然后就自己安装一个mysql
* 具体参考[我的mysql56安装笔记](https://www.kancloud.cn/bizzbee/linux_a/1231732)
* 启动hive ---启动之前要确定hdfs和yarn的状态,以及是否成功安装mysql。
```
[bizzbee@bizzbee hive-1.1.0-cdh5.15.1]$ bin/hive
```
