## 创建外部表
```sql
create external table track_info(
ip string,
country string,
province string,
city string,
url string,
time string,
page string
) partitioned by (day string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
location '/project/trackinfo/';
```
> location后面的路径指的是hdfs上面的路径。
* 创建数据输入文件夹
```
hdfs dfs -mkdir -p /project/input/raw/
```
* 数据上传到hdfs
```
hdfs dfs -put track.data /project/input/raw/
```
* 现在要用之前的项目中ETLApp类进行数据清洗。
* 先把类中固定的地址设置为运行参数
~~~
Path outputPath = new Path(args[1]);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
~~~
* 还有一个地方,由于使用了ip解析库,所以先要把ip库文件上传,然后更改代码里面的地址。

* 然后打包,注意不要使用idea命令行,会提示找不到mvn。
```
wangyijiadeMacBook-Air:~ bizzbee$ cd /Users/bizzbee/IdeaProjects/hadooptrainv2
wangyijiadeMacBook-Air:hadooptrainv2 bizzbee$ mvn clean package -DskipTests
```
* 然后上传服务器
```
wangyijiadeMacBook-Air:target bizzbee$ scp hadoop-train-v2-1.0-SNAPSHOT.jar bizzbee@192.168.31.249:~/work/
```
* 执行(参数分别是输入输出路径)
```
[bizzbee@bizzbee ~]$ hadoop jar /home/bizzbee/work/hadoop-train-v2-1.0-SNAPSHOT.jar com.bizzbee.bigdata.hadoop.mr.project.mr.ETLApp hdfs://bizzbee:8020/project/input/raw/track.data hdfs://bizzbee:8020/project/output/result
```
*可以查看到执行成功了
```
http://192.168.31.249:50070/explorer.html#/project/output/result
```
* 然后把完成etl的数据加载到track_info表中。
```
hive> LOAD DATA INPATH 'hdfs://bizzbee:8020/project/output/result' OVERWRITE INTO TABLE track_info partition(day='2019-11-12');
```
* 在hive中使用sql统计每个省的流量。
```
select province,count(*) as cnt from track_info where day='2019-11-12' group by province ;
```
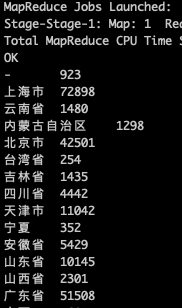
* 创建每个沈的统计数据表。
```sql
create table track_info_province_stat(
province string,
cnt bigint
) partitioned by (day string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
```
* 把之前查询的结果作为数据导入省份表。
```sql
insert overwrite table track_info_province_stat partition(day='2019-11-12')
select province,count(*) as cnt from track_info where day='2019-11-12' group by province ;
```
