import numpy as np
(date_list) = np.loadtxt('tourist_data.csv',
skiprows = 1,
dtype = 'string_',
delimiter = ',',
usecols = 0,
unpack = True)
max_date = date_list[np.argmax(jzg_data)]
max_date.decode('utf-8')
import numpy as np
(date_list) = np.loadtxt('tourist_data.csv',
skiprows = 1,
dtype = 'string_',
delimiter = ',',
usecols = 0,
unpack = True)
max_date = date_list[np.argmax(jzg_data)]
max_date.decode('utf-8')
## 1.6 map函数的例子
```
定义一个函数,将每个元素乘以2
def multiply_by_two(x):
return x * 2
# 创建一个数字列表
numbers = [1, 2, 3, 4, 5]
# 使用map()函数将multiply_by_two函数应用于numbers列表中的每个元素
result = map(multiply_by_two, numbers)
# 由于map()返回的是一个迭代器,我们需要将其转换为列表来查看结果
result_list = list(result)
# 输出结果列表
print(result_list) # 输出: [2, 4, 6, 8, 10]
```
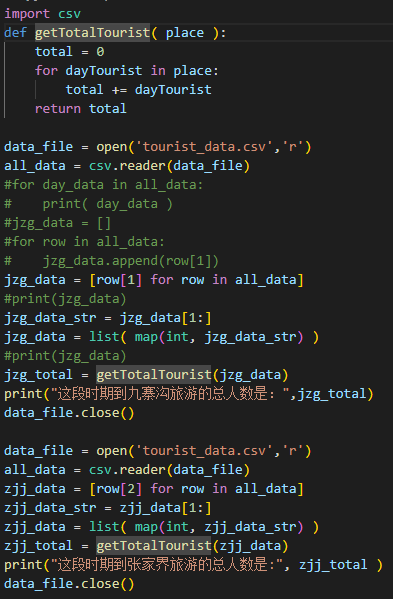
## python 实现计算游客总人数
## 1.8 就业率计算
```
# 定义计算就业率的函数
def calculate_employment_rate(year, total_pop, employed_pop):
return (employed_pop / total_pop) * 100
# 初始化一个字典来存储每年的就业率
employment_rates = {}
# 打开CSV文件并读取内容
file= open('emp_data.txt', 'r')
# 跳过标题行
next(file)
# 逐行读取数据
for line in file:
print(line)
# 分割每行的数据
data = line.strip().split(',')
print(data)
# 提取年份、总人口和就业人口
year = int(data[0])
total_pop = int(data[1])
employed_pop = int(data[2])
# 计算就业率并存储在字典中
rate = calculate_employment_rate(year, total_pop, employed_pop)
employment_rates[year] = rate
# 输出每年的就业率
for year, rate in employment_rates.items():
print(f"年 {year}: 就业率 = {rate}%")
```
## 1.9 Python基础练习 ——外卖店分析
1. 打印出提供汉堡的点名
```
import csv
# 打开CSV文件
with open('swiggy_cleaned.csv', 'r') as file:
reader = csv.DictReader(file)
# 初始化一个列表来存储提供'Burgers'的饭店
burgers_restaurants = []
#计算菜品种类出现的次数
food_count={}
# 遍历CSV文件的每一行
for row in reader:
# 将food_type列中的字符串按逗号分割成列表
food_types = row['food_type'].split(',')
for food in food_types:
if food in food_count:
food_count[food] +=1
else:
food_count[food] =1
# 检查'Burgers'是否在food_type列表中
if 'Burgers' in food_types:
# 将饭店信息添加到列表中
burgers_restaurants.append(row)
# 打印提供'Burgers'的饭店信息
for restaurant in burgers_restaurants:
print(restaurant['hotel_name'])
print("===========================")
max_value=0
max_key=""
for key, value in food_count.items():
if value > max_value:
max_value = value
max_key = key
print(f"可选餐厅最多的菜系是{max_key}")
```
## 2.1 Numpy数组基本运算练习
```python
import numpy as np
# 步骤1:创建NumPy数组
expenses = np.array([800, 1500, 300, 400, 200]) # 分别代表食品、住房、交通、娱乐和其他
expense_categories = ['食品', '住房', '交通', '娱乐', '其他']
# 步骤2:计算总开支
total_expenses = np.sum(expenses)
print(f"总开支为:{total_expenses}元")
# 步骤3:找出哪一项开支最高
max_expense_index = np.argmax(expenses)
max_expense_category = expense_categories[max_expense_index]
max_expense_amount = expenses[max_expense_index]
print(f"开支最高的项目是:{max_expense_category},金额为:{max_expense_amount}元")
```
这个练习不仅涉及了NumPy数组的基本运算(如求和),还涉及了如何找到数组中的最大值及其索引,这在实际生活中处理数据时是非常有用的技能。
## 2.1 Numpy数组基本运算练习2-----客流量练习
**代码实现:**
```python
import numpy as np
# 1. 创建一个3x3的ndarray
customer_flow = np.array([
[100, 150, 200], # 第一天:早、中、晚
[120, 180, 220], # 第二天:早、中、晚
[110, 170, 210] # 第三天:早、中、晚
])
# 2. 计算这三天每个时间段的平均客流量
avg_flow_per_period = np.mean(customer_flow, axis=0)
print("每个时间段的平均客流量:", avg_flow_per_period)
# 3. 找出这三天中哪个时间段的客流量最大
max_flow_period = np.argmax(np.sum(customer_flow, axis=0))
periods = ["早上", "中午", "晚上"]
print("客流量最大的时间段是:", periods[max_flow_period])
# 4. 假设第四天早、中、晚的客流量分别为150、200、250,将这个数据加入到ndarray中
customer_flow = np.vstack([customer_flow, [150, 200, 250]])
# 重新计算每个时间段的平均客流量
avg_flow_per_period_new = np.mean(customer_flow, axis=0)
print("加入第四天数据后,每个时间段的平均客流量:", avg_flow_per_period_new)
```
## 2.3 数组切片练习
**示例**:
```python
import numpy as np
# 步骤1:创建二维数组存储销售数据
# 假设有4种商品(商品A, B, C, D)和3天的销售数据
sales_data = np.array([
[10, 15, 12], # 商品A在三天内的销售数量
[8, 11, 9], # 商品B在三天内的销售数量
[5, 7, 6], # 商品C在三天内的销售数量
[13, 18, 16] # 商品D在三天内的销售数量
])
# 步骤2:提取特定商品(例如商品C)在所有日期的销售数据
sales_of_product_C = sales_data[2, :] # 提取第3行(索引为2)的所有数据
print(f"商品C在三天内的销售数据为:{sales_of_product_C}")
# 步骤3:提取所有商品在特定日期(例如第二天)的销售数据
sales_on_second_day = sales_data[:, 1] # 提取所有行的第2列(索引为1)的数据
print(f"所有商品在第二天的销售数据为:{sales_on_second_day}")
# 步骤4:计算特定商品(例如商品A)在特定日期(例如第一天)的销售数据
sales_of_product_A_on_first_day = sales_data[0, 0] # 提取第1行第1列的数据
print(f"商品A在第一天的销售数量为:{sales_of_product_A_on_first_day}")
```
## 2.4 利用numpy完成旅客人数统计
```
(jzg_data,
zjj_data,
hk_data,
dbhqc_data,
shdisney_data) = np.loadtxt('tourist_data.csv',
skiprows = 1,
dtype = 'int',
delimiter = ',',
usecols = (1,2,3,4,5),
unpack = True)
jzg_total = jzg_data.sum()
zjj_total = zjj_data.sum()
hk_total = hk_data.sum()
dbhqc_total = dbhqc_data.sum()
shdisney_total = shdisney_data.sum()
print("(numpy)这段时期到九寨沟旅游的总人数是:",
jzg_total)
print("(numpy)这段时期到张家界旅游的总人数是:",
zjj_total)
print("(numpy)这段时期到香港旅游的总人数是:",
hk_total)
print("(numpy)这段时期到东部华侨城旅游的总人数是:",
dbhqc_total)
print("(numpy)这段时期到上海迪士尼旅游的总人数是:",
shdisney_total)
```
```
#任务2 旅客人数最多的日期
import numpy as np
(date_list) = np.loadtxt('tourist_data.csv',
skiprows = 1,
dtype = 'string_',
delimiter = ',',
usecols = 0,
unpack = True)
max_date = date_list[np.argmax(jzg_data)]
max_date.decode('utf-8')
```
## 3.3 Series练习
```
import pandas as pd
import matplotlib.pyplot as plt
# 步骤1:创建包含一周七天摄入热量的pandas Series
# 假设数据如下(这只是一个示例,你可以根据实际数据修改)
calories = {
'Monday': 2000,
'Tuesday': 1800,
'Wednesday': 2200,
'Thursday': 1900,
'Friday': 2100,
'Saturday': 2500, # 周末可能有更多的热量摄入
'Sunday': 2300
}
# 创建Series
calories_series = pd.Series(calories)
# 步骤2:计算一周内摄入的总热量
total_calories = calories_series.sum()
print(f"Total calories consumed in a week: {total_calories} kcal")
# 步骤3:找出摄入热量最高和最低的一天
max_calories = calories_series.idxmax() # 获取最大值索引(日期)
min_calories = calories_series.idxmin() # 获取最小值索引(日期)
print(f"The day with the highest calorie intake: {max_calories} - {calories_series[max_calories]} kcal")
print(f"The day with the lowest calorie intake: {min_calories} - {calories_series[min_calories]} kcal")
# 步骤4:计算平均每天摄入的热量
average_calories = calories_series.mean()
print(f"Average daily calorie intake: {average_calories} kcal")
# 步骤5:按照热量从高到低排序
sorted_calories = calories_series.sort_values(ascending=False)
print("Sorted calorie intake from high to low:")
print(sorted_calories)
# 步骤6:绘制条形图展示每天总热量摄入情况
plt.figure(figsize=(10, 10))
calories_series.plot(kind='bar')
plt.title('Total Calorie Intake per Day')
plt.xlabel('Day')
plt.ylabel('Total Calories (kcal)')
plt.show()
```
## 3.5 DataFrame练习-职位分析
任务1:统计文件中计算机行业的职位有多少个?
```
import pandas as pd
# 读取Excel文件
df = pd.read_excel('initdata3.xlsx')
# 使用条件过滤来找出行业为'计算机软件/硬件'的行
computer_industry_jobs = df[df['com_industry'] == '行业计算机软件/硬件']
# 统计符合条件的行数,即计算机行业的职位数量
num_computer_industry_jobs = len(computer_industry_jobs)
# 打印结果
print(f"计算机行业的职位数量是:{num_computer_industry_jobs}个")
```
任务2:请列出所有岗位要求中有“JAVA”的职位。
```
import pandas as pd
# 定义一个函数来检查文本中是否包含'JAVA'
def contains_java(text):
return 'Java' in str(text)
# 读取Excel文件
df = pd.read_excel('initdata3.xlsx')
# 使用apply方法将函数应用到'describe'列的每一行
java_jobs = df[df['describe'].apply(contains_java)]
# 列出所有包含'JAVA'的职位名称
java_job_names = java_jobs['com_name'].tolist()
# 打印结果
print("包含'JAVA'的职位名称:")
for job_name in java_job_names:
print(job_name)
```
任务3:统计每个行业的职位数量,画出饼状图。
```
import pandas as pd
import matplotlib.pyplot as plt
# 读取Excel文件
df = pd.read_excel('initdata3.xlsx')
# 统计每个行业的职位数量
industry_counts = df['com_industry'].value_counts()
# 绘制饼状图
plt.figure(figsize=(10, 7)) # 设置图的大小
industry_counts.plot(kind='pie') # autopct格式化百分比
# 设置图表的标题和标签
plt.title('Job industry')
plt.ylabel('') # 不需要y轴标签
# 使饼状图成为圆形而不是椭圆形
plt.axis('equal')
# 显示图表
plt.show()
```
## 3.5 DataFrame练习-职位筛选
```
df_selected_columns = df[['com_name', 'com_area']]
# 筛选出规模在100-499人的公司
df_100_499 = df[df['com_member'] == '规模20-99人']
# 筛选出学历要求为大专的公司
df_education_bachelor = df[df['education'] == '学历要求大专']
# 筛选出规模在20-99人且地区为江苏/南通/崇川区的公司
df_conditions = df[(df['com_member'] == '规模20-99人') & (df['com_area'] == '地区江苏/南通/崇川区')]
# 筛选出年龄要求为18岁--40岁的公司
df_age_range = df[df['age'].str.contains('18岁--40岁')]
```
## 3.7 loc iloc 练习
```
# 任务1:使用loc方法筛选出"com_name"和"com_area"列的数据。
df_selected_columns = df.loc[:, ['com_name', 'com_area']]
# 任务2:使用iloc方法根据列位置筛选数据筛选出第1列(索引为0)和第5列(索引为4)的数据。
df_selected_columns_by_position = df.iloc[:, [0, 4]]
# 任务3:使用loc方法筛选出"com_name"和"com_area"列,且行标签为0和1的数据。
df_filtered_rows_and_columns = df.loc[[0, 1], ['com_name', 'com_area']]
#任务4:使用iloc方法筛选出第1行到第2行,以及第1列到第3列的数据。
df_selected_range = df.iloc[0:2, 0:3]
```
