## updateStateByKey
除了能够支持 RDD 的算子外,DStream 还有部分独有的*transformation*算子,这当中比较常用的是 `updateStateByKey`。文章开头的词频统计程序,只能统计每一次输入文本中单词出现的数量,想要统计所有历史输入中单词出现的数量,可以使用 `updateStateByKey` 算子。代码如下:
~~~scala
object NetworkWordCountV2 {
def main(args: Array[String]) {
/*
* 本地测试时最好指定 hadoop 用户名,否则会默认使用本地电脑的用户名,
* 此时在 HDFS 上创建目录时可能会抛出权限不足的异常
*/
System.setProperty("HADOOP_USER_NAME", "root")
val sparkConf = new SparkConf().setAppName("NetworkWordCountV2").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
/*必须要设置检查点*/
ssc.checkpoint("hdfs://hadoop001:8020/spark-streaming")
val lines = ssc.socketTextStream("hadoop001", 9999)
lines.flatMap(_.split(" ")).map(x => (x, 1))
.updateStateByKey[Int](updateFunction _) //updateStateByKey 算子
.print()
ssc.start()
ssc.awaitTermination()
}
/**
* 累计求和
*
* @param currentValues 当前的数据
* @param preValues 之前的数据
* @return 相加后的数据
*/
def updateFunction(currentValues: Seq[Int], preValues: Option[Int]): Option[Int] = {
val current = currentValues.sum
val pre = preValues.getOrElse(0)
Some(current + pre)
}
}
~~~
使用 `updateStateByKey` 算子,你必须使用 `ssc.checkpoint()` 设置检查点,这样当使用 `updateStateByKey` 算子时,它会去检查点中取出上一次保存的信息,并使用自定义的 `updateFunction` 函数将上一次的数据和本次数据进行相加,然后返回。
## 处理文件系统的数据
~~~
object FileWordCount{
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[3]").setAppName("FileWordCount")
val ssc = new StreamingContext(sparkConf,Seconds(5));
var lines = ssc.textFileStream("/Users/bizzbee/Desktop/work/projects/sparktrain/ss")
val result = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_);
result.print()
ssc.start()
ssc.awaitTermination()
}
}
~~~
* 这里是**监控ss目录下新增的文件**。要从别的地方移过来,不能直接在里面写。
* 结果打印:

* 文件必须相同的格式。
## foreachRDD 将每次的RDD内容放进数据库
~~~
object ForeachRDDApp{
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("ForeachRDDApp").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val lines = ssc.socketTextStream("localhost", 6789)
val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
result.print()
result.foreachRDD(rdd => {
rdd.foreachPartition(partitionOfRecords => {
val connection = createConnection()
partitionOfRecords.foreach(record => {
val sql = "insert into wordcount(word, wordcount) values('" + record._1 + "'," + record._2 + ")"
connection.createStatement().execute(sql)
})
connection.close()
})
})
ssc.start()
ssc.awaitTermination()
}
/**
* 获取MySQL的连接
*/
def createConnection() = {
Class.forName("com.mysql.jdbc.Driver")
DriverManager.getConnection("jdbc:mysql://localhost:3306/stark", "root", "934158")
}
}
~~~
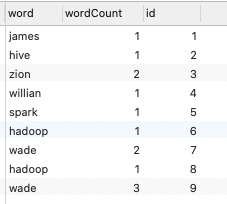
* 存在问题:

## 窗口的DStream
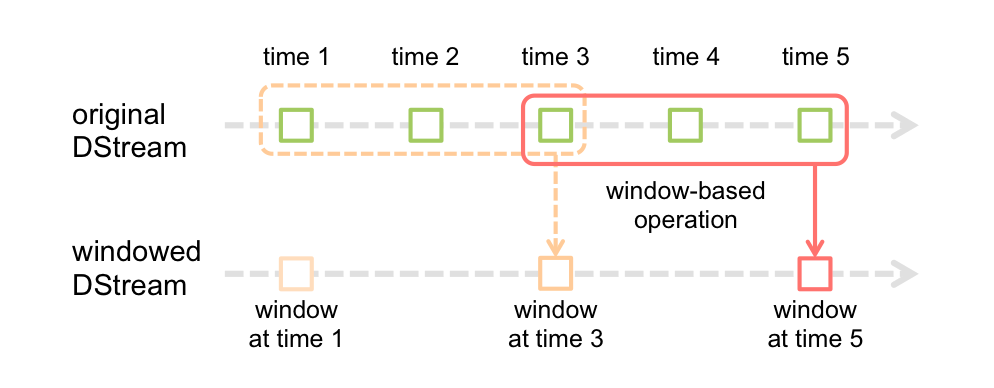
* *窗口长度* - The duration of the window (3 in the figure).
* *窗口间隔* - The interval at which the window operation is performed (2 in the figure).
~~~scala
val windowedWordCounts = pairs.reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(30), Seconds(10))
~~~
##黑名单处理
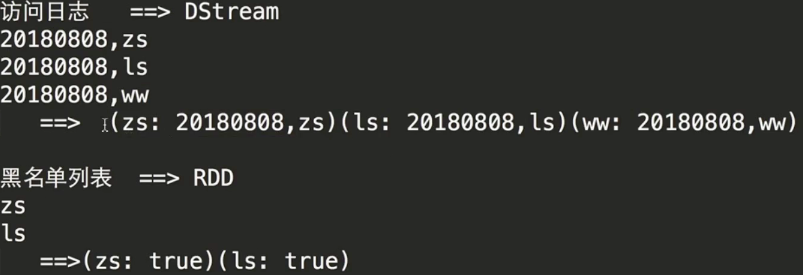
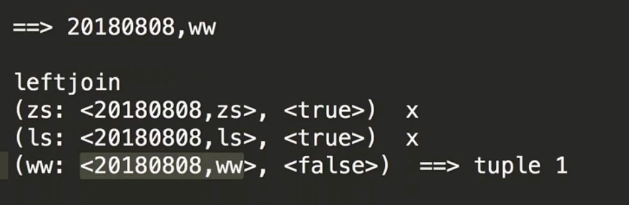
~~~
object TranformApp{
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
/**
* 创建StreamingContext需要两个参数:SparkConf和batch interval
*/
val ssc = new StreamingContext(sparkConf, Seconds(5))
/**
* 构建黑名单
*/
val blacks = List("wade", "james")
val blacksRDD = ssc.sparkContext.parallelize(blacks).map(x => (x, true))
val lines = ssc.socketTextStream("localhost", 6789)
val clicklog = lines.map(x => (x.split(",")(1), x)).transform(rdd => {
rdd.leftOuterJoin(blacksRDD)
.filter(x=> x._2._2.getOrElse(false) != true)
.map(x=>x._2._1)
})
clicklog.print()
ssc.start()
ssc.awaitTermination()
}
}
~~~