
[TOC]
**B tree:** 二叉树(Binary tree),每个节点只能存储一个数。
**B-tree:**B树(B-Tree,并不是B“减”树,横杠为连接符,容易被误导)
B树属于多叉树又名平衡多路查找树。每个节点可以多个数(由磁盘大小决定)。
**B+tree** 和 **B\*tree** 都是 B-tree的变种
## 索引为什么是用B树呢?
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。而B-/+/\*Tree,经过改进可以有效的利用系统对磁盘的块读取特性,在读取相同磁盘块的同时,尽可能多的加载索引数据,来提高索引命中效率,从而达到减少磁盘IO的读取次数。
不了解磁盘相关知识的可以查看 [硬盘基本知识(磁头、磁道、扇区、柱面)](https://www.jianshu.com/p/9aa66f634ed6)
下面通过示意图来看一下,B-tree、B+tree、B\*tree
## B-tree
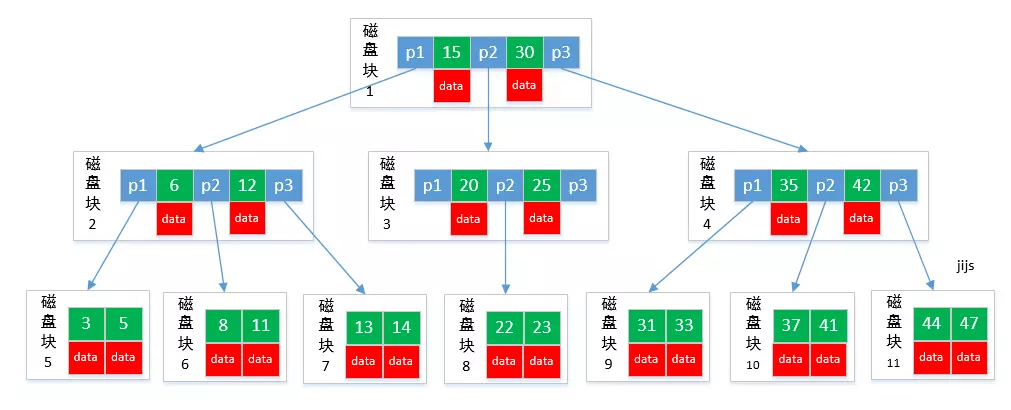
B-树
从图中可以看出,B-tree 利用了磁盘块的特性进行构建的树。每个磁盘块一个节点,每个节点包含了很关键字。把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度。
B-tree巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页(每页为4K),这样每个节点只需要一次I/O就可以完全载入。
B-tree 的数据可以存在任何节点中。
## B+tree
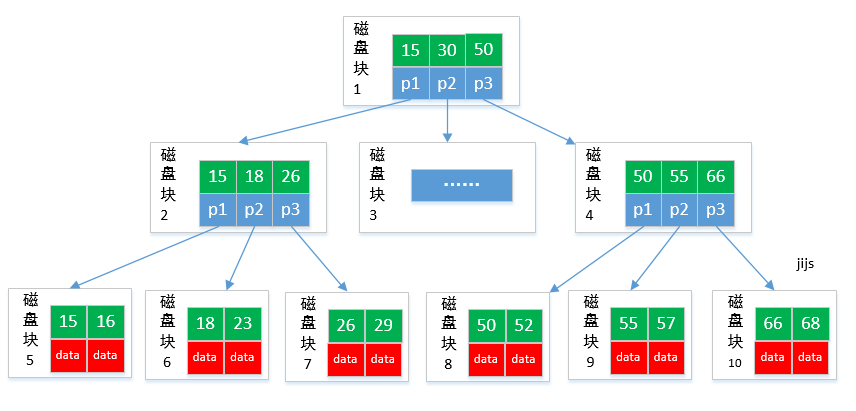
B+树
B+tree 是 B-tree 的变种,数据只能存储在叶子节点。
B+tree 是 B-tree 的变种,B+tree 数据只存储在叶子节点中。这样在B树的基础上每个节点存储的关键字数更多,树的层级更少所以查询数据更快,所有指关键字指针都存在叶子节点,所以每次查找的次数都相同所以查询速度更稳定;
> 如果每个节点能存放M个数据,每个节点的数据在M/2到M之间。预留出空间可以插入新的数据。
## B\*tree
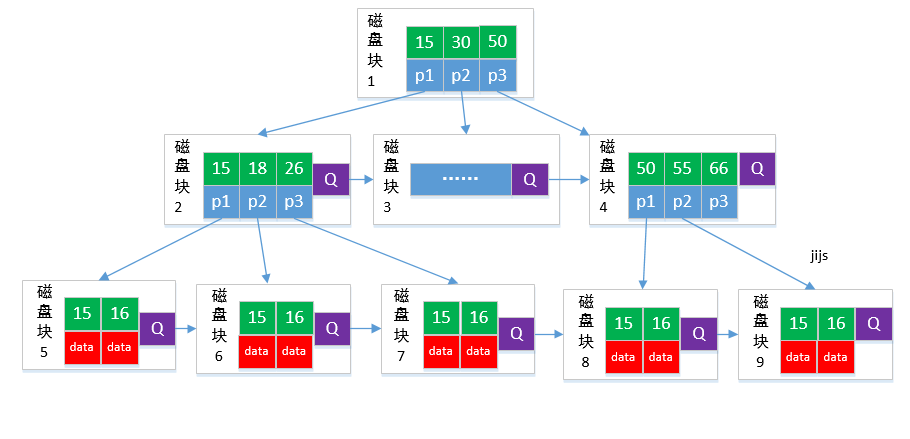
B\*树
B\*tree 每个磁盘块中又添加了对下一个磁盘块的引用。这样可以在当前磁盘块满时,不用扩容直接存储到下一个临近磁盘块中。当两个邻近的磁盘块都满时,这两个磁盘块各分出1/3的数据重新分配一个磁盘块,这样这三个磁盘块的数据都为2/3。
> 如果每个节点能存放M个数据,每个节点的数据在2M/3到M之间。预留出空间可以插入新的数据。
在B+树的基础上因其初始化的容量变大,使得节点空间使用率更高,而又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得B\*树额分解次数变得更少;
- 线程参数含义
- Inoddb索引实现
- 为什么是B+tree
- Redis使用,分布式锁的实现
- 操作系统虚拟内存换页的过程
- TCP三次握手
- Volatile关键字的作用
- 乐观锁,悲观锁
- HashMap结构,是否线程安全
- ConcurrentHashMap如何保证线程安全
- 说一下B树和B+树的区别
- HashMap的实现,扩容机制,扩容时如何保证可操作?
- Spring AOP的原理
- Spring IoC的原理,如何实现,如何解决循环依赖?
- 两线程对变量i进行加1操作,结果如何?为什么?怎么解决?
- CAS概念、原子类实现原理
- synchronize底层实现,如何实现Lock?
- AQS有什么特点?
- 介绍各种网络协议。
- DNS在网络层用哪个协议,为什么。
- 介绍HTTPS协议,详述SSL建立连接过程。
- 反转单链表
- 复杂链表复制
- 数组a,先单调地址再单调递减,输出数组中不同元素个数
- 说一下Java垃圾回收机制
- 64匹马,8个赛道,找最快的4匹马
- 64匹马,8个赛道,找最快的8匹马
- 给出两个升序数组A、B和长度m、n,求第k个大的
- 讲一下多线程与多进程区别
- JVM中什么时候会进行垃圾回收?什么样的对象是可以回收的?
- Spring主要思想是什么?