使用小括号指定一个子表达式后,**匹配这个子表达式的文本**(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。
默认情况下,每个分组会自动拥有一个**组号**,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
<br/>
呃……其实,组号分配还不像我刚说得那么简单:
- 分组0对应整个正则表达式
- 实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号
- 你可以使用(?:exp)这样的语法来剥夺一个分组对组号分配的参与权.
**后向引用**用于重复搜索前面某个分组匹配的文本。例如,\\1代表分组1匹配的文本。难以理解?请看示例:
> \\b(\\w+)\\b\\s+\\1\\b
可以用来匹配重复的单词,像*go go*, 或者*kitty kitty*。
这个表达式首先是一个单词,也就是单词开始处和结束处之间的多于一个的字母或数字(\\b(\\w+)\\b),
这个单词会被捕获到编号为1的分组中,然后是1个或几个空白符(\\s+),最后是分组1中捕获的内容(也就是前面匹配的那个单词)(\\1)。
<br/>
你也可以自己指定子表达式的**组名**。要指定一个子表达式的组名,请使用这样的语法:
(?<Word>\\w+)(或者把尖括号换成'也行:(?'Word'\\w+)),
这样就把\\w+的组名指定为Word了。要反向引用这个分组**捕获**的内容,你可以使用\\k\<Word>,所以上一个例子也可以写成这样:
\\b(?\<Word>\\w+)\\b\\s+\\k\<Word>\\b。
<br/>
使用小括号的时候,还有很多特定用途的语法。下面列出了最常用的一些:
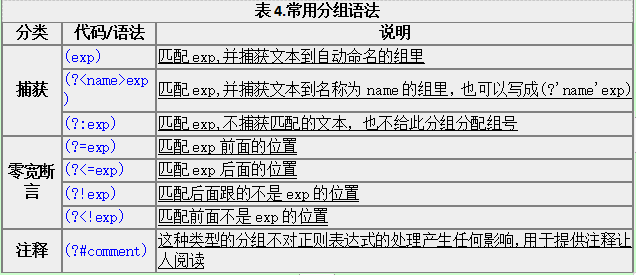
我们已经讨论了前两种语法。第三个(?:exp)不会改变正则表达式的处理方式,只是这样的组匹配的内容不会像前两种那样被捕获到某个组里面,也不会拥有组号。
“我为什么会想要这样做?”——好问题,你觉得为什么呢?
