
出自
> [Java内存模型](http://www.importnew.com/19612.html)
[TOC=1,2]
译文出处: [张坤](http://ifeve.com/java-memory-model-6/) 原文出处:[Jakob Jenkov](http://tutorials.jenkov.com/java-concurrency/java-memory-model.html)
Java内存模型规范了Java虚拟机与计算机内存是如何协同工作的。Java虚拟机是一个完整的计算机的一个模型,因此这个模型自然也包含一个内存模型——又称为Java内存模型。
如果你想设计表现良好的并发程序,理解Java内存模型是非常重要的。Java内存模型规定了如何和何时可以看到由其他线程修改过后的共享变量的值,以及在必须时如何同步的访问共享变量。
原始的Java内存模型存在一些不足,因此Java内存模型在Java1.5时被重新修订。这个版本的Java内存模型在Java8中人在使用。
### Java内存模型内部原理
Java内存模型把Java虚拟机内部划分为线程栈和堆。这张图演示了Java内存模型的逻辑视图。
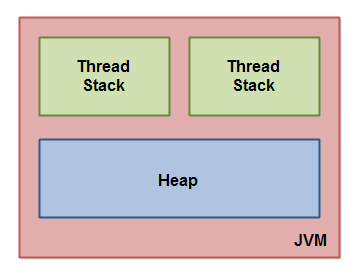
每一个运行在Java虚拟机里的线程都拥有自己的线程栈。这个线程栈包含了这个线程调用的方法当前执行点相关的信息。一个线程仅能访问自己的线程栈。一个线程创建的本地变量对其它线程不可见,仅自己可见。即使两个线程执行同样的代码,这两个线程仍然在自己的线程栈中的代码来创建本地变量。因此,每个线程拥有每个本地变量的独有版本。
所有原始类型的本地变量都存放在线程栈上,因此对其它线程不可见。一个线程可能向另一个线程传递一个原始类型变量的拷贝,但是它不能共享这个原始类型变量自身。
堆上包含在Java程序中创建的所有对象,无论是哪一个对象创建的。这包括原始类型的对象版本。如果一个对象被创建然后赋值给一个局部变量,或者用来作为另一个对象的成员变量,这个对象还是存放在堆上。
下面这张图演示了调用栈和本地变量存放在线程栈上,对象存放在堆上。
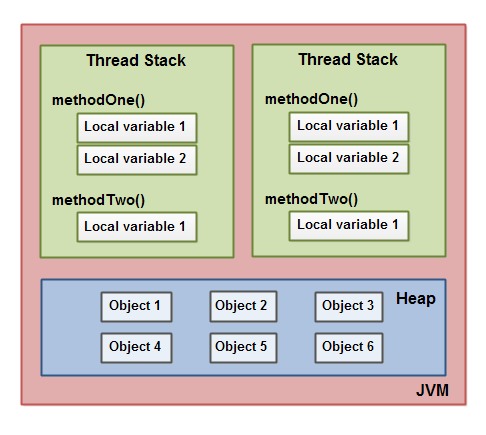
一个本地变量可能是原始类型,在这种情况下,它总是“呆在”线程栈上。
一个本地变量也可能是指向一个对象的一个引用。在这种情况下,引用(这个本地变量)存放在线程栈上,但是对象本身存放在堆上。
一个对象可能包含方法,这些方法可能包含本地变量。这些本地变量还是存放在线程栈上,即使这些方法所属的对象存放在堆上。
一个对象的成员变量可能随着这个对象自身存放在堆上。不管这个成员变量是原始类型还是引用类型。
静态成员变量跟随着类定义一起也存放在堆上。
存放在堆上的对象可以被所有持有对这个对象引用的线程访问。当一个线程可以访问一个对象时,它也可以访问这个对象的成员变量。如果两个线程同时调用同一个对象上的同一个方法,它们将会都访问这个对象的成员变量,但是每一个线程都拥有这个本地变量的私有拷贝。
下图演示了上面提到的点:

两个线程拥有一些列的本地变量。其中一个本地变量(Local Variable 2)执行堆上的一个共享对象(Object 3)。这两个线程分别拥有同一个对象的不同引用。这些引用都是本地变量,因此存放在各自线程的线程栈上。这两个不同的引用指向堆上同一个对象。
注意,这个共享对象(Object 3)持有Object2和Object4一个引用作为其成员变量(如图中Object3指向Object2和Object4的箭头)。通过在Object3中这些成员变量引用,这两个线程就可以访问Object2和Object4。
这张图也展示了指向堆上两个不同对象的一个本地变量。在这种情况下,指向两个不同对象的引用不是同一个对象。理论上,两个线程都可以访问Object1和Object5,如果两个线程都拥有两个对象的引用。但是在上图中,每一个线程仅有一个引用指向两个对象其中之一。
因此,什么类型的Java代码会导致上面的内存图呢?如下所示:
~~~
public class MyRunnable implements Runnable() {
public void run() {
methodOne();
}
public void methodOne() {
int localVariable1 = 45;
MySharedObject localVariable2 =
MySharedObject.sharedInstance;
//... do more with local variables.
methodTwo();
}
public void methodTwo() {
Integer localVariable1 = new Integer(99);
//... do more with local variable.
}
}
public class MySharedObject {
//static variable pointing to instance of MySharedObject
public static final MySharedObject sharedInstance =
new MySharedObject();
//member variables pointing to two objects on the heap
public Integer object2 = new Integer(22);
public Integer object4 = new Integer(44);
public long member1 = 12345;
public long member1 = 67890;
}
~~~
如果两个线程同时执行`run()`方法,就会出现上图所示的情景。`run()`方法调用`methodOne()`方法,`methodOne()`调用`methodTwo()`方法。
`methodOne()`声明了一个原始类型的本地变量和一个引用类型的本地变量。
每个线程执行`methodOne()`都会在它们对应的线程栈上创建`localVariable1`和`localVariable2`的私有拷贝。`localVariable1`变量彼此完全独立,仅“生活”在每个线程的线程栈上。一个线程看不到另一个线程对它的`localVariable1`私有拷贝做出的修改。
每个线程执行`methodOne()`时也将会创建它们各自的`localVariable2`拷贝。然而,两个`localVariable2`的不同拷贝都指向堆上的同一个对象。代码中通过一个静态变量设置`localVariable2`指向一个对象引用。仅存在一个静态变量的一份拷贝,这份拷贝存放在堆上。因此,`localVariable2`的两份拷贝都指向由`MySharedObject`指向的静态变量的同一个实例。`MySharedObject`实例也存放在堆上。它对应于上图中的Object3。
注意,`MySharedObject`类也包含两个成员变量。这些成员变量随着这个对象存放在堆上。这两个成员变量指向另外两个`Integer`对象。这些`Integer`对象对应于上图中的Object2和Object4.
注意,`methodTwo()`创建一个名为`localVariable`的本地变量。这个成员变量是一个指向一个`Integer`对象的对象引用。这个方法设置`localVariable1`引用指向一个新的`Integer`实例。在执行`methodTwo`方法时,`localVariable1`引用将会在每个线程中存放一份拷贝。这两个`Integer`对象实例化将会被存储堆上,但是每次执行这个方法时,这个方法都会创建一个新的`Integer`对象,两个线程执行这个方法将会创建两个不同的`Integer`实例。`methodTwo`方法创建的`Integer`对象对应于上图中的Object1和Object5。
还有一点,`MySharedObject`类中的两个`long`类型的成员变量是原始类型的。因为,这些变量是成员变量,所以它们任然随着该对象存放在堆上,仅有本地变量存放在线程栈上。
### 硬件内存架构
现代硬件内存模型与Java内存模型有一些不同。理解内存模型架构以及Java内存模型如何与它协同工作也是非常重要的。这部分描述了通用的硬件内存架构,下面的部分将会描述Java内存是如何与它“联手”工作的。
下面是现代计算机硬件架构的简单图示:

一个现代计算机通常由两个或者多个CPU。其中一些CPU还有多核。从这一点可以看出,在一个有两个或者多个CPU的现代计算机上同时运行多个线程是可能的。每个CPU在某一时刻运行一个线程是没有问题的。这意味着,如果你的Java程序是多线程的,在你的Java程序中每个CPU上一个线程可能同时(并发)执行。
每个CPU都包含一系列的寄存器,它们是CPU内内存的基础。CPU在寄存器上执行操作的速度远大于在主存上执行的速度。这是因为CPU访问寄存器的速度远大于主存。
每个CPU可能还有一个CPU缓存层。实际上,绝大多数的现代CPU都有一定大小的缓存层。CPU访问缓存层的速度快于访问主存的速度,但通常比访问内部寄存器的速度还要慢一点。一些CPU还有多层缓存,但这些对理解Java内存模型如何和内存交互不是那么重要。只要知道CPU中可以有一个缓存层就可以了。
一个计算机还包含一个主存。所有的CPU都可以访问主存。主存通常比CPU中的缓存大得多。
通常情况下,当一个CPU需要读取主存时,它会将主存的部分读到CPU缓存中。它甚至可能将缓存中的部分内容读到它的内部寄存器中,然后在寄存器中执行操作。当CPU需要将结果写回到主存中去时,它会将内部寄存器的值刷新到缓存中,然后在某个时间点将值刷新回主存。
当CPU需要在缓存层存放一些东西的时候,存放在缓存中的内容通常会被刷新回主存。CPU缓存可以在某一时刻将数据局部写到它的内存中,和在某一时刻局部刷新它的内存。它不会再某一时刻读/写整个缓存。通常,在一个被称作“cache lines”的更小的内存块中缓存被更新。一个或者多个缓存行可能被读到缓存,一个或者多个缓存行可能再被刷新回主存。
### Java内存模型和硬件内存架构之间的桥接
上面已经提到,Java内存模型与硬件内存架构之间存在差异。硬件内存架构没有区分线程栈和堆。对于硬件,所有的线程栈和堆都分布在主内中。部分线程栈和堆可能有时候会出现在CPU缓存中和CPU内部的寄存器中。如下图所示:

当对象和变量被存放在计算机中各种不同的内存区域中时,就可能会出现一些具体的问题。主要包括如下两个方面:
-线程对共享变量修改的可见性
-当读,写和检查共享变量时出现race conditions
下面我们专门来解释以下这两个问题。
#### 共享对象可见性
如果两个或者更多的线程在没有正确的使用`volatile`声明或者同步的情况下共享一个对象,一个线程更新这个共享对象可能对其它线程来说是不接见的。
想象一下,共享对象被初始化在主存中。跑在CPU上的一个线程将这个共享对象读到CPU缓存中。然后修改了这个对象。只要CPU缓存没有被刷新会主存,对象修改后的版本对跑在其它CPU上的线程都是不可见的。这种方式可能导致每个线程拥有这个共享对象的私有拷贝,每个拷贝停留在不同的CPU缓存中。
下图示意了这种情形。跑在左边CPU的线程拷贝这个共享对象到它的CPU缓存中,然后将count变量的值修改为2。这个修改对跑在右边CPU上的其它线程是不可见的,因为修改后的count的值还没有被刷新回主存中去。

解决这个问题你可以使用Java中的`volatile`关键字。`volatile`关键字可以保证直接从主存中读取一个变量,如果这个变量被修改后,总是会被写回到主存中去。
#### Race Conditions
如果两个或者更多的线程共享一个对象,多个线程在这个共享对象上更新变量,就有可能发生[race conditions](http://tutorials.jenkov.com/java-concurrency/race-conditions-and-critical-sections.html)。
想象一下,如果线程A读一个共享对象的变量count到它的CPU缓存中。再想象一下,线程B也做了同样的事情,但是往一个不同的CPU缓存中。现在线程A将`count`加1,线程B也做了同样的事情。现在`count`已经被增在了两个,每个CPU缓存中一次。
如果这些增加操作被顺序的执行,变量`count`应该被增加两次,然后原值+2被写回到主存中去。
然而,两次增加都是在没有适当的同步下并发执行的。无论是线程A还是线程B将`count`修改后的版本写回到主存中取,修改后的值仅会被原值大1,尽管增加了两次。
下图演示了上面描述的情况:

解决这个问题可以使用[Java同步块](http://tutorials.jenkov.com/java-concurrency/synchronized.html)。一个同步块可以保证在同一时刻仅有一个线程可以进入代码的临界区。同步块还可以保证代码块中所有被访问的变量将会从主存中读入,当线程退出同步代码块时,所有被更新的变量都会被刷新回主存中去,不管这个变量是否被声明为volatile。
- JVM
- 深入理解Java内存模型
- 深入理解Java内存模型(一)——基础
- 深入理解Java内存模型(二)——重排序
- 深入理解Java内存模型(三)——顺序一致性
- 深入理解Java内存模型(四)——volatile
- 深入理解Java内存模型(五)——锁
- 深入理解Java内存模型(六)——final
- 深入理解Java内存模型(七)——总结
- Java内存模型
- Java内存模型2
- 堆内内存还是堆外内存?
- JVM内存配置详解
- Java内存分配全面浅析
- 深入Java核心 Java内存分配原理精讲
- jvm常量池
- JVM调优总结
- JVM调优总结(一)-- 一些概念
- JVM调优总结(二)-一些概念
- VM调优总结(三)-基本垃圾回收算法
- JVM调优总结(四)-垃圾回收面临的问题
- JVM调优总结(五)-分代垃圾回收详述1
- JVM调优总结(六)-分代垃圾回收详述2
- JVM调优总结(七)-典型配置举例1
- JVM调优总结(八)-典型配置举例2
- JVM调优总结(九)-新一代的垃圾回收算法
- JVM调优总结(十)-调优方法
- 基础
- Java 征途:行者的地图
- Java程序员应该知道的10个面向对象理论
- Java泛型总结
- 序列化与反序列化
- 通过反编译深入理解Java String及intern
- android 加固防止反编译-重新打包
- volatile
- 正确使用 Volatile 变量
- 异常
- 深入理解java异常处理机制
- Java异常处理的10个最佳实践
- Java异常处理手册和最佳实践
- Java提高篇——对象克隆(复制)
- Java中如何克隆集合——ArrayList和HashSet深拷贝
- Java中hashCode的作用
- Java提高篇之hashCode
- 常见正则表达式
- 类
- 理解java类加载器以及ClassLoader类
- 深入探讨 Java 类加载器
- 类加载器的工作原理
- java反射
- 集合
- HashMap的工作原理
- ConcurrentHashMap之实现细节
- java.util.concurrent 之ConcurrentHashMap 源码分析
- HashMap的实现原理和底层数据结构
- 线程
- 关于Java并发编程的总结和思考
- 40个Java多线程问题总结
- Java中的多线程你只要看这一篇就够了
- Java多线程干货系列(1):Java多线程基础
- Java非阻塞算法简介
- Java并发的四种风味:Thread、Executor、ForkJoin和Actor
- Java中不同的并发实现的性能比较
- JAVA CAS原理深度分析
- 多个线程之间共享数据的方式
- Java并发编程
- Java并发编程(1):可重入内置锁
- Java并发编程(2):线程中断(含代码)
- Java并发编程(3):线程挂起、恢复与终止的正确方法(含代码)
- Java并发编程(4):守护线程与线程阻塞的四种情况
- Java并发编程(5):volatile变量修饰符—意料之外的问题(含代码)
- Java并发编程(6):Runnable和Thread实现多线程的区别(含代码)
- Java并发编程(7):使用synchronized获取互斥锁的几点说明
- Java并发编程(8):多线程环境中安全使用集合API(含代码)
- Java并发编程(9):死锁(含代码)
- Java并发编程(10):使用wait/notify/notifyAll实现线程间通信的几点重要说明
- java并发编程-II
- Java多线程基础:进程和线程之由来
- Java并发编程:如何创建线程?
- Java并发编程:Thread类的使用
- Java并发编程:synchronized
- Java并发编程:Lock
- Java并发编程:volatile关键字解析
- Java并发编程:深入剖析ThreadLocal
- Java并发编程:CountDownLatch、CyclicBarrier和Semaphore
- Java并发编程:线程间协作的两种方式:wait、notify、notifyAll和Condition
- Synchronized与Lock
- JVM底层又是如何实现synchronized的
- Java synchronized详解
- synchronized 与 Lock 的那点事
- 深入研究 Java Synchronize 和 Lock 的区别与用法
- JAVA编程中的锁机制详解
- Java中的锁
- TreadLocal
- 深入JDK源码之ThreadLocal类
- 聊一聊ThreadLocal
- ThreadLocal
- ThreadLocal的内存泄露
- 多线程设计模式
- Java多线程编程中Future模式的详解
- 原子操作(CAS)
- [译]Java中Wait、Sleep和Yield方法的区别
- 线程池
- 如何合理地估算线程池大小?
- JAVA线程池中队列与池大小的关系
- Java四种线程池的使用
- 深入理解Java之线程池
- java并发编程III
- Java 8并发工具包漫游指南
- 聊聊并发
- 聊聊并发(一)——深入分析Volatile的实现原理
- 聊聊并发(二)——Java SE1.6中的Synchronized
- 文件
- 网络
- index
- 内存文章索引
- 基础文章索引
- 线程文章索引
- 网络文章索引
- IOC
- 设计模式文章索引
- 面试
- Java常量池详解之一道比较蛋疼的面试题
- 近5年133个Java面试问题列表
- Java工程师成神之路
- Java字符串问题Top10
- 设计模式
- Java:单例模式的七种写法
- Java 利用枚举实现单例模式
- 常用jar
- HttpClient和HtmlUnit的比较总结
- IO
- NIO
- NIO入门
- 注解
- Java Annotation认知(包括框架图、详细介绍、示例说明)