
[TOC]
# id
select 查询的序列号,包含一组数字,表示查询中执行的select子句或操作表的顺序
**id相同**
执行顺序从上到下
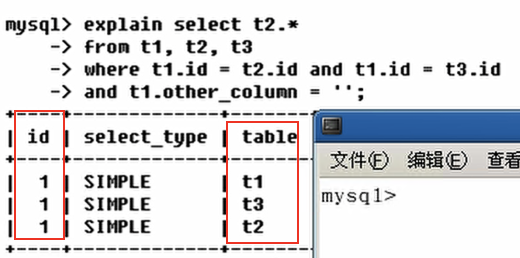
**id不同**
如果是子查询,id序号会递增,id越大优先级越高,越先被执行
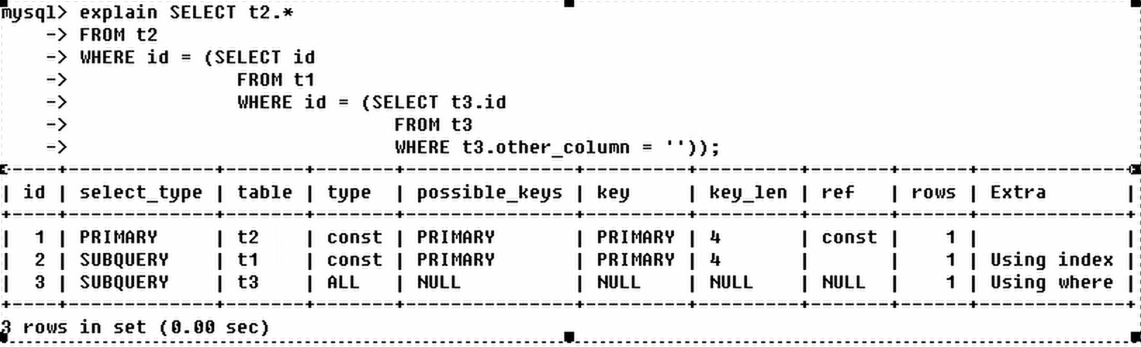
**id相同,不同,同时存在**
id如果相同可以认为是一组,从上往下顺序执行.
在所有组中,id越大,优先级越高,越先执行.
# select_type
查询类型
区别: 普通查询,联合查询,子查询等复合查询
**SIMPLE**
简单的select查询,查询中不包含子查询或者union
**PRIMARY**
查询中若包含任何复杂的子部分,最外层查询则被标记为
**subquery**
在select或where列表中包含的子查询
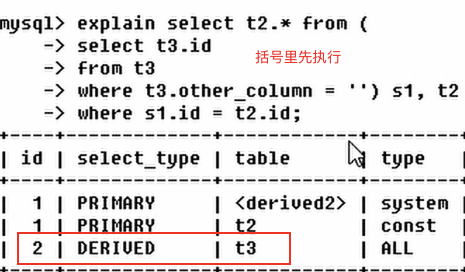
**derived**
在from列表中包含的子查询被标记为derived(衍生).
mysql会递归执行这些子查询,把结果放到临时表里面
**union**
若第二个select出现在union之后,则被标记为union.
若union包含在from子句的子查询,外层select将被标记为derived
**union result**
从union表获取结果的select
# table
这行数据是来自哪个表的
# type
访问类型排列
显示查询使用了何种类型
从最好到最差依次是:
`system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL`
一般来说,得保证到range级别,最好达到ref级别
* system: 表只有1行记录(等于系统表),这是const类型的特例,平时不会出现,可以忽略
* const: 表示通过索引一次就找到了,const用于比较primarykey或者unique索引.因为只匹配一行数据,所以很快将主键置于where列表中,mysql就能将该查询转换为一个常量
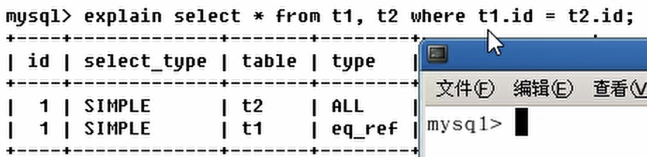
* `eq_ref`: 唯一性扫描,对于每个索引键,表中只有一条记录与之匹配.常见于主键或唯一索引扫描.
~~~
explain select * from t1, t2 where t1.id = t2.id
~~~
* ref: 非唯一性索引扫描,返回匹配某个单独值的所有行.本质上也是一种索引访问,他返回所有匹配某个单独值的行,然而他可能会找寻多个符合条件的行,所以他应该属于查找和扫描混合体
* range: 只检索给定范围的行,使用一个索引来选择行.key列显示使用了那个索引.一般就是在你的where语句中出现了`between,<,>,in`等查询.这种范围扫描索引比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一个点,不用扫描全部索引
* index: `full index scan`,index与all区别为index类型只遍历索引树.这通常比all快,因为索引文件通常比数据文件还小.(也就是说虽然all和index都是读全表,但是index是从索引读取的,而all是从磁盘读取的)
* All: 全表扫描,`full table scan`
# possible_keys
显示可能应用在这张表中的索引,一个或多个.
查询涉及到的字段若存在索引,则该索引将被列出,**但不一定被实际使用**
# key
实际查询使用的索引.如果为null,表示没有使用索引.
查询中若使用了覆盖索引(select中和索引一样),则该索引仅出现在key列表中
# key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度.在不损失精确性的情况下,长度越短越好.
显示的值为索引字段的最大可能长度,**并非实际使用长度.**
是根据表定义计算而来的,不是通过表内检索出的

# ref
显示索引的哪一列被使用了,如果可能的话是一个常数.
哪些列或常量被用于查找索引列上的值.

# rows
根据表统计信息以及索引的选用情况,大致估算出找到所需记录所需要读取的行数
# Extra
包含不适合在其他列中显示但是非常重要的额外信息
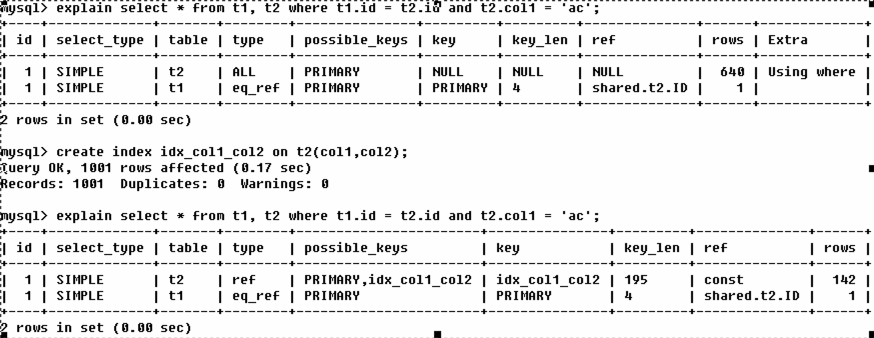
* Using filesort: 说明mysql会对数据使用一个外部的索引排序,而不是按照表内索引顺序进行读取.mysql中无法利用索引完成的排序操作称为'文件排序'
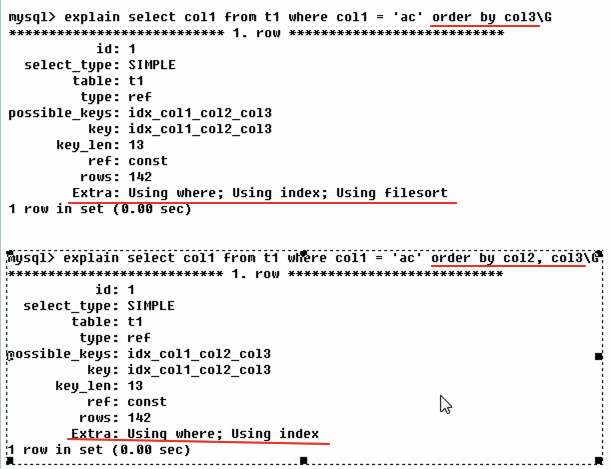
* Using temporary: 使用了临时表保存中间结果,mysql在对查询结果排序时使用临时表.常见于排序`order by`和分组`group by`
Mysql有一点很重要是会默认按照group by排序.
加order by null 这样在group by的时候默认不排序,可以去掉filesort.
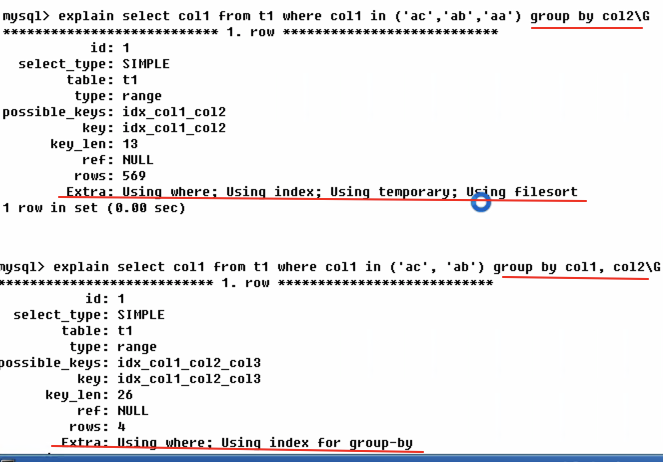
* Using index: 表示相应的select操作中使用覆盖索引,避免访问了表的数据行,效率不错.如果同时出现了using where,表明索引被用来执行索引键值的查找.如果没有同时出现using where,表明索引用来读取数据而非执行查找动作.

* Using where: 使用了where过滤
* Using join buffer: 使用了连接缓存
* impossible where: where子句的值总是false,不能用来获取任何元素,
* `select tables optimized away`: 在没有groupby子句的情况下,基于索引优化min/max操作或者对于myisam存储引擎优化count(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化
* distinct: 优化distinct操作,在找到第一匹配的元组后即停止找同样值的动作
- 基础
- 编译和安装
- classpath到底是什么?
- 编译运行
- 安装
- sdkman多版本
- jabba多版本
- java字节码查看
- 数据类型
- 简介
- 整形
- char和int
- 变量和常量
- 大数值运算
- 基本类型包装类
- Math类
- 内存划分
- 位运算符
- 方法相关
- 方法重载
- 可变参数
- 方法引用
- 面向对象
- 定义
- 继承和覆盖
- 接口和抽象类
- 接口定义增强
- 内建函数式接口
- 多态
- 泛型
- final和static
- 内部类
- 包
- 修饰符
- 异常
- 枚举类
- 代码块
- 对象克隆
- BeanUtils
- java基础类
- scanner类
- Random类
- System类
- Runtime类
- Comparable接口
- Comparator接口
- MessageFormat类
- NumberFormat
- 数组相关
- 数组
- Arrays
- string相关
- String
- StringBuffer
- StringBuilder
- 正则
- 日期类
- Locale类
- Date
- DateFormat
- SimpleDateFormat
- Calendar
- 新时间日期API
- 简介
- LocalDate,LocalTime,LocalDateTime
- Instant时间点
- 带时区的日期,时间处理
- 时间间隔
- 日期时间校正器
- TimeUnit
- 用yyyy
- 集合
- 集合和迭代器
- ArrayList集合
- List
- Set
- 判断集合唯一
- Map和Entry
- stack类
- Collections集合工具类
- Stream数据流
- foreach不能修改内部元素
- of方法
- IO
- File类
- 字节流stream
- 字符流Reader
- IO流分类
- 转换流
- 缓冲流
- 流的操作规律
- properties
- 序列化流与反序列化流
- 打印流
- System类对IO支持
- commons-IO
- IO流总结
- NIO
- 异步与非阻塞
- IO通信
- Unix的IO模型
- epoll对于文件描述符操作模式
- 用户空间和内核空间
- NIO与普通IO的主要区别
- Paths,Path,Files
- Buffer
- Channel
- Selector
- Pipe
- Charset
- NIO代码
- 多线程
- 创建线程
- 线程常用方法
- 线程池相关
- 线程池概念
- ThreadPoolExecutor
- Runnable和Callable
- 常用的几种线程池
- 线程安全
- 线程同步的几种方法
- synchronized
- 死锁
- lock接口
- ThreadLoad
- ReentrantLock
- 读写锁
- 锁的相关概念
- volatile
- 释放锁和不释放锁的操作
- 等待唤醒机制
- 线程状态
- 守护线程和普通线程
- Lamda表达式
- 反射相关
- 类加载器
- 反射
- 注解
- junit注解
- 动态代理
- 网络编程相关
- 简介
- UDP
- TCP
- 多线程socket上传图片
- NIO
- JDBC相关
- JDBC
- 预处理
- 批处理
- 事务
- properties配置文件
- DBUtils
- DBCP连接池
- C3P0连接池
- 获得MySQL自动生成的主键
- Optional类
- Jigsaw模块化
- 日志相关
- JDK日志
- log4j
- logback
- xml
- tomcat
- maven
- 简介
- 仓库
- 目录结构
- 常用命令
- 生命周期
- idea配置
- jar包冲突
- 依赖范围
- 私服
- 插件
- git-commit-id-plugin
- maven-assembly-plugin
- maven-resources-plugin
- maven-compiler-plugin
- versions-maven-plugin
- maven-source-plugin
- tomcat-maven-plugin
- 多环境
- 自定义插件
- stream
- swing
- json
- jackson
- optional
- junit
- gradle
- servlet
- 配置
- ServletContext
- 生命周期
- HttpServlet
- request
- response
- 乱码
- session和cookie
- cookie
- session
- jsp
- 简介
- 注释
- 方法,成员变量
- 指令
- 动作标签
- 隐式对象
- EL
- JSTL
- javaBean
- listener监听器
- Filter过滤器
- 图片验证码
- HttpUrlConnection
- 国际化
- 文件上传
- 文件下载
- spring
- 简介
- Bean
- 获取和实例化
- 属性注入
- 自动装配
- 继承和依赖
- 作用域
- 使用外部属性文件
- spel
- 前后置处理器
- 生命周期
- 扫描规则
- 整合多个配置文件
- 注解
- 简介
- 注解分层
- 类注入
- 分层和作用域
- 初始化方法和销毁方法
- 属性
- 泛型注入
- Configuration配置文件
- aop
- aop的实现
- 动态代理实现
- cglib代理实现
- aop名词
- 简介
- aop-xml
- aop-注解
- 代理方式选择
- jdbc
- 简介
- JDBCTemplate
- 事务
- 整合
- junit整合
- hibernate
- 简介
- hibernate.properties
- 实体对象三种状态
- 检索方式
- 简介
- 导航对象图检索
- OID检索
- HQL
- Criteria(QBC)
- Query
- 缓存
- 事务管理
- 关系映射
- 注解
- 优化
- MyBatis
- 简介
- 入门程序
- Mapper动态代理开发
- 原始Dao开发
- Mapper接口开发
- SqlMapConfig.xml
- map映射文件
- 输出返回map
- 输入参数
- pojo包装类
- 多个输入参数
- resultMap
- 动态sql
- 关联
- 一对一
- 一对多
- 多对多
- 整合spring
- CURD
- 占位符和sql拼接以及参数处理
- 缓存
- 延迟加载
- 注解开发
- springMVC
- 简介
- RequestMapping
- 参数绑定
- 常用注解
- 响应
- 文件上传
- 异常处理
- 拦截器
- springBoot
- 配置
- 热更新
- java配置
- springboot配置
- yaml语法
- 运行
- Actuator 监控
- 多环境配置切换
- 日志
- 日志简介
- logback和access
- 日志文件配置属性
- 开机自启
- aop
- 整合
- 整合Redis
- 整合Spring Data JPA
- 基本查询
- 复杂查询
- 多数据源的支持
- Repository分析
- JpaSpecificationExecutor
- 整合Junit
- 整合mybatis
- 常用注解
- 基本操作
- 通用mapper
- 动态sql
- 关联映射
- 使用xml
- spring容器
- 整合druid
- 整合邮件
- 整合fastjson
- 整合swagger
- 整合JDBC
- 整合spingboot-cache
- 请求
- restful
- 拦截器
- 常用注解
- 参数校验
- 自定义filter
- websocket
- 响应
- 异常错误处理
- 文件下载
- 常用注解
- 页面
- Thymeleaf组件
- 基本对象
- 内嵌对象
- 上传文件
- 单元测试
- 模拟请求测试
- 集成测试
- 源码解析
- 自动配置原理
- 启动流程分析
- 源码相关链接
- Servlet,Filter,Listener
- springcloud
- 配置
- 父pom
- 创建子工程
- Eureka
- Hystrix
- Ribbon
- Feign
- Zuul
- kotlin
- 基本数据类型
- 函数
- 区间
- 区块链
- 简介
- linux
- ulimit修改
- 防止syn攻击
- centos7部署bbr
- debain9开启bbr
- mysql
- 隔离性
- sql执行加载顺序
- 7种join
- explain
- 索引失效和优化
- 表连接优化
- orderby的filesort问题
- 慢查询
- show profile
- 全局查询日志
- 死锁解决
- sql
- 主从
- IDEA
- mac快捷键
- 美化界面
- 断点调试
- 重构
- springboot-devtools热部署
- IDEA进行JAR打包
- 导入jar包
- ProjectStructure
- toString添加json模板
- 配置maven
- Lombok插件
- rest client
- 文档显示
- sftp文件同步
- 书签
- 代码查看和搜索
- postfix
- live template
- git
- 文件头注释
- JRebel
- 离线模式
- xRebel
- github
- 连接mysql
- 选项没有Java class的解决方法
- 扩展
- 项目配置和web部署
- 前端开发
- json和Inject language
- idea内存和cpu变高
- 相关设置
- 设计模式
- 单例模式
- 简介
- 责任链
- JUC
- 原子类
- 原子类简介
- 基本类型原子类
- 数组类型原子类
- 引用类型原子类
- JVM
- JVM规范内存解析
- 对象的创建和结构
- 垃圾回收
- 内存分配策略
- 备注
- 虚拟机工具
- 内存模型
- 同步八种操作
- 内存区域大小参数设置
- happens-before
- web service
- tomcat
- HTTPS
- nginx
- 变量
- 运算符
- 模块
- Rewrite规则
- Netty
- netty为什么没用AIO
- 基本组件
- 源码解读
- 简单的socket例子
- 准备netty
- netty服务端启动
- 案例一:发送字符串
- 案例二:发送对象
- websocket
- ActiveMQ
- JMS
- 安装
- 生产者-消费者代码
- 整合springboot
- kafka
- 简介
- 安装
- 图形化界面
- 生产过程分析
- 保存消息分析
- 消费过程分析
- 命令行
- 生产者
- 消费者
- 拦截器interceptor
- partition
- kafka为什么快
- kafka streams
- kafka与flume整合
- RabbitMQ
- AMQP
- 整体架构
- RabbitMQ安装
- rpm方式安装
- 命令行和管控页面
- 消息生产与消费
- 整合springboot
- 依赖和配置
- 简单测试
- 多方测试
- 对象支持
- Topic Exchange模式
- Fanout Exchange订阅
- 消息确认
- java client
- RabbitAdmin和RabbitTemplate
- 两者简介
- RabbitmqAdmin
- RabbitTemplate
- SimpleMessageListenerContainer
- MessageListenerAdapter
- MessageConverter
- 详解
- Jackson2JsonMessageConverter
- ContentTypeDelegatingMessageConverter
- lucene
- 简介
- 入门程序
- luke查看索引
- 分析器
- 索引库维护
- elasticsearch
- 配置
- 插件
- head插件
- ik分词插件
- 常用术语
- Mapping映射
- 数据类型
- 属性方法
- Dynamic Mapping
- Index Template 索引模板
- 管理映射
- 建立映射
- 索引操作
- 单模式下CURD
- mget多个文档
- 批量操作
- 版本控制
- 基本查询
- Filter过滤
- 组合查询
- 分析器
- redis
- String
- list
- hash
- set
- sortedset
- 发布订阅
- 事务
- 连接池
- 管道
- 分布式可重入锁
- 配置文件翻译
- 持久化
- RDB
- AOF
- 总结
- Lettuce
- zookeeper
- zookeeper简介
- 集群部署
- Observer模式
- 核心工作机制
- zk命令行操作
- zk客户端API
- 感知服务动态上下线
- 分布式共享锁
- 原理
- zab协议
- 两阶段提交协议
- 三阶段提交协议
- Paxos协议
- ZAB协议
- hadoop
- 简介
- hadoop安装
- 集群安装
- 单机安装
- linux编译hadoop
- 添加新节点
- 退役旧节点
- 集群间数据拷贝
- 归档
- 快照管理
- 回收站
- 检查hdfs健康状态
- 安全模式
- hdfs简介
- hdfs命令行操作
- 常见问题汇总
- hdfs客户端操作
- mapreduce工作机制
- 案例-单词统计
- 局部聚合Combiner
- combiner流程
- combiner案例
- 自定义排序
- 自定义Bean对象
- 排序的分类
- 案例-按总量排序需求
- 一次性完成统计和排序
- 分区
- 分区简介
- 案例-结果分区
- 多表合并
- reducer端合并
- map端合并(分布式缓存)
- 分组
- groupingComparator
- 案例-求topN
- 全局计数器
- 合并小文件
- 小文件的弊端
- CombineTextInputFormat机制
- 自定义InputFormat
- 自定义outputFormat
- 多job串联
- 倒排索引
- 共同好友
- 串联
- 数据压缩
- InputFormat接口实现类
- yarn简介
- 推测执行算法
- 本地提交到yarn
- 框架运算全流程
- 数据倾斜问题
- mapreduce的优化方案
- HA机制
- 优化
- Hive
- 安装
- shell参数
- 数据类型
- 集合类型
- 数据库
- DDL操作
- 创建表
- 修改表
- 分区表
- 分桶表
- DML操作
- load
- insert
- select
- export,import
- Truncate
- 注意
- 严格模式
- 函数
- 内置运算符
- 内置函数
- 自定义函数
- Transfrom实现
- having和where不同
- 压缩
- 存储
- 存储和压缩结合使用
- explain详解
- 调优
- Fetch抓取
- 本地模式
- 表的优化
- GroupBy
- count(Distinct)去重统计
- 行列过滤
- 动态分区调整
- 数据倾斜
- 并行执行
- JVM重用
- 推测执行
- reduce内存和个数
- sql查询结果作为变量(shell)
- youtube
- flume
- 简介
- 安装
- 常用组件
- 拦截器
- 案例
- 监听端口到控制台
- 采集目录到HDFS
- 采集文件到HDFS
- 多个agent串联
- 日志采集和汇总
- 单flume多channel,sink
- 自定义拦截器
- 高可用配置
- 使用注意
- 监控Ganglia
- sqoop
- 安装
- 常用命令
- 数据导入
- 准备数据
- 导入数据到HDFS
- 导入关系表到HIVE
- 导入表数据子集
- 增量导入
- 数据导出
- 打包脚本
- 作业
- 原理
- azkaban
- 简介
- 安装
- 案例
- 简介
- command类型单一job
- command类型多job工作流flow
- HDFS操作任务
- mapreduce任务
- hive脚本任务
- oozie
- 安装
- hbase
- 简介
- 系统架构
- 物理存储
- 寻址机制
- 读写过程
- 安装
- 命令行
- 基本CURD
- java api
- CURD
- CAS
- 过滤器查询
- 建表高级属性
- 与mapreduce结合
- 与sqoop结合
- 协处理器
- 参数配置优化
- 数据备份和恢复
- 节点管理
- 案例-点击流
- 简介
- HUE
- 安装
- storm
- 简介
- 安装
- 集群启动及任务过程分析
- 单词统计
- 单词统计(接入kafka)
- 并行度和分组
- 启动流程分析
- ACK容错机制
- ACK简介
- BaseRichBolt简单使用
- BaseBasicBolt简单使用
- Ack工作机制
- 本地目录树
- zookeeper目录树
- 通信机制
- 案例
- 日志告警
- 工具
- YAPI
- chrome无法手动拖动安装插件
- 时间和空间复杂度
- jenkins
- 定位cpu 100%
- 常用脚本工具
- OOM问题定位
- scala
- 编译
- 基本语法
- 函数
- 数组常用方法
- 集合
- 并行集合
- 类
- 模式匹配
- 异常
- tuple元祖
- actor并发编程
- 柯里化
- 隐式转换
- 泛型
- 迭代器
- 流stream
- 视图view
- 控制抽象
- 注解
- spark
- 企业架构
- 安装
- api开发
- mycat
- Groovy
- 基础