
## 三个定时任务
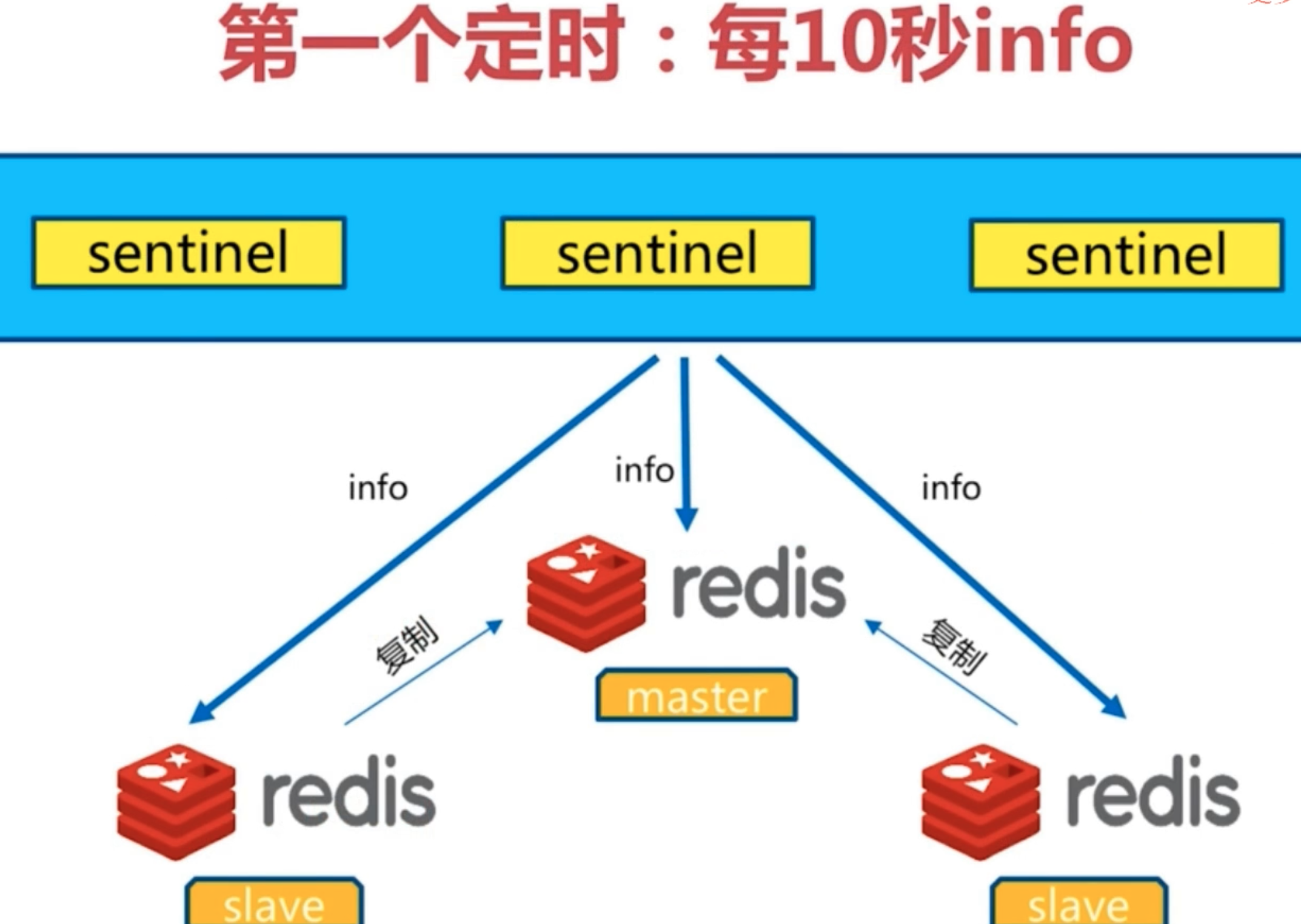
1. 每10秒每个sentinel对master和slave执行info;
1.发现slave节点;
2. 确认主从关系;
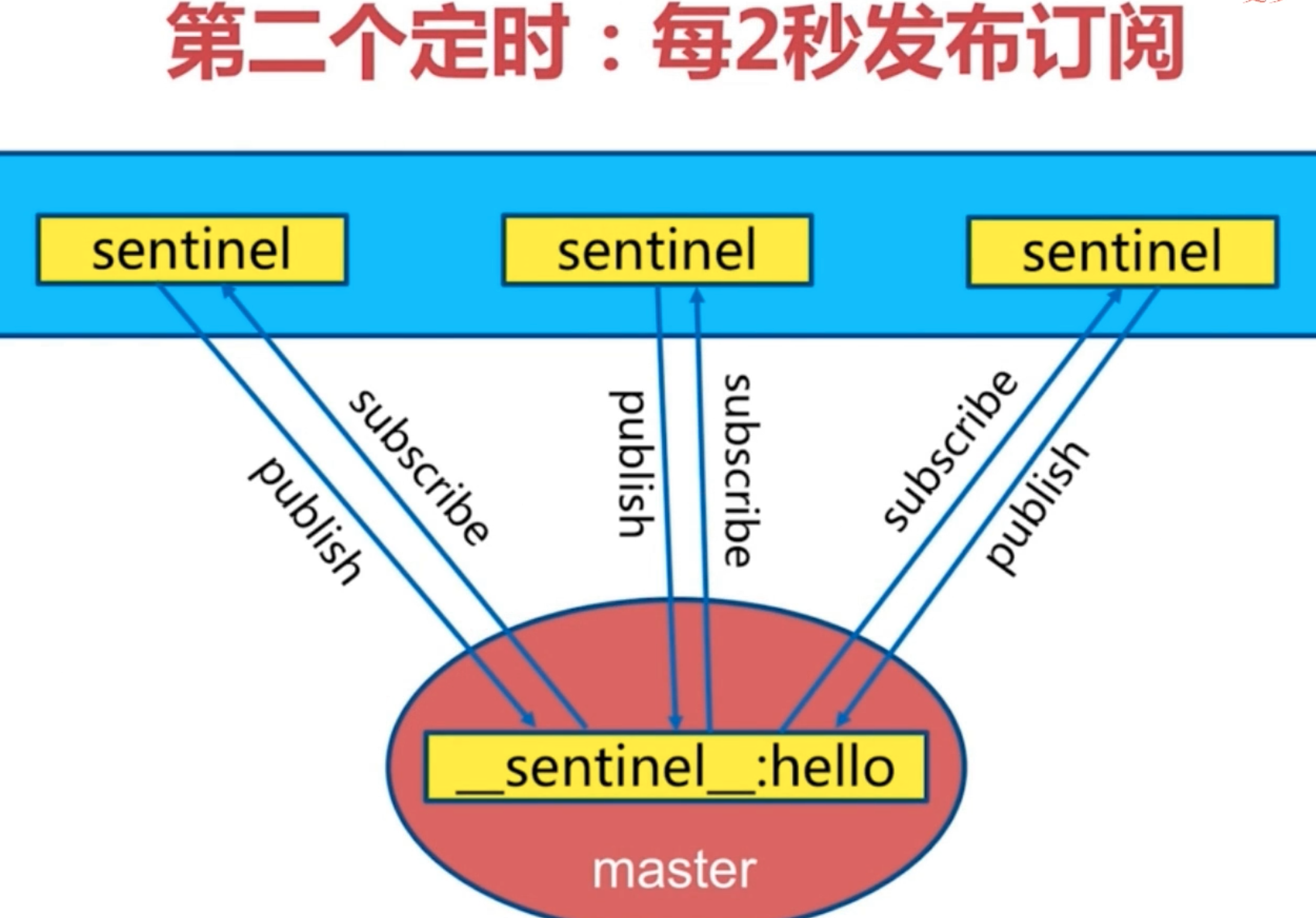
2. 每2秒每个sentinel通过master节点的channel交换信息(pub/sub)channel是发布订阅的频道;
1. 通过__sentinel__:hello频道交互
2. 交互对节点的“看法”和自身信息;
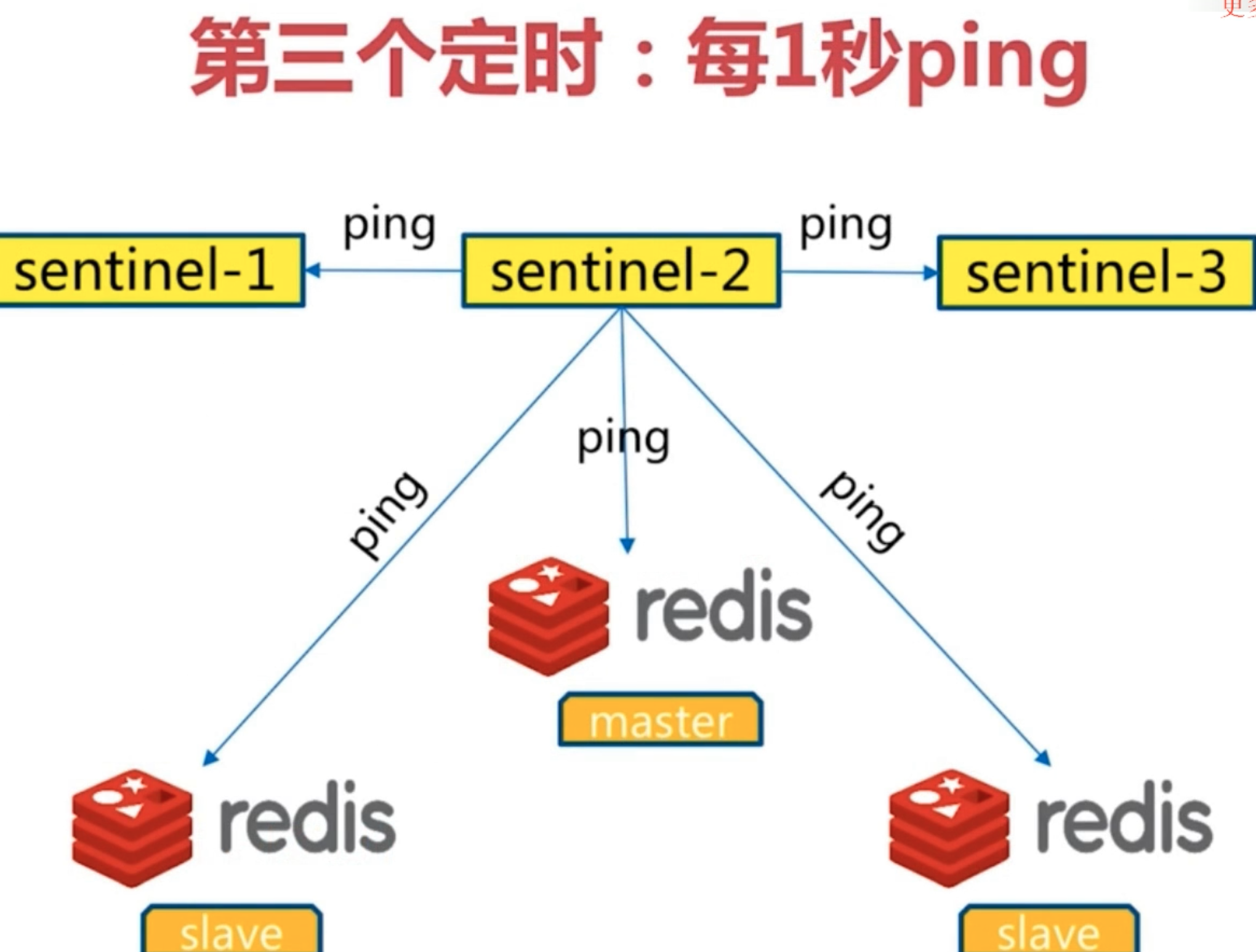
3. 每1秒每个sentinel对其他sentinel和redis执行ping;
1. 心跳检测,失败判定依据;
## 主观下线和客观下线
主观下线:
上面介绍的第三个定时任务(每隔一秒),当这些节点超过down-after-milliseconds(设置的有效回复时间)没有进行有效的回复,Sentinel节点就会对该节点做失败判定,这个行为叫做主观下线
客观下线:
当Sentinel主观下线的节点是主节点时,该Sentinel节点会通过sentinel ismaster-down-by-addr命令向其他Sentinel节点询问对主节点的判断,当超过个数,Sentinel节点认为主节点确实有问题,这时该Sentinel节点会 做出客观下线的决定
这样客观下线的含义是比较明显了,也就是大部分Sentinel节点都对主节点的下线做了同意的判定,那么这个判定就是客观的
当判定完客观下线后是不是就可以进行故障转移了?当然不是,实际上至于要一个sentinel节点来执行,所以要先进行领导者的选择,由这个领导者来进行。
## 领导者节点的选举
Redis使用了Raft算法实 现领导者选举,因为Raft算法相对比较抽象和复杂,以及篇幅所限,所以这里给出一个Redis Sentinel进行领导者选举的大致思路:
1)每个在线的Sentinel节点都有资格成为领导者,当它确认主节点主观下线时候,会向其他Sentinel节点发送sentinel is-master-down-by-addr命令, 要求将自己设置为领导者
2)收到命令的Sentinel节点,如果没有同意过其他Sentinel节点的sentinel is-master-down-by-addr命令,将同意该请求,否则拒绝
3)如果该Sentinel节点发现自己的票数已经大于等于max(quorum, num(sentinels)/2+1),那么它将成为领导者; 如下图的2就是通过((节点数/2) + 1)计算获得(意思就是大于半数+1的节点同意); 所以sentinel的节点数最好是一个奇数(3,5,7);

4)如果此过程没有选举出领导者,将进入下一次选举
选举的过程非常快,基本上谁先完成客观下线,谁就是领导者
其实这个过程就是一个投票的过程,sentinel中先完成客观下线的就向其他sentinel节点询问是否同意自己当领导,假如票数大于一半,自己将成为领导者,如果没有足够的票数,就重新进行选举;

## 故障转移(sentinel领导者节点完成)
故障转移就是当master宕机,选择一个合适的slave节点来升级为master节点的操作,sentinel会自动完成这个,不需要手动实现;
具体步骤:
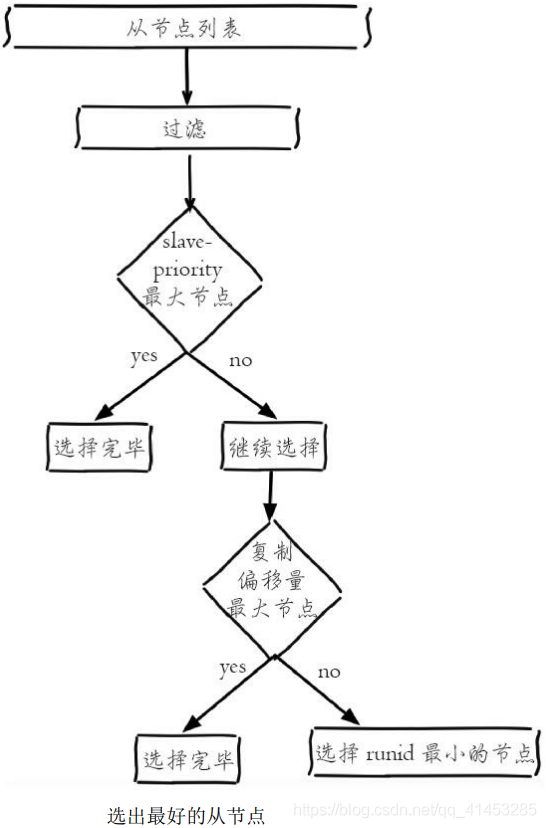
1)在从节点列表中选出一个节点作为新的主节点,选择方法如下:
* a)过滤:“不健康”(主观下线、断线)、5秒内没有回复过Sentinel节 点ping响应、与主节点失联超过down-after-milliseconds\*10秒
* b)选择slave-priority(从节点优先级)最高的从节点列表,如果存在则返回,不存在则继续;(默认不配置的)
* c)选择复制偏移量最大的从节点(复制的最完整),如果存在则返回,不存在则继续
* d)选择runid最小的从节点
2)Sentinel领导者节点会对第一步选出来的从节点执行slaveof no one命令让其成为主节点
3)Sentinel领导者节点会向剩余的从节点发送命令,让它们成为新主节点的从节点,复制规则和parallel-syncs参数有关
4)Sentinel节点集合会将原来的主节点更新为从节点,并保持着对其关注,当其恢复后命令它去复制新的主节点;
- Redis简介
- 简介
- 典型应用场景
- Redis安装
- 安装
- redis可执行文件说明
- 三种启动方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 数据结构和内部编码
- 单线程
- 数据类型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查询
- Pipline
- 发布订阅
- Bitmap
- Hyperloglog
- GEO
- 持久化机制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉择
- 开发运维常见问题
- fork操作
- 子进程外开销
- AOF追加阻塞
- 单机多实例部署
- Redis复制原理和优化
- 什么是主从复制
- 主从复制配置
- 全量复制和部分复制
- 故障处理
- 开发运维常见问题
- Sentinel
- 主从复制高可用
- 架构说明
- 安装配置
- 客户端连接
- 实现原理
- 常见开发运维问题
- 高可用读写分离
- 故障转移client怎么知道新的master地址
- 总结
- Sluster
- 呼唤集群
- 数据分布
- 搭建集群
- 集群通信
- 集群扩容
- 集群缩容
- 客户端路由
- 故障转移
- 故障发现
- 故障恢复
- 开发运维常见问题
- 缓存设计与优化
- 缓存收益和成本
- 缓存更新策略
- 缓存粒度控制
- 缓存穿透优化
- 缓存雪崩优化
- 无底洞问题优化
- 热点key重建优化
- 总结
- 布隆过滤器
- 引出布隆过滤器
- 布隆过滤器基本原理
- 布隆过滤器误差率
- 本地布隆过滤器
- Redis布隆过滤器
- 分布式布隆过滤器
- 开发规范
- 内存管理
- 开发运维常见坑
- 实战
- 对文章进行投票
- 数据库的概念
- 启动多实例