
## 伸缩原理
集群伸缩就是槽位和数据在节点之间的移动;
## 扩容集群
1. 准备新节点;
1.集群模式;
2.配置和其他节点统一;
3.启动后是孤儿节点;
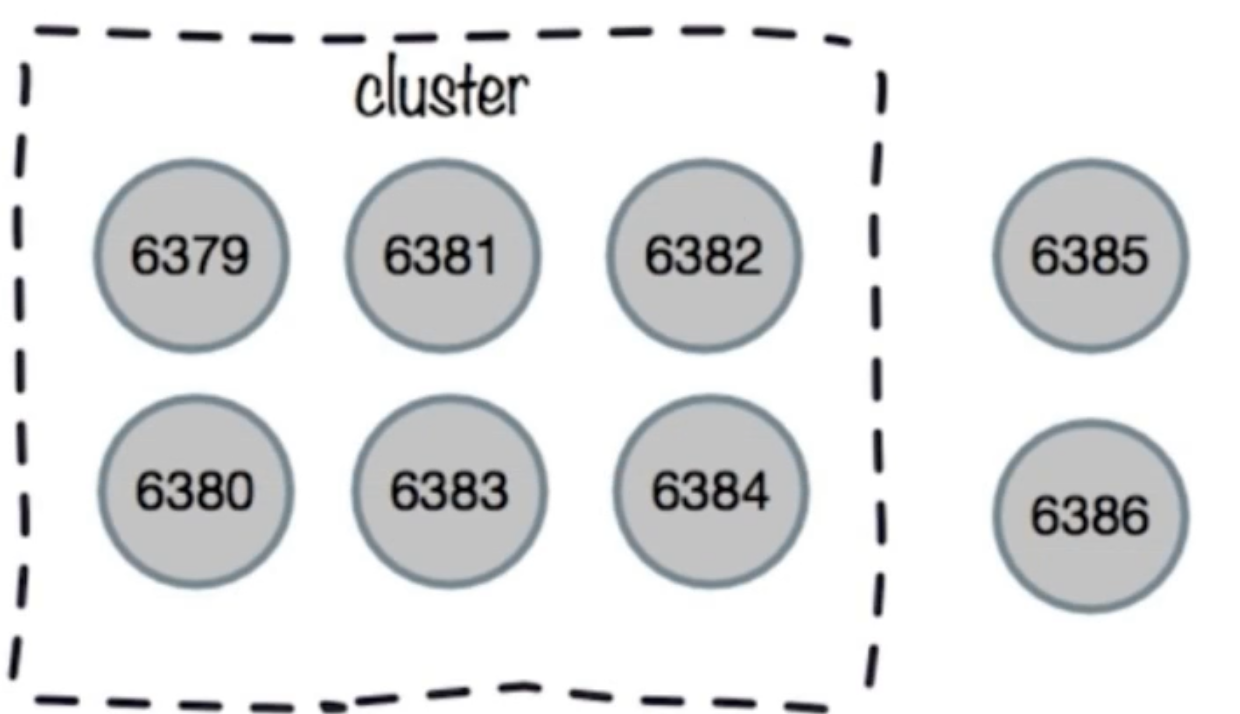
2. 加入集群(meet);
3. 迁移槽和数据;
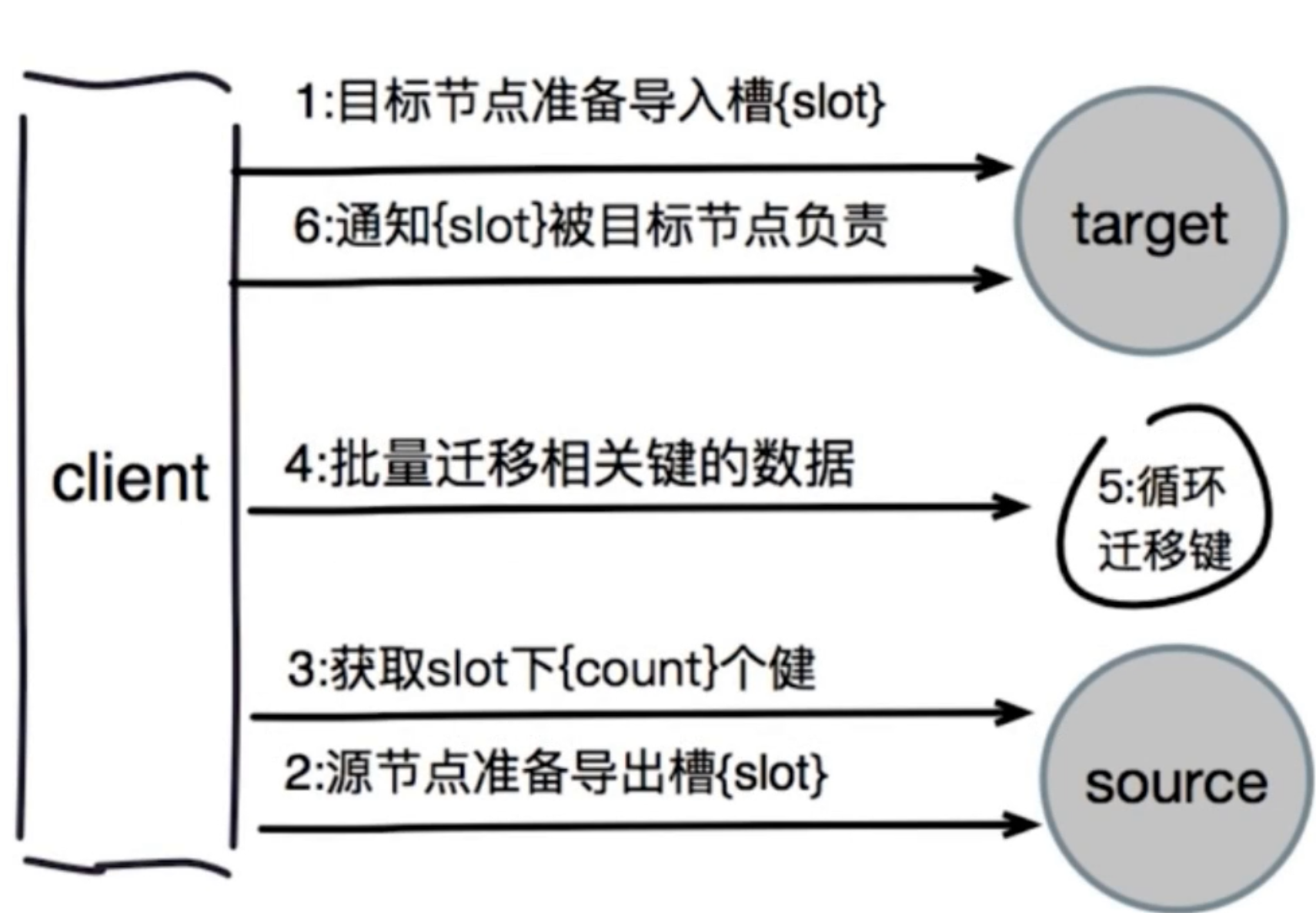
1. 槽迁移计划;
2. 迁移数据;
3. 添加从节点;
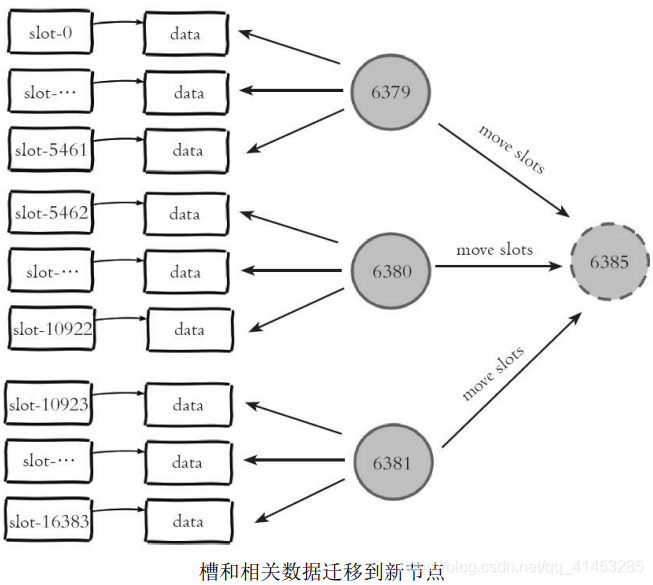
* 图中每个节点把一部分槽和数据迁移到新的节点6385,每个节点负责的槽和数据相比之前变少了从而达到了集群扩容的目的。这里我们故意忽略了槽和数据在节点之间迁移的细节,目的是想让读者重点关注在上层槽和节点分配上来,**理解集群的水平伸缩的上层原理:集群伸缩=槽和数据在节点之间的移动**
* 下面将介绍集群扩容和收缩的细节

## 加入集群作用
1. 为它迁移槽和数据实现扩容;
2. 作为从节点负责故障转移;
3. 建议使用Redis-trib.rb 能够避免新节点已经加入了其它集群,造成故障;
## 集群扩容
1. 开启集群;
```
4c0dcdf4862435f9e0b7ab9573c5d88ebce69c9e 127.0.0.1:7005@17005 slave 26cdec411e03740e81741fd1af56c84a8995e1bf 0 1606130372000 2 connected
26cdec411e03740e81741fd1af56c84a8995e1bf 127.0.0.1:7001@17001 master - 0 1606130373000 2 connected 5461-10922 //槽位
f29d5a33719410d0d965f0cd04a1aaf62772113c 127.0.0.1:7004@17004 slave e4bba455615996a2419f5ea68fb483572da69a4e 0 1606130373441 8 connected
e4bba455615996a2419f5ea68fb483572da69a4e 127.0.0.1:7000@17000 myself,master - 0 1606130370000 8 connected 0-5460
6f0a7298bd81de901ebd4989504a4d914e5002e2 127.0.0.1:7003@17003 slave 86ebe5a560dc152174ae87b4555890486aa35051 0 1606130371000 3 connected
86ebe5a560dc152174ae87b4555890486aa35051 127.0.0.1:7002@17002 master - 0 1606130372422 3 connected 10923-16383
```
2. 准备新节点;
我们准备了7006和7007两个新节点;可以看到此时它们是两个孤儿节点;并没有与集群中其他几点进行通信;
```
➜ bin redis-cli -p 7006 cluster nodes
daac46e66a8936545668c78cbe7575e6cabac310 :7006@17006 myself,master - 0 0 0 connected
➜ bin redis-cli -p 7007 cluster nodes
287b5e49634a455052c9a1ef388bc40365881be6 :7007@17007 myself,master - 0 0 0 connected
```
3. 加入集群:
```
➜ bin redis-cli -p 7000 cluster meet 127.0.0.1 7006
OK
➜ bin redis-cli -p 7000 cluster meet 127.0.0.1 7007
OK
```
查看:* 集群内新旧节点**经过一段时间的ping/pong消息通信之后,所有节点会发现新节点并将它们的状态保存到本地**。例如我们在7006节点上执行cluster nodes命令可以看到新节点信息,如下所示:
```
➜ bin redis-cli -p 7006 cluster nodes
f29d5a33719410d0d965f0cd04a1aaf62772113c 127.0.0.1:7004@17004 slave e4bba455615996a2419f5ea68fb483572da69a4e 0 1606130701061 8 connected
e4bba455615996a2419f5ea68fb483572da69a4e 127.0.0.1:7000@17000 master - 0 1606130704147 8 connected 0-5460
26cdec411e03740e81741fd1af56c84a8995e1bf 127.0.0.1:7001@17001 master - 0 1606130705178 2 connected 5461-10922
86ebe5a560dc152174ae87b4555890486aa35051 127.0.0.1:7002@17002 master - 0 1606130707231 3 connected 10923-16383
287b5e49634a455052c9a1ef388bc40365881be6 127.0.0.1:7007@17007 master - 0 1606130706202 9 connected
6f0a7298bd81de901ebd4989504a4d914e5002e2 127.0.0.1:7003@17003 slave 86ebe5a560dc152174ae87b4555890486aa35051 0 1606130704000 3 connected
4c0dcdf4862435f9e0b7ab9573c5d88ebce69c9e 127.0.0.1:7005@17005 slave 26cdec411e03740e81741fd1af56c84a8995e1bf 0 1606130702094 2 connected
daac46e66a8936545668c78cbe7575e6cabac310 127.0.0.1:7006@17006 myself,master - 0 1606130703000 0 connected
```
新节点刚开始都是主节点状态,但是由于没有负责的槽,所以不能接受任何读写操作。**对于新节点的后续操作我们一般有两种选择:**
* 为它迁移槽和数据实现扩容
* 作为其他主节点的从节点负责故障转移
4. 分配主从
```
➜ bin redis-cli -p 7007 cluster replicate daac46e66a8936545668c78cbe7575e6cabac310
OK
```
```
➜ bin redis-cli -p 7000 cluster nodes
287b5e49634a455052c9a1ef388bc40365881be6 127.0.0.1:7007@17007 slave daac46e66a8936545668c78cbe7575e6cabac310 0 1606131900000 0 connected
4c0dcdf4862435f9e0b7ab9573c5d88ebce69c9e 127.0.0.1:7005@17005 slave 26cdec411e03740e81741fd1af56c84a8995e1bf 0 1606131902172 2 connected
26cdec411e03740e81741fd1af56c84a8995e1bf 127.0.0.1:7001@17001 master - 0 1606131902000 2 connected 5461-10922
f29d5a33719410d0d965f0cd04a1aaf62772113c 127.0.0.1:7004@17004 slave e4bba455615996a2419f5ea68fb483572da69a4e 0 1606131901152 8 connected
e4bba455615996a2419f5ea68fb483572da69a4e 127.0.0.1:7000@17000 myself,master - 0 1606131901000 8 connected 0-5460
6f0a7298bd81de901ebd4989504a4d914e5002e2 127.0.0.1:7003@17003 slave 86ebe5a560dc152174ae87b4555890486aa35051 0 1606131903198 3 connected
86ebe5a560dc152174ae87b4555890486aa35051 127.0.0.1:7002@17002 master - 0 1606131903000 3 connected 10923-16383
daac46e66a8936545668c78cbe7575e6cabac310 127.0.0.1:7006@17006 master - 0 1606131901000 0 connected //此刻没有负责任何的槽位,不能读写的
```
5. 分配数据( redis-cli cluster)
```
➜ bin redis-cli --cluster reshard 127.0.01:7000
>>> Performing Cluster Check (using node 127.0.01:7000)
M: e4bba455615996a2419f5ea68fb483572da69a4e 127.0.01:7000
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 287b5e49634a455052c9a1ef388bc40365881be6 127.0.0.1:7007
slots: (0 slots) slave
replicates daac46e66a8936545668c78cbe7575e6cabac310
S: 4c0dcdf4862435f9e0b7ab9573c5d88ebce69c9e 127.0.0.1:7005
slots: (0 slots) slave
replicates 26cdec411e03740e81741fd1af56c84a8995e1bf
M: 26cdec411e03740e81741fd1af56c84a8995e1bf 127.0.0.1:7001
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: f29d5a33719410d0d965f0cd04a1aaf62772113c 127.0.0.1:7004
slots: (0 slots) slave
replicates e4bba455615996a2419f5ea68fb483572da69a4e
S: 6f0a7298bd81de901ebd4989504a4d914e5002e2 127.0.0.1:7003
slots: (0 slots) slave
replicates 86ebe5a560dc152174ae87b4555890486aa35051
M: 86ebe5a560dc152174ae87b4555890486aa35051 127.0.0.1:7002
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: daac46e66a8936545668c78cbe7575e6cabac310 127.0.0.1:7006
slots: (0 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 4096 //询问迁移多少个槽位
What is the receiving node ID? daac46e66a8936545668c78cbe7575e6cabac310 //目标节点的ID,就是新加入节点的runid(master)
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: all //从所有主库中移出对应的槽值个数
Do you want to proceed with the proposed reshard plan (yes/no)? yes //是否继续
```
查看
```
➜ bin redis-cli -p 7000 cluster nodes | grep master
26cdec411e03740e81741fd1af56c84a8995e1bf 127.0.0.1:7001@17001 master - 0 1606132876000 2 connected 6827-10922
e4bba455615996a2419f5ea68fb483572da69a4e 127.0.0.1:7000@17000 myself,master - 0 1606132877000 8 connected 1365-5460
86ebe5a560dc152174ae87b4555890486aa35051 127.0.0.1:7002@17002 master - 0 1606132876771 3 connected 12288-16383
daac46e66a8936545668c78cbe7575e6cabac310 127.0.0.1:7006@17006 master - 0 1606132874715 10 connected 0-1364 5461-6826 10923-12287 //可以看出,之前的每个节点都让出了一部分槽位给新加入集群的master节点
```
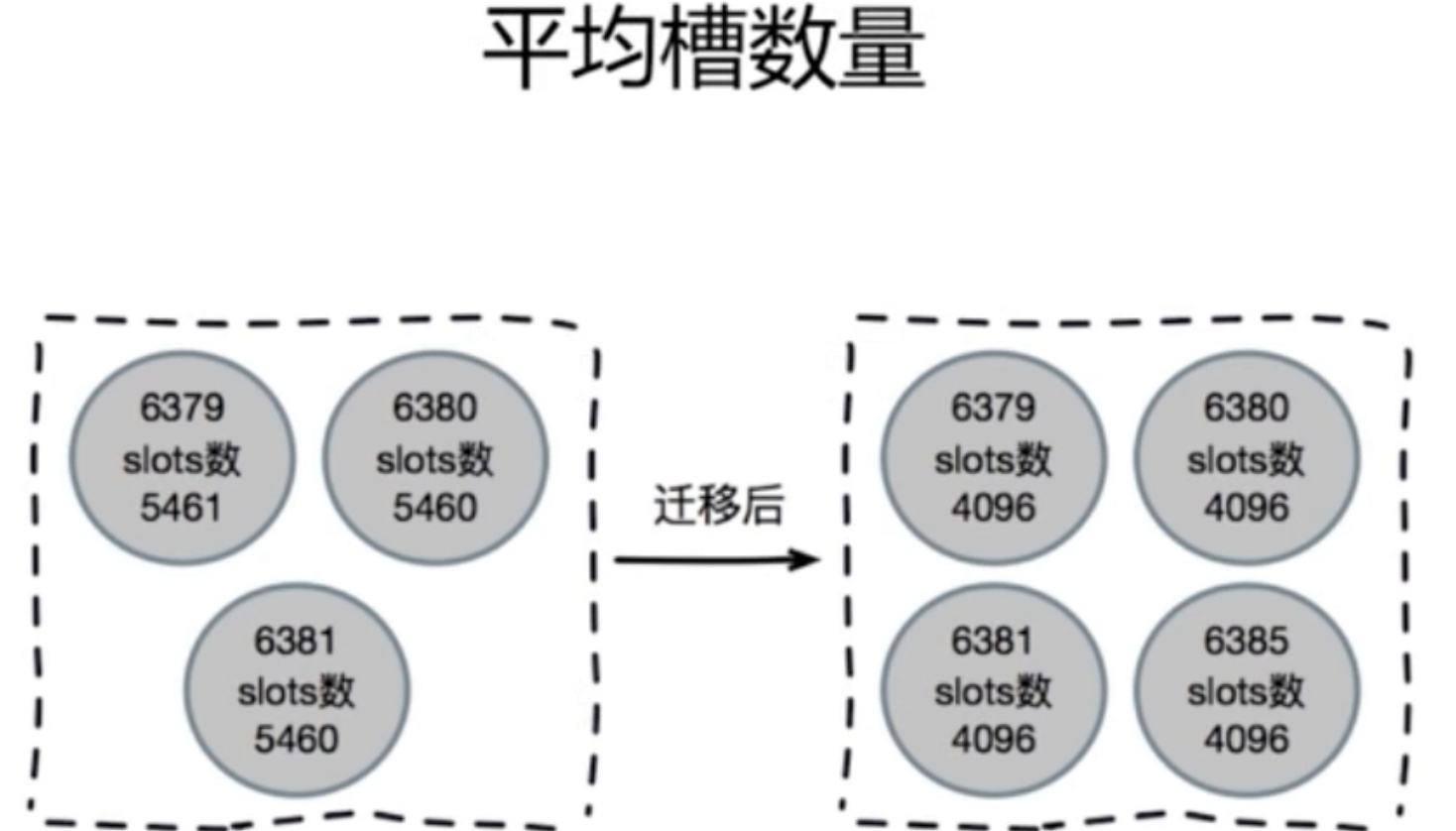
由于槽用于hash运算本身顺序没有意义,因此无须强制要求节点负责槽的顺序性。迁移之后建议使用下面的命令检查节点之间槽的均衡性。命令如下:
```
➜ bin redis-cli --cluster rebalance 127.0.0.1:7000
```
结果
```
>>> Performing Cluster Check (using node 127.0.0.1:7000)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.00% threshold. //2%
```
* 通过上图可以看出迁移之后**所有主节点负责的槽数量差异在2%以内,因此集群节点数据相对均匀,无需调整**
- Redis简介
- 简介
- 典型应用场景
- Redis安装
- 安装
- redis可执行文件说明
- 三种启动方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 数据结构和内部编码
- 单线程
- 数据类型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查询
- Pipline
- 发布订阅
- Bitmap
- Hyperloglog
- GEO
- 持久化机制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉择
- 开发运维常见问题
- fork操作
- 子进程外开销
- AOF追加阻塞
- 单机多实例部署
- Redis复制原理和优化
- 什么是主从复制
- 主从复制配置
- 全量复制和部分复制
- 故障处理
- 开发运维常见问题
- Sentinel
- 主从复制高可用
- 架构说明
- 安装配置
- 客户端连接
- 实现原理
- 常见开发运维问题
- 高可用读写分离
- 故障转移client怎么知道新的master地址
- 总结
- Sluster
- 呼唤集群
- 数据分布
- 搭建集群
- 集群通信
- 集群扩容
- 集群缩容
- 客户端路由
- 故障转移
- 故障发现
- 故障恢复
- 开发运维常见问题
- 缓存设计与优化
- 缓存收益和成本
- 缓存更新策略
- 缓存粒度控制
- 缓存穿透优化
- 缓存雪崩优化
- 无底洞问题优化
- 热点key重建优化
- 总结
- 布隆过滤器
- 引出布隆过滤器
- 布隆过滤器基本原理
- 布隆过滤器误差率
- 本地布隆过滤器
- Redis布隆过滤器
- 分布式布隆过滤器
- 开发规范
- 内存管理
- 开发运维常见坑
- 实战
- 对文章进行投票
- 数据库的概念
- 启动多实例