
## 集群完整性
```
cluster-require-full-coverage 默认为yes
```
* 为了保证集群完整性,默认情况下当集群**16384个槽任何一个没有指派到节点时整个集群不可用**。**执行任何键命令返回**(error)CLUSTERDOWN Hash slot not served错误
* 这是对集群完整性的一种保护措施,保证所有的槽都指派给在线的节点。但是当持有槽的主节点下线时,从故障发现到自动完成转移期间整个集群是不可用状态,对于大多数业务无法容忍这种情况, 因此建议**将参数cluster-require-full-coverage配置为no,当主节点故障时只影响它负责槽的相关命令执行,不会影响其他主节点的可用性**
## 带宽消耗
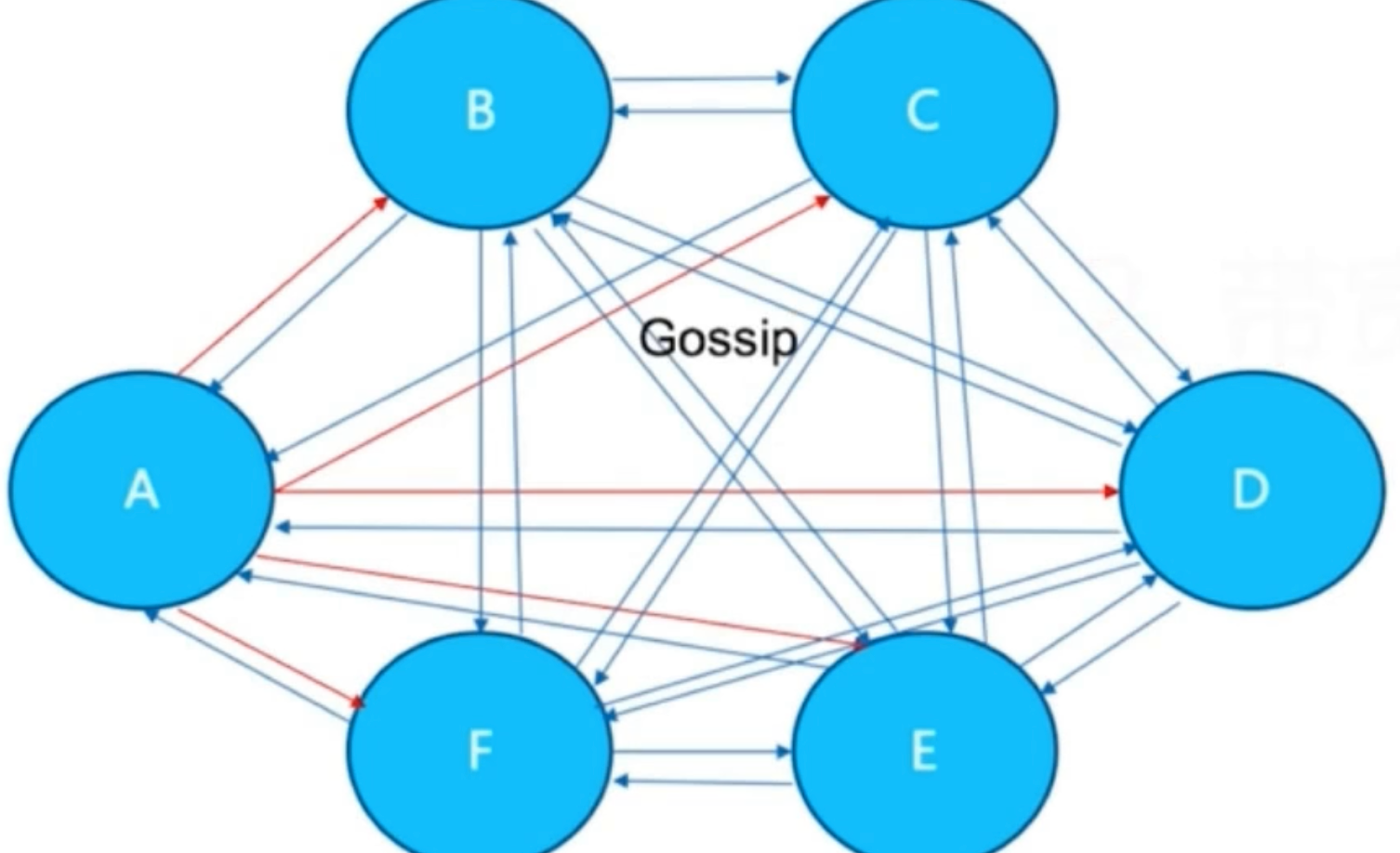
* 集群内Gossip消息通信本身会消耗带宽,**官方建议集群最大规模在1000以内**,也是出于对消息通信成本的考虑,因此单集群不适合部署超大规模的节点
* 在之前的文章介绍到,**集群内所有节点通过ping/pong消息彼此交换信息,节点间消息通信对带宽的消耗体现在以下几个方面:**
* 消息发送频率:跟cluster-node-timeout密切相关,当节点发现与其他节 点最后通信时间超过cluster-node-timeout/2时会直接发送ping消息
* 消息数据量:每个消息主要的数据占用包含:slots槽数组(2KB空 间)和整个集群1/10的状态数据(10个节点状态数据约1KB)
* 节点部署的机器规模:机器带宽的上线是固定的,因此相同规模的集 群分布的机器越多每台机器划分的节点越均匀,则集群内整体的可用带宽越高
* 例如,一个总节点数为200的Redis集群,部署在20台物理机上每台划分 10个节点,cluster-node-timeout采用默认15秒,这时ping/pong消息占用带宽 达到25Mb。如果把cluster-node-timeout设为20,对带宽的消耗降低到15Mb以 下
* **集群带宽消耗主要分为:**读写命令消耗+Gossip消息消耗。**因此搭建Redis集群时需要根据业务数据规模和消息通信成本做出合理规划:**
* **1)在满足业务需要的情况下尽量避免大集群**。同一个系统可以针对不 同业务场景拆分使用多套集群。这样每个集群既满足伸缩性和故障转移要求,还可以规避大规模集群的弊端。如笔者维护的一个推荐系统,根据数据 特征使用了5个Redis集群,每个集群节点规模控制在100以内
* 2)**适度提高cluster-node-timeout降低消息发送频率,同时cluster-nodetimeout还影响故障转移的速度**,因此需要根据自身业务场景兼顾二者的平衡
* **3)如果条件允许集群尽量均匀部署在更多机器上**。避免集中部署,如集群有60个节点,集中部署在3台机器上每台部署20个节点,这时机器带宽 消耗将非常严重
## Pub/Sub广播
* Redis在2.0版本提供了Pub/Sub(发布/订阅)功能,用于针对频道实现 消息的发布和订阅。但是在集群模式下内部实现对所有的publish命令都会向 所有的节点进行广播,造成每条publish数据都会在集群内所有节点传播一 次,加重带宽负担,如图所示:
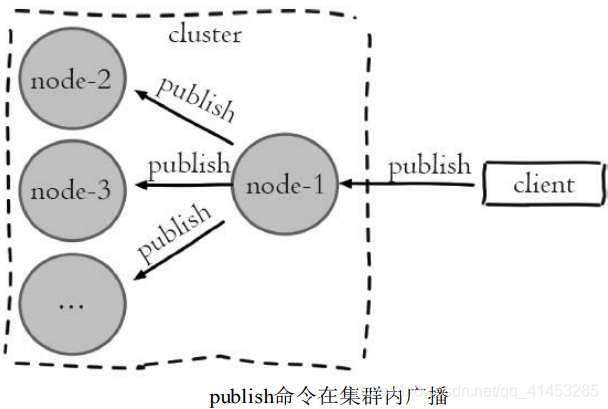
* 针对集群模式下publish广播问题,需要引起开发人员注意,当频繁应用 Pub/Sub功能时应该避免在大量节点的集群内使用,否则会严重消耗集群内网络带宽。针对这种情况**建议使用sentinel结构专门用于Pub/Sub功能,**从而规避这一问题
## 数据倾斜
* 集群倾斜指不同节点之间数据量和请求量出现明显差异,这种情况将加大负载均衡和开发运维的难度。因此需要理解哪些原因会造成集群倾斜,从 而避免这一问题
### ①数据倾斜
* **数据倾斜主要分为以下几种:**
* **节点和槽分配严重不均**
* **不同槽对应键数量差异过大**
* **集合对象包含大量元素**
* **内存相关配置不一致**
* **1)节点和槽分配严重不均**。针对每个节点分配的槽不均的情况,可以使用redis-trib.rb info {host:ip}进行定位,命令如下:
```
➜ bin redis-cli --cluster info 127.0.0.1:7000
127.0.0.1:7000 (e4bba455...) -> 0 keys | 6493 slots | 1 slaves.
127.0.0.1:7001 (26cdec41...) -> 0 keys | 6459 slots | 1 slaves.
127.0.0.1:7002 (86ebe5a5...) -> 2 keys | 3432 slots | 1 slaves.
```
* 以上信息列举出每个节点负责的槽和键总量以及每个槽平均键数量。当节点对应槽数量不均匀时,可以使用redis --cluster rebalance命令进行平衡(谨慎使用,虽然有智能客户端,但是计划好了再操作):
```
➜ bin redis-cli --cluster rebalance 127.0.0.1:7000
>>> Performing Cluster Check (using node 127.0.0.1:7000)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
>>> Rebalancing across 3 nodes. Total weight = 3.00
```
效果:
```
➜ bin redis-cli --cluster info 127.0.0.1:7000
127.0.0.1:7000 (e4bba455...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:7001 (26cdec41...) -> 0 keys | 5461 slots | 1 slaves.
127.0.0.1:7002 (86ebe5a5...) -> 2 keys | 5462 slots | 1 slaves.
```
* **2)不同槽对应键数量差异过大**。键通过CRC16哈希函数映射到槽上, 正常情况下槽内键数量会相对均匀。但当大量使用hash\_tag时,会产生不同 的键映射到同一个槽的情况。特别是选择作为hash\_tag的数据离散度较差时,将加速槽内键数量倾斜情况。通过命令:cluster countkeysinslot{slot}可 以获取槽对应的键数量,识别出哪些槽映射了过多的键。再通过命令cluster getkeysinslot{slot}{count}循环迭代出槽下所有的键。从而发现过度使用 hash\_tag的键。
* **3)集合对象包含大量元素**。对于大集合对象的识别可以使用redis-cli-- bigkeys命令识别,具体使用见后面“寻找热点key”的文章。找出大集合之后可以根据业务场景进 行拆分。同时集群槽数据迁移是对键执行migrate操作完成,过大的键集合如 几百兆,容易造成migrate命令超时导致数据迁移失败
* **4)内存相关配置不一致**。内存相关配置指hash-max-ziplist-value、setmax-intset-entries等压缩数据结构配置。当集群大量使用hash、set等数据结构 时,如果内存压缩数据结构配置不一致,极端情况下会相差数倍的内存,从而造成节点内存量倾斜;
### ②请求倾斜
* 集群内**特定节点请求量/流量过大将导致节点之间负载不均**,影响集群均衡和运维成本。常出现在热点键场景,当键命令消耗较低时如小对象的 get、set、incr等,即使请求量差异较大一般也不会产生负载严重不均。但是当**热点键对应高算法复杂度的命令或者是大对象操作如hgetall、smembers等,会导致对应节点负载过高**的情况
* **避免方式如下:**
* 1)合理设计键,热点大集合对象做拆分或使用hmget替代hgetall避免整 体读取
* 2)不要使用热键作为hash_tag,避免映射到同一槽
* 3)对于一致性要求不高的场景,客户端可使用本地缓存减少热键调 用
## 读写分离
使用cluster进行读写分离的成本是非常高的,需要手动去实现一个这样的客户端,不如多加节点规模;
### 只读连接
* **集群模式下从节点不接受任何读写请求,**发送过来的键命令会重定向到负责槽的主节点上(其中包括它的主节点)
* **readonly命令(只读模式):**
* 当需要使用从节点分担主节点读压力时,可以**使用readonly命令打开客户端连接只读状态**。之前的复制配置slave-read-only在集群模式下无效
* 当开启只读状态时,从节点接收读命令处理流程变为:**如果对应的槽属于自己正在复制的主节点则直接执行读命令,否则返回重定向信息**
```
➜ ~ redis-cli -c -p 7003 //连接的是从节点
127.0.0.1:7003> get hello
-> Redirected to slot [866] located at 127.0.0.1:7002 //但是重定向到了相关的主节点
"wrold"
127.0.0.1:7002>
```
```
➜ ~ redis-cli -c -p 7003
127.0.0.1:7003> readonly //进行readonly,每次读的时候都需要输入
OK
127.0.0.1:7003> get hello
"wrold" //直接从从节点返回结果了,并没有重定向
```
* **readonly命令是连接级别生效,**因此每次新建连接时都需要执行readonly开启只读状态。执行readwrite命令可以关闭连接只读状态
### 读写分离
* **集群模式下的读写分离,同样会遇到:**复制延迟,读取过期数据,从节点故障等问题(具体细节见前面“复制”一系列文章)
* **针对从节点故障问题,客户端需要维护可用节点列表,**集群提供了cluster slaves {nodeId}命令,返回nodeId对应主节点下所有从节点信息,数据格式同cluster nodes,命令如下:
```
➜ ~ redis-cli -p 7000 cluster slaves 26cdec411e03740e81741fd1af56c84a8995e1bf
1) "4c0dcdf4862435f9e0b7ab9573c5d88ebce69c9e 127.0.0.1:7005@17005 slave 26cdec411e03740e81741fd1af56c84a8995e1bf 0 1606207496756 15 connected"
```
* **解析以上从节点列表信息,排除fail状态节点,**这样客户端对从节点的故障判定可以委托给集群处理,简化维护可用从节点列表难度
* **开发提示:**集群模式下读写分离涉及对客户端修改如下:
* 1)维护每个主节点可用从节点列表
* 2)针对读命令维护请求节点路由
* 3)从节点新建连接开启readonly状态
* 集群模式下读写分离成本比较高,可以直接扩展主节点数量提高集群性能,**一般不建议集群模式下做读写分离**
* **集群读写分离有时用于特殊业务场景如:**
* 1)利用复制的最终一致性使用多个从节点做跨机房部署降低读命令网络延迟
* 2)主节点故障转移时间过长,业务端把读请求路由给从节点保证读操作可用
* 以上场景也可以在不同机房独立部署Redis集群解决,通过客户端多写来维护,读命令直接请求到最近机房的Redis集群,或者当一个集群节点故 障时客户端转向另一个集群
## 离线/在线数据迁移
* 应用Redis集群时,常需要**把单机Redis数据迁移到集群环境**
* **redis-cli --cluster命令提供了导入功能,**用于数据从单机向集群环境迁移的场景,命令如下:
```
redis-cli import host:port --cluster-from <arg> --cluster-copy --cluster-replace
```
* **上面的命令内部采用批量scan和migrate的方式迁移数据。这种迁移方式存在以下缺点:**
* 1)迁移只能从单机节点向集群环境导入数据
* 2)不支持在线迁移数据,迁移数据时应用方必须停写,无法平滑迁移数据
* 3)迁移过程中途如果出现超时等错误,不支持断点续传只能重新全量导入
* 4)使用单线程进行数据迁移,大数据量迁移速度过慢
* **正因为这些问题,社区开源了很多迁移工具**,这里推荐一款唯品会开发的redis-migrate-tool,该工具可满足大多数Redis迁移需求,特点如下:
* 支持单机、Twemproxy、Redis Cluster、RDB/AOF等多种类型的数据迁移
* 工具模拟成从节点基于复制流迁移数据,从而支持在线迁移数据,业务方不需要停写
* 采用多线程加速数据迁移过程且提供数据校验和查看迁移状态等功 能
* 更多细节见GitHub:[https://github.com/vipshop/redis-migrate-tool](https://github.com/vipshop/redis-migrate-tool)
## 集群VS单机对比
### 集群限制
1. key批量操作支持有限:例如mget,mset必须在一个slot;
2. key事务和Lua支持有限:操作的key必须在一个节点;
3. key是数据分区的最小粒度:不支持bigkey分区;
4. 不支持多个数据库:集群下只有一个db0;
5. 复制只支持一层:不支持树形复制结构;
### 分布式Redis不一定好
1. Redis cluster:满足容量和性能的扩展性,很多业务"不需要":
1.大多数时客户端性能会'降低'
2.命令无法跨节点使用:mget,keys,scan,flush,sinter等;
3.Lua和事务无法跨节点使用;
4.客户端维护更复杂:SDK和应用本身消耗(例如更多的连接池)
2. 很多场景Redis sentinel已经足够好.
1.业务量不是非常大可以使用;
2.几万的OPS已经足够了;
- Redis简介
- 简介
- 典型应用场景
- Redis安装
- 安装
- redis可执行文件说明
- 三种启动方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 数据结构和内部编码
- 单线程
- 数据类型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查询
- Pipline
- 发布订阅
- Bitmap
- Hyperloglog
- GEO
- 持久化机制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉择
- 开发运维常见问题
- fork操作
- 子进程外开销
- AOF追加阻塞
- 单机多实例部署
- Redis复制原理和优化
- 什么是主从复制
- 主从复制配置
- 全量复制和部分复制
- 故障处理
- 开发运维常见问题
- Sentinel
- 主从复制高可用
- 架构说明
- 安装配置
- 客户端连接
- 实现原理
- 常见开发运维问题
- 高可用读写分离
- 故障转移client怎么知道新的master地址
- 总结
- Sluster
- 呼唤集群
- 数据分布
- 搭建集群
- 集群通信
- 集群扩容
- 集群缩容
- 客户端路由
- 故障转移
- 故障发现
- 故障恢复
- 开发运维常见问题
- 缓存设计与优化
- 缓存收益和成本
- 缓存更新策略
- 缓存粒度控制
- 缓存穿透优化
- 缓存雪崩优化
- 无底洞问题优化
- 热点key重建优化
- 总结
- 布隆过滤器
- 引出布隆过滤器
- 布隆过滤器基本原理
- 布隆过滤器误差率
- 本地布隆过滤器
- Redis布隆过滤器
- 分布式布隆过滤器
- 开发规范
- 内存管理
- 开发运维常见坑
- 实战
- 对文章进行投票
- 数据库的概念
- 启动多实例