
## 说明
* Redis集群自身实现了高可用。高可用首先需要解决集群部分失败的场景:当集群内少量节点出现故障时通过自动故障转移保证集群可以正常对外提供服务。本文介绍故障转移的细节,分析故障发现和替换故障节点的过程
## 故障发现
1. 通过ping/pong奥西实现故障发现,不需要sentinel;
2. 主观下线和客观下线;
* **当集群内某个节点出现问题时,需要通过一种健壮的方式保证识别出节点是否发生了故障**。Redis集群内节点通过ping/pong消息实现节点通信,消 息不但可以传播节点槽信息,还可以传播其他状态如:主从状态、节点故障等
* **因此故障发现也是通过消息传播机制实现的,主要环节包括:**
* **主观下线 (pfail):**指某个节点认为另一个节点不可用,即下线状态,这个状态并不是最终的故障判定,只能代表一个节点的意见,可能存在误判情况
* **客观下线(fail):**指标记一个节点真正的下线,集群内多个节点都认为该节点不可用,从而达成共识的结果。如果是持有槽的主节点故障,需要为该节点进行故障转移
## 主观下线
* 集群中每个节点都会定期向其他节点发送ping消息,接收节点回复pong消息作为响应。**如果在cluster-node-timeout时间内通信一直失败,则发送节点会认为接收节点存在故障**,把接收节点标记为**主观下线(pfail)状态** 主观下线是带有"偏见"的,是单独一个节点认为某个节点下线了;不代表所有节点的认知;
* **流程如下图所示:**
* 1)节点a发送ping消息给节点b,如果通信正常将接收到pong消息,节点a更新最近一次与节点b的通信时间
* 2)如果节点a与节点b通信出现问题则断开连接,下次会进行重连。如果一直通信失败,则节点a记录的与节点b最后通信时间将无法更新
* 3)节点a内的定时任务检测到与节点b最后通信时间超高cluster-nodetimeout时,更新本地对节点b的状态为主观下线(pfail)
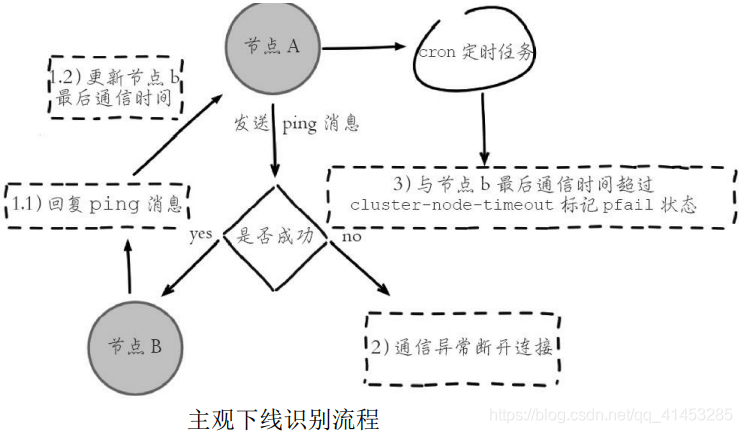
* 主观下线简单来讲就是,**当cluster-note-timeout时间内某节点无法与另一个节点顺利完成ping消息通信时,则将该节点标记为主观下线状态**。每个节点内的cluster State结构都需要保存其他节点信息,用于从自身视角判断其他节点的状态。
* **Redis集群对于节点最终是否故障判断非常严谨,只有一个节点认为主观下线并不能准确判断是否故障**。例如下图所示的场景,节点6379与6385通信中断,导致6379判断6385为主观下线状态,但是 6380与6385节点之间通信正常,这种情况不能判定节点6385发生故
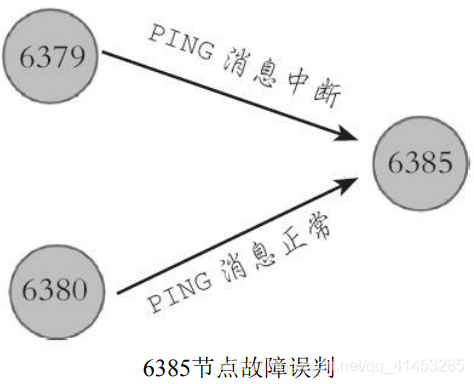
* **因此对于一个健壮的故障发现机制,需要集群内大多数节点都判断6385故障时, 才能认为6385确实发生故障,**然后为6385节点进行故障转移。而这种**多个节点协作完成故障发现的过程叫做客观下线**
## 客观下线
1. 当半数以上持有槽的主节点都标记某节点主观下线就认为是客观下线;
2. 客观下线逻辑流程:
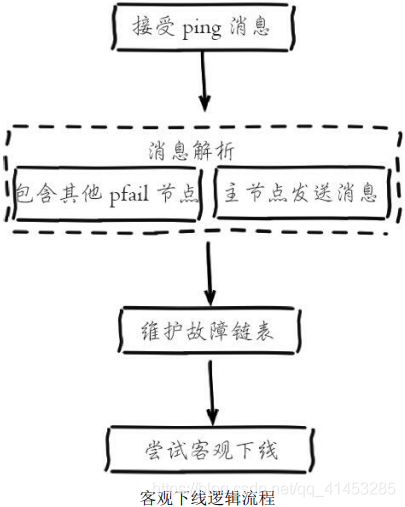
* **当某个节点判断另一个节点主观下线后,相应的节点状态会跟随消息在集群内传播**。ping/pong消息的消息体会携带集群1/10的其他节点状态数据, 当接受节点发现消息体中含有主观下线的节点状态时,会在本地找到故障节点的ClusterNode结构,保存到下线报告链表中。
* * 通过Gossip消息传播,集群内节点不断收集到故障节点的下线报告。**当半数以上持有槽的主节点都标记某个节点是主观下线时。触发客观下线流程**。这里有两个疑问:
* **1)为什么必须是负责槽的主节点参与故障发现决策?**因为集群模式下只有处理槽的主节点才负责读写请求和集群槽等关键信息维护,而从节点只 进行主节点数据和状态信息的复制
* **2)为什么半数以上处理槽的主节点?**必须半数以上是为了应对网络分 区等原因造成的集群分割情况,被分割的小集群因为无法完成从主观下线到 客观下线这一关键过程,从而防止小集群完成故障转移之后继续对外提供服务
* 假设节点a标记节点b为主观下线,**一段时间后节点a通过消息把节点b的状态发送到其他节点,当节点c接受到消息并解析出消息体含有节点b的pfail状态时,会触发客观下线流程**,如下图所示:
* 1)当消息体内含有其他节点的pfail状态会判断发送节点的状态,**如果发送节点是主节点则对报告的pfail状态处理,从节点则忽略**
* 2)找到pfail对应的节点结构,更新clusterNode内部下线报告链表
* 3)根据更新后的下线报告链表告尝试进行客观下线
## 维护下线报告链表
* 每个节点ClusterNode结构中都会存在一个**下线链表结构,保存了其他主节点针对当前节点的下线报告**
* 下线报告中保存了报告故障的节点结构和最近收到下线报告的时间,当接收到fail状态时,会维护对应节点的下线上报链表
* 每个下线报告都存在有效期:****每次在尝试触发客观下线时,都会检测下线报告是否过期,对于过期的下线报告将被删除。如果在cluster-node-time\*2的时间内该下线报告没有得到更新则过期并删除,
* 下线报告的有效期限是server.cluster\_node\_timeout\*2,**主要是针对故障误报的情况**。例如节点A在上一小时报告节点B主观下线,但是之后又恢复正常。现在又有其他节点上报节点B主观下线,根据实际情况之前的属于误报不能被使用
* 运维提示:如果在cluster-node-time\*2时间内无法收集到一半以上槽节点的下线报告,那么之前的下线报告将会过期,也就是说主观下线上报的速度追赶不上下线报告过期的速度,那么故障节点将永远无法被标记为客观下线从而导致故障转移失败。**因此不建议将cluster-node-time设置得过小**
## 尝试客观下线
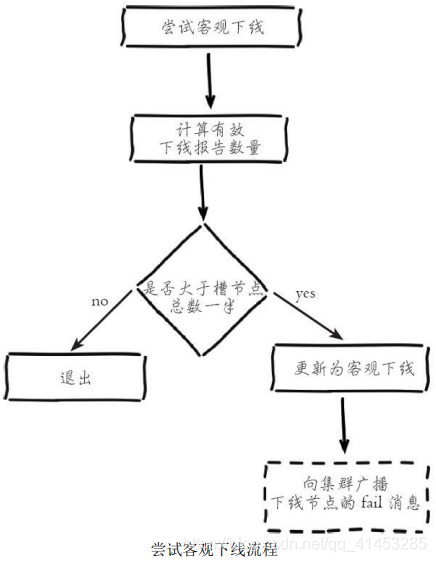
**集群中的节点每次接收到其他节点的pfail状态,都会尝试触发客观下线,流程如下图所示:**
* 1)首先统计有效的下线报告数量,如果**小于集群内持有槽的主节点总数的一半则退出**
* 2)**当下线报告大于槽主节点数量一半时,**标记对应故障节点为客观下线状态
* 3)**向集群广播一条fail消息,**通知所有的节点将故障节点标记为客观下线,fail消息的消息体只包含故障节点的ID
* **广播fail消息是客观下线的最后一步,它承担着非常重要的职责:**
* 通知集群内所有的节点标记故障节点为客观下线状态并立刻生效
* 通知故障节点的从节点触发故障转移流程
* **需要理解的是,尽管存在广播fail消息机制,但是集群所有节点知道故障节点进入客观下线状态是不确定的**。比如当出现网络分区时有可能集群被分割为一大一小两个独立集群中。大的集群持有半数槽节点可以完成客观下线并广播fail消息,但是小集群无法接收到fail消息,如下图所示:
* 但是当网络恢复后,只要故障节点变为客观下线,最终**总会通过Gossip消息传播至集群的所有节点**
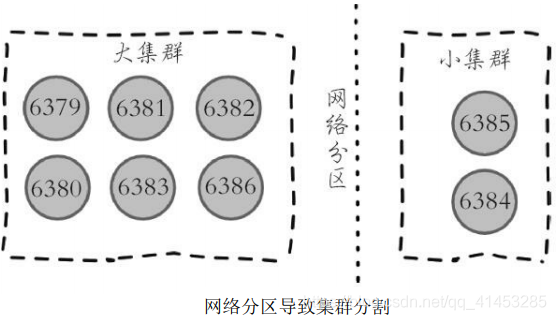
* 运维提示:网络分区会导致分割后的小集群无法收到大集群的fail消息,因此如果故障节点所有的从节点都在小集群内将导致无法完成后续故障转移,**因此部署主从结构时需要根据自身机房/机架拓扑结构,降低主从被分区的可能性**
- Redis简介
- 简介
- 典型应用场景
- Redis安装
- 安装
- redis可执行文件说明
- 三种启动方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 数据结构和内部编码
- 单线程
- 数据类型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查询
- Pipline
- 发布订阅
- Bitmap
- Hyperloglog
- GEO
- 持久化机制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉择
- 开发运维常见问题
- fork操作
- 子进程外开销
- AOF追加阻塞
- 单机多实例部署
- Redis复制原理和优化
- 什么是主从复制
- 主从复制配置
- 全量复制和部分复制
- 故障处理
- 开发运维常见问题
- Sentinel
- 主从复制高可用
- 架构说明
- 安装配置
- 客户端连接
- 实现原理
- 常见开发运维问题
- 高可用读写分离
- 故障转移client怎么知道新的master地址
- 总结
- Sluster
- 呼唤集群
- 数据分布
- 搭建集群
- 集群通信
- 集群扩容
- 集群缩容
- 客户端路由
- 故障转移
- 故障发现
- 故障恢复
- 开发运维常见问题
- 缓存设计与优化
- 缓存收益和成本
- 缓存更新策略
- 缓存粒度控制
- 缓存穿透优化
- 缓存雪崩优化
- 无底洞问题优化
- 热点key重建优化
- 总结
- 布隆过滤器
- 引出布隆过滤器
- 布隆过滤器基本原理
- 布隆过滤器误差率
- 本地布隆过滤器
- Redis布隆过滤器
- 分布式布隆过滤器
- 开发规范
- 内存管理
- 开发运维常见坑
- 实战
- 对文章进行投票
- 数据库的概念
- 启动多实例