
## 什么是缓存穿透
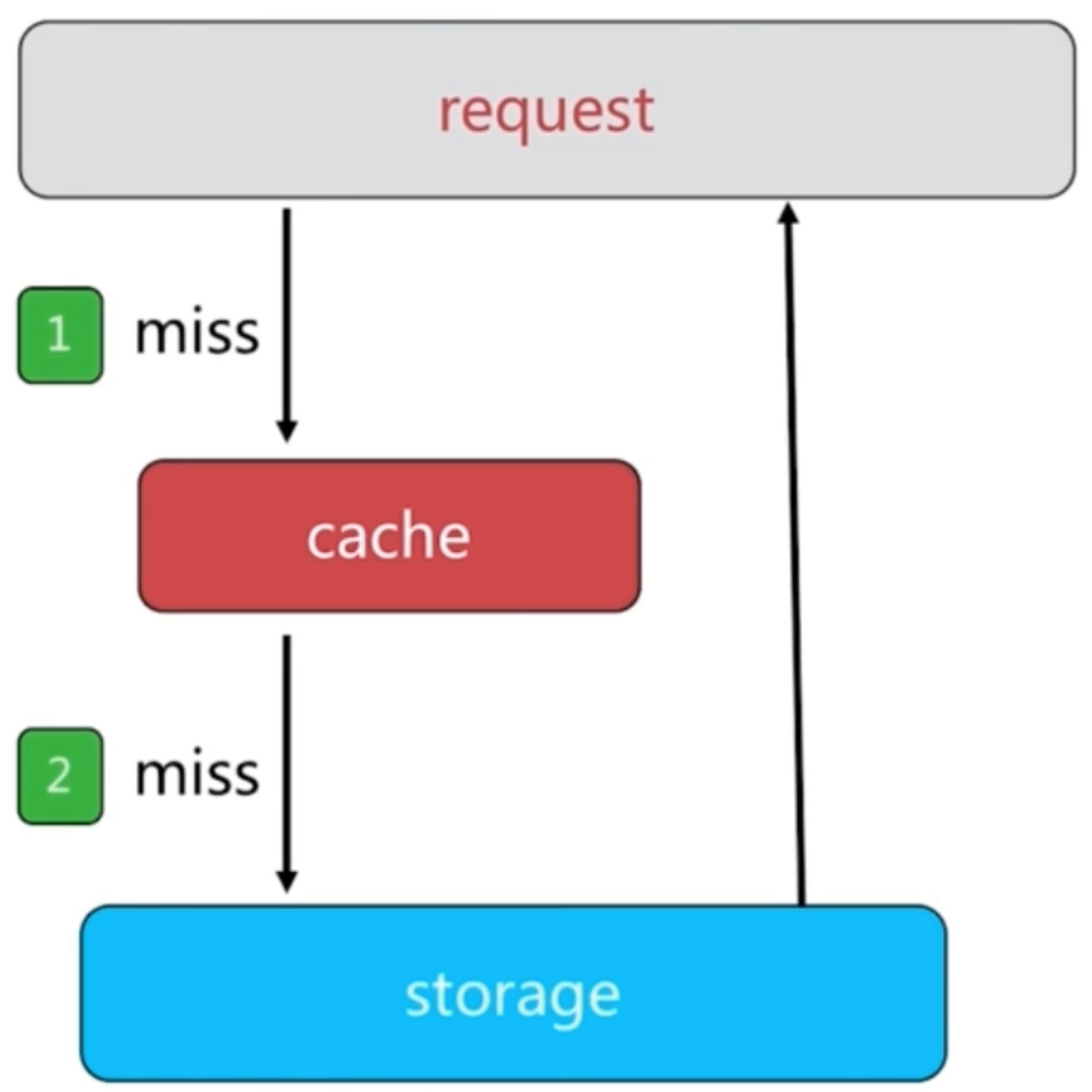
缓存穿透是指**查询一个根本不存在的数据,缓存层和存储层都不会命中**,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层,整个过程分为下图3步:
* 1)缓存层不命中;
* 2)存储层不命中,不将空结果写回缓存;
* 3)返回空结果;
* **缓存穿透带来的问题:**
* ①缓存穿透将导致不存在的数据每次请求都要到存储层去查询,**失去了缓存保护后端存储的意义**;
* ②缓存穿透问题可能会**使后端存储负载加大**,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题;
* **造成缓存穿透的基本原因有两个:**
* 第一,自身业务代码或者数据出现问题;
* 第二,一些恶意攻击、爬虫等造成大量空命中;
## 如何发现
1. 业务的响应时间;
2. 业务本身问题;
3. 相关指标:总调用数,缓存层命中数,存储层命中数;
## 解决方法1--缓存空对象
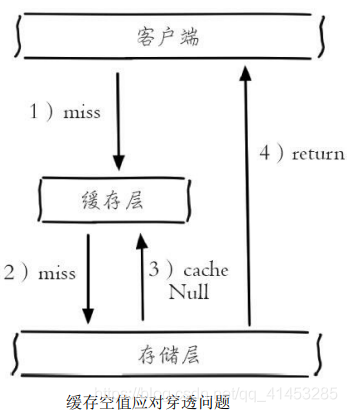
* **概念**:当第2步存储层不命中后,**仍然将空对象保留到缓存层中**,之后再访问这个数据将会从缓存中获取,这样就保护了后端数据源;
**缓存空对象会有两个问题:**
* 第一,空值做了缓存,意味着缓存层中存了更多的键,**需要更多的内存空间**(如果是攻击,问题更严重),比较有效的方法是针对这类数据**设置一个较短的过期时间,让其自动剔除**
* 第二,**缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。**例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以**利用消息系统或者其他方式清除掉缓存层中的空对象**
```
String get(String key) {
// 从缓存中获取数据
String cacheValue = cache.get(key);
// 缓存为空
if (StringUtils.isBlank(cacheValue))
{
// 从存储中获取
String storageValue = storage.get(key);
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
}
else {
//缓存非空
return cacheValue;
}
}
```
## 解决方法2--布隆过滤器
* 如下图所示,在访问缓存层和存储层之前,**将存在的key用布隆过滤器提前保存起来,做第一层拦截**
* **例如**:一个推荐系统有4亿个用户id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以**将所有推荐数据的用户**做成布隆过滤器。如果布隆过滤器**认为该用户id不 存在,那么就不会访问存储层,在一定程度保护了存储层**
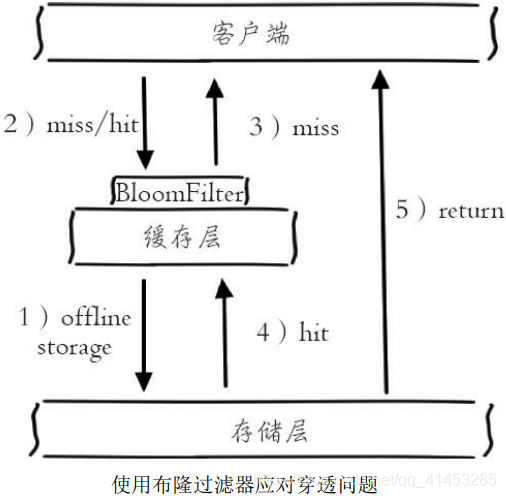
* 这种方法**适用于数据命中不高、数据相对固定、实时性低(通常是数据集较大)的应用场景**,代码维护较为复杂,但是缓存空间占用少
* **备注信息:**
* 关于布隆过滤器的介绍可以参阅:[https://blog.csdn.net/qq\_41453285/article/details/106416470](https://blog.csdn.net/qq_41453285/article/details/106416470)
* 可以参考:[https://en.wikipedia.org/wiki/Bloom\_filter](https://en.wikipedia.org/wiki/Bloom_filter)可以利用Redis的Bitmaps实现布隆过滤器,GitHub上已经开源了类似的方案,读者可以进行参考:[https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter](https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter)
## # 两种方案对比
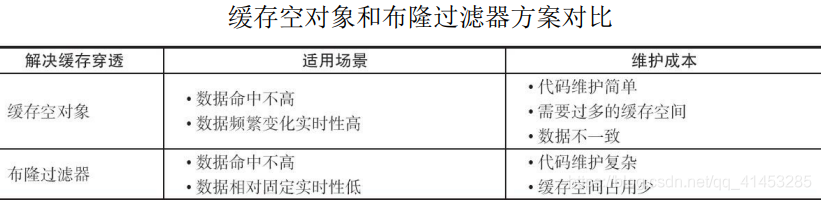
* 前面介绍了缓存穿透问题的两种解决方法(实际上这个问题是一个开放问题,有很多解决方法),下图从适用场景和维护成本两个方面对两种方案进行分析
- Redis简介
- 简介
- 典型应用场景
- Redis安装
- 安装
- redis可执行文件说明
- 三种启动方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 数据结构和内部编码
- 单线程
- 数据类型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查询
- Pipline
- 发布订阅
- Bitmap
- Hyperloglog
- GEO
- 持久化机制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉择
- 开发运维常见问题
- fork操作
- 子进程外开销
- AOF追加阻塞
- 单机多实例部署
- Redis复制原理和优化
- 什么是主从复制
- 主从复制配置
- 全量复制和部分复制
- 故障处理
- 开发运维常见问题
- Sentinel
- 主从复制高可用
- 架构说明
- 安装配置
- 客户端连接
- 实现原理
- 常见开发运维问题
- 高可用读写分离
- 故障转移client怎么知道新的master地址
- 总结
- Sluster
- 呼唤集群
- 数据分布
- 搭建集群
- 集群通信
- 集群扩容
- 集群缩容
- 客户端路由
- 故障转移
- 故障发现
- 故障恢复
- 开发运维常见问题
- 缓存设计与优化
- 缓存收益和成本
- 缓存更新策略
- 缓存粒度控制
- 缓存穿透优化
- 缓存雪崩优化
- 无底洞问题优化
- 热点key重建优化
- 总结
- 布隆过滤器
- 引出布隆过滤器
- 布隆过滤器基本原理
- 布隆过滤器误差率
- 本地布隆过滤器
- Redis布隆过滤器
- 分布式布隆过滤器
- 开发规范
- 内存管理
- 开发运维常见坑
- 实战
- 对文章进行投票
- 数据库的概念
- 启动多实例