
## 什么是缓存雪崩
* 下图描述了什么是缓存雪崩:由于缓存层承载着大量请求,有效地保护了存储层,但是**如果缓存层由于某些原因不能提供服务,于是所有的请 求都会达到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况**
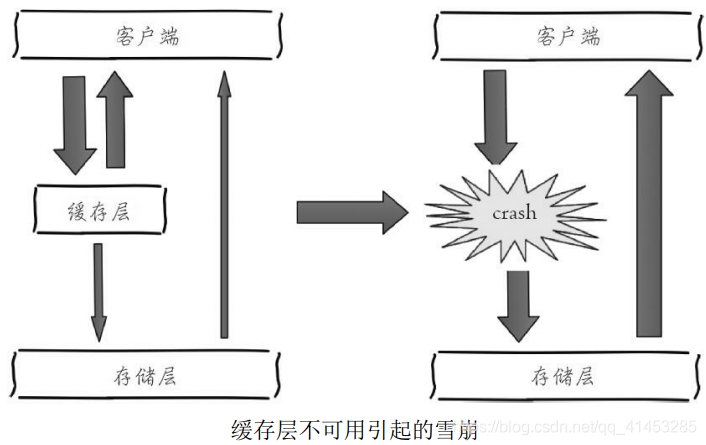
* 缓存雪崩的英文原意是stampeding herd(奔逃的野牛),指的是缓存层宕掉后,流量会像奔逃的野牛一样,打向后端存储
## 优化
**预防和解决缓存雪崩问题,可以从以下三个方面进行着手:**
* 1)保证缓存层服务高可用性。和飞机都有多个引擎一样,如果缓存层 设计成高可用的,即使个别节点、个别机器、甚至是机房宕掉,依然可以提 供服务,例如前面介绍过的Redis Sentinel和Redis Cluster都实现了高可用。
* 2)依赖隔离组件为后端限流并降级
* 无论是缓存层还是存储层都会有出错的概率,可以将它们视同为资源。作为并发量较大的系统,假如有一个资源不可用,可能会造成线程全部阻塞(hang)在这个资源上,造成整个系统不可用。降级机制在高并发系统中是非常普遍的:比如推荐服务中,如果个性化推荐服务不可用,可以降级补充热点数据,不至于造成前端页面是开天窗。在实际项目中,我们需要对重要的资源(例如Redis、MySQL、 HBase、外部接口)都进行隔离,**让每种资源都单独运行在自己的线程池中,**即使个别资源出现了问题,对其他服务没有影响。但是线程池如何管理,比如如何关闭资源池、开启资源池、资源池阀值管理,这些做起来还是相当复杂的
* 这里推荐一个Java依赖隔离工具 Hystrix([https://github.com/netflix/hystrix](https://github.com/netflix/hystrix)),如下图所示。Hystrix是解决依 赖隔离的利器,但是该内容已经超出本书的范围,同时只适用于Java应用, 所以这里不会详细介绍
* 3)提前演练。在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定
- Redis简介
- 简介
- 典型应用场景
- Redis安装
- 安装
- redis可执行文件说明
- 三种启动方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 数据结构和内部编码
- 单线程
- 数据类型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查询
- Pipline
- 发布订阅
- Bitmap
- Hyperloglog
- GEO
- 持久化机制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉择
- 开发运维常见问题
- fork操作
- 子进程外开销
- AOF追加阻塞
- 单机多实例部署
- Redis复制原理和优化
- 什么是主从复制
- 主从复制配置
- 全量复制和部分复制
- 故障处理
- 开发运维常见问题
- Sentinel
- 主从复制高可用
- 架构说明
- 安装配置
- 客户端连接
- 实现原理
- 常见开发运维问题
- 高可用读写分离
- 故障转移client怎么知道新的master地址
- 总结
- Sluster
- 呼唤集群
- 数据分布
- 搭建集群
- 集群通信
- 集群扩容
- 集群缩容
- 客户端路由
- 故障转移
- 故障发现
- 故障恢复
- 开发运维常见问题
- 缓存设计与优化
- 缓存收益和成本
- 缓存更新策略
- 缓存粒度控制
- 缓存穿透优化
- 缓存雪崩优化
- 无底洞问题优化
- 热点key重建优化
- 总结
- 布隆过滤器
- 引出布隆过滤器
- 布隆过滤器基本原理
- 布隆过滤器误差率
- 本地布隆过滤器
- Redis布隆过滤器
- 分布式布隆过滤器
- 开发规范
- 内存管理
- 开发运维常见坑
- 实战
- 对文章进行投票
- 数据库的概念
- 启动多实例