
## 无底洞问题
* 2010年,Facebook的Memcache节点已经达到了3000个,承载着TB级别的缓存数据。但开发和运维人员发现了一个问题,为了满足业务要求**添加了大量新Memcache节点,但是发现性能不但没有好转反而下降了**,当时将这 种现象称为缓存的“无底洞”现象。
* 那么为什么会产生这种现象呢,通常来说添加节点使得Memcache集群性能应该更强了,但事实并非如此。键值数据库由于通常采用哈希函数将 key映射到各个节点上,造成key的分布与业务无关,但是**由于数据量和访问量的持续增长,造成需要添加大量节点做水平扩容,导致键值分布到更多的节点上**,所以无论是Memcache还是Redis的分布式,批量操作通常**需要从不同节点上获取,相比于单机批量操作只涉及一次网络操作,分布式批量操作会涉及多次网络时间**
* 下图展示了在分布式条件下,一次mget操作需要访问多个Redis节点, 需要多次网络时间
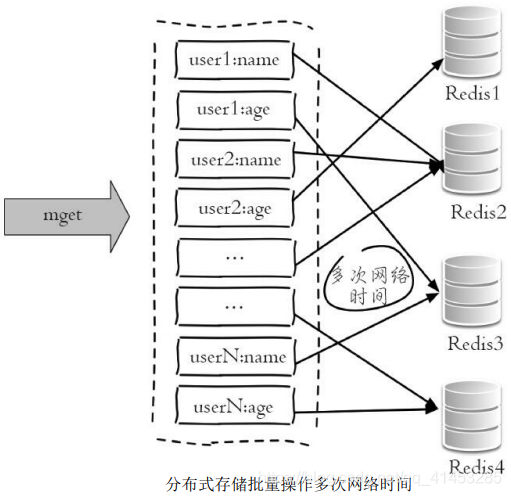
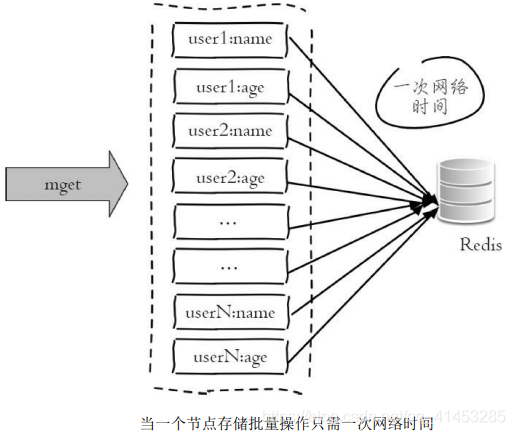
* 而下图由于所有键值都集中在一个节点上,所以一次批量操作只需要 一次网络时间
## 无底洞问题分析
* 客户端一次批量操作会涉及多次网络操作,也就意味着批量操作会随 着节点的增多,耗时会不断增大
* 网络连接数变多,对节点的性能也有一定影响
* 用一句通俗的话总结就是,更多的节点不代表更高的性能,所谓“无底 洞”就是说投入越多不一定产出越多。但是分布式又是不可以避免的,因为 访问量和数据量越来越大,一个节点根本抗不住,所以如何高效地在分布式缓存中批量操作是一个难点;
## 优化IO的几种方法
1. 命令本身优化"例如慢查询keys,hgetall ,bigkey;
2. 减少网络通信次数;
3. 降低接入成本:例如客户端长连接/连接池,NIO等;
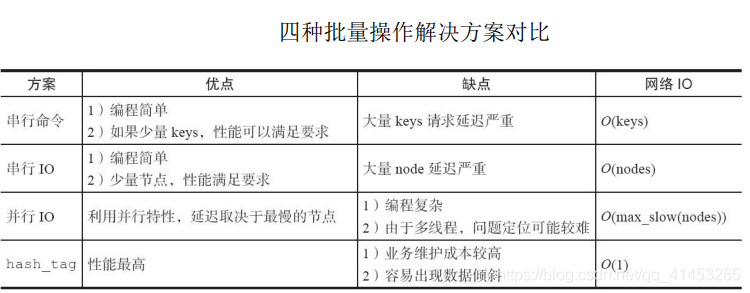
## 四种批量优化方法
https://blog.csdn.net/qq_41453285/article/details/106547980
1. 串行mget;
2. 串行io;
3. 并行io;
4. hash_tag;
- Redis简介
- 简介
- 典型应用场景
- Redis安装
- 安装
- redis可执行文件说明
- 三种启动方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 数据结构和内部编码
- 单线程
- 数据类型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查询
- Pipline
- 发布订阅
- Bitmap
- Hyperloglog
- GEO
- 持久化机制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉择
- 开发运维常见问题
- fork操作
- 子进程外开销
- AOF追加阻塞
- 单机多实例部署
- Redis复制原理和优化
- 什么是主从复制
- 主从复制配置
- 全量复制和部分复制
- 故障处理
- 开发运维常见问题
- Sentinel
- 主从复制高可用
- 架构说明
- 安装配置
- 客户端连接
- 实现原理
- 常见开发运维问题
- 高可用读写分离
- 故障转移client怎么知道新的master地址
- 总结
- Sluster
- 呼唤集群
- 数据分布
- 搭建集群
- 集群通信
- 集群扩容
- 集群缩容
- 客户端路由
- 故障转移
- 故障发现
- 故障恢复
- 开发运维常见问题
- 缓存设计与优化
- 缓存收益和成本
- 缓存更新策略
- 缓存粒度控制
- 缓存穿透优化
- 缓存雪崩优化
- 无底洞问题优化
- 热点key重建优化
- 总结
- 布隆过滤器
- 引出布隆过滤器
- 布隆过滤器基本原理
- 布隆过滤器误差率
- 本地布隆过滤器
- Redis布隆过滤器
- 分布式布隆过滤器
- 开发规范
- 内存管理
- 开发运维常见坑
- 实战
- 对文章进行投票
- 数据库的概念
- 启动多实例