
## 什么是热点key重建
* 开发人员使用“缓存+过期时间”的策略既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。但是**有两个问题如果同时出现,可能就会对应用造成致命的危害:**
* 当前key是一个**热点key**(例如一个热门的娱乐新闻),并发量非常 大
* 重建缓存**不能在短时间完成,可能是一个复杂计算**,例如复杂的SQL、多次IO、多个依赖等
* **在缓存失效的瞬间,有大量线程来重建缓存**(如下图所示),造成 后端负载加大,甚至可能会让应用崩溃

要解决这个问题也不是很复杂,但是不能为了解决这个问题给系统带来更多的麻烦,**所以需要制定如下目标:**
## 三个目标
* **减少重建缓存的次数**
* **数据尽可能一致**
* **较少的潜在危险**
## 互斥锁
* 此方法**只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完**,重新从缓存获取数据即可,整个过程如下图所示

**下面代码使用Redis的setnx命令实现上述功能:**
* 1)从Redis获取数据,如果值不为空,则直接返回值;否则执行下面的2.1)和2.2)步骤
* 2.1)如果set(nx和ex)结果为true,说明此时没有其他线程重建缓存, 那么当前线程执行缓存构建逻辑
* 2.2)如果set(nx和ex)结果为false,说明此时已经有其他线程正在执 行构建缓存的工作,那么当前线程将休息指定时间(例如这里是50毫秒,取 决于构建缓存的速度)后,重新执行函数,直到获取到数据
```
String get(String key) {
// 从Redis中获取数据
String value = redis.get(key);
// 如果value为空,则开始重构缓存
if (value == null) {
// 只允许一个线程重构缓存,使用nx,并设置过期时间ex
String mutexKey = "mutext:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) { //锁
// 从数据源获取数据
value = db.get(key);
// 回写Redis,并设置过期时间
redis.setex(key, timeout, value);
// 删除key_mutex
redis.delete(mutexKey);
}
// 其他线程休息50毫秒后重试
else {
Thread.sleep(50);
get(key);
}
}
return value;
}
```
## 永远不过期
* **“永远不过期”包含两层意思:**
* **从缓存层面来看**,确实没有设置过期时间,所以不会出现热点key过期 后产生的问题,也就是“物理”不过期;
* **从功能层面来看**,为每个value设置一个逻辑过期时间,当发现超过逻 辑过期时间后,会使用单独的线程去构建缓存;
* **整个过程如下图所示:**

* 从实战看,此方法有效杜绝了热点key产生的问题,但**唯一不足的就是重构缓存期间,会出现数据不一致的情况**,这取决于应用方是否容忍这种不 一致
```
String get(final String key) {
V v = redis.get(key);
String value = v.getValue();
// 逻辑过期时间
long logicTimeout = v.getLogicTimeout();
// 如果逻辑过期时间小于当前时间,开始后台构建
if (v.logicTimeout <= System.currentTimeMillis()) {
String mutexKey = "mutex:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 重构缓存
threadPool.execute(new Runnable() {
public void run() {
String dbValue = db.get(key);
redis.set(key, (dbvalue,newLogicTimeout));
redis.delete(mutexKey);
}
});
}
}
return value;
}
```
## 总结
* **作为一个并发量较大的应用,在使用缓存时有三个目标:**
* 第一,加快用户访问速度,提高用户体验
* 第二,降低后端负载,减少潜在的风险,保证系统平稳
* 第三,保证数据“尽可能”及时更新
* **下面将按照这三个维度对上 述两种解决方案进行分析:**
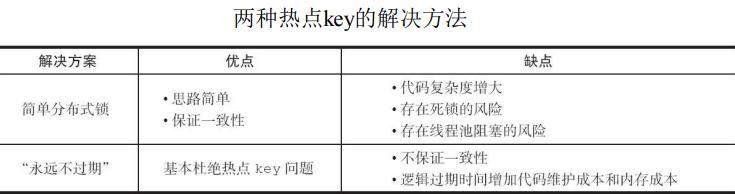
* **互斥锁(mutex key)**:这种方案思路比较简单,但是存在一定的隐患,如果构建缓存过程出现问题或者时间较长,可能会存在死锁和线程池阻塞的风险,但是这种方法能够较好地降低后端存储负载,并在一致性上做得比较好
* **“永远不过期”**:这种方案由于没有设置真正的过期时间,实际上已经 不存在热点key产生的一系列危害,但是会存在数据不一致的情况,同时代码复杂度会增大
* **两种解决方法对比如下图所示:**
- Redis简介
- 简介
- 典型应用场景
- Redis安装
- 安装
- redis可执行文件说明
- 三种启动方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 数据结构和内部编码
- 单线程
- 数据类型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查询
- Pipline
- 发布订阅
- Bitmap
- Hyperloglog
- GEO
- 持久化机制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉择
- 开发运维常见问题
- fork操作
- 子进程外开销
- AOF追加阻塞
- 单机多实例部署
- Redis复制原理和优化
- 什么是主从复制
- 主从复制配置
- 全量复制和部分复制
- 故障处理
- 开发运维常见问题
- Sentinel
- 主从复制高可用
- 架构说明
- 安装配置
- 客户端连接
- 实现原理
- 常见开发运维问题
- 高可用读写分离
- 故障转移client怎么知道新的master地址
- 总结
- Sluster
- 呼唤集群
- 数据分布
- 搭建集群
- 集群通信
- 集群扩容
- 集群缩容
- 客户端路由
- 故障转移
- 故障发现
- 故障恢复
- 开发运维常见问题
- 缓存设计与优化
- 缓存收益和成本
- 缓存更新策略
- 缓存粒度控制
- 缓存穿透优化
- 缓存雪崩优化
- 无底洞问题优化
- 热点key重建优化
- 总结
- 布隆过滤器
- 引出布隆过滤器
- 布隆过滤器基本原理
- 布隆过滤器误差率
- 本地布隆过滤器
- Redis布隆过滤器
- 分布式布隆过滤器
- 开发规范
- 内存管理
- 开发运维常见坑
- 实战
- 对文章进行投票
- 数据库的概念
- 启动多实例