
### 概述
该持久化默认开启,一次性把redis中全部的数据保存一份存储在硬盘中(备份文件名字默认是dump.rdb,该文件自动生成),如果数据非常多(10-20G)就**不适合频繁**进行该持久化操作。该方式默认开启,有自己的触发条件 .
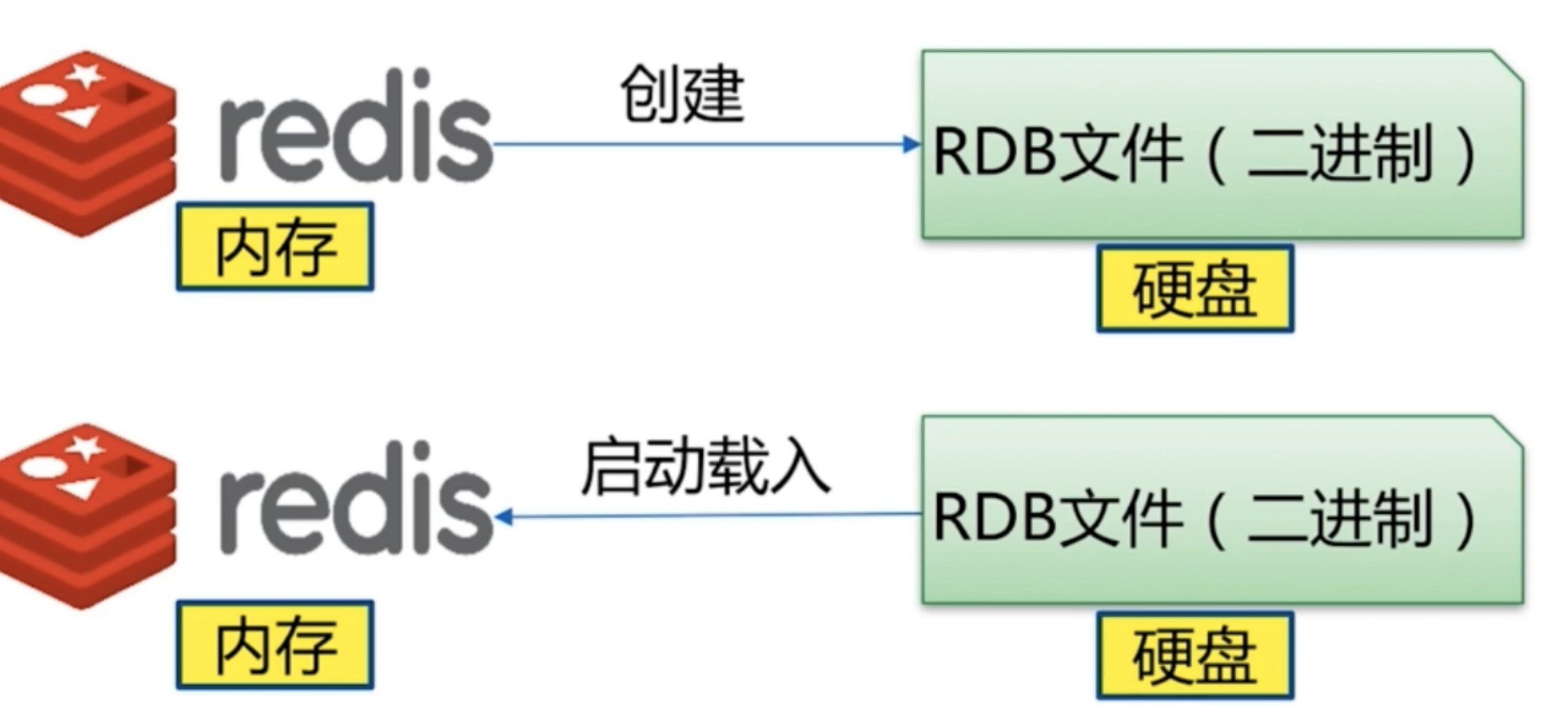
### 自动触发条件
该条件是在内部执行了bgsave命令.
1. save 900 1 : 900秒内如果超过1个key被修改,则发起快照保存 .
2. save 300 10 : 300秒内超过10个key被修改,发起快照.
3. save 60 10000 : 60秒内超过10000个key被修改,发起快照 .
注意:屏蔽该触发条件,即可关闭快照方式。
该配置文件在安装目录的redis.conf

### 设置保存位置
备份文件文字默认是dump.rdb,我们可以自己进行修改 .在redis.conf文件中进行修改
1. dir : 目录
2. dbfilename : 文件名

### 手动发起快照
**两种方式完成手动保存**
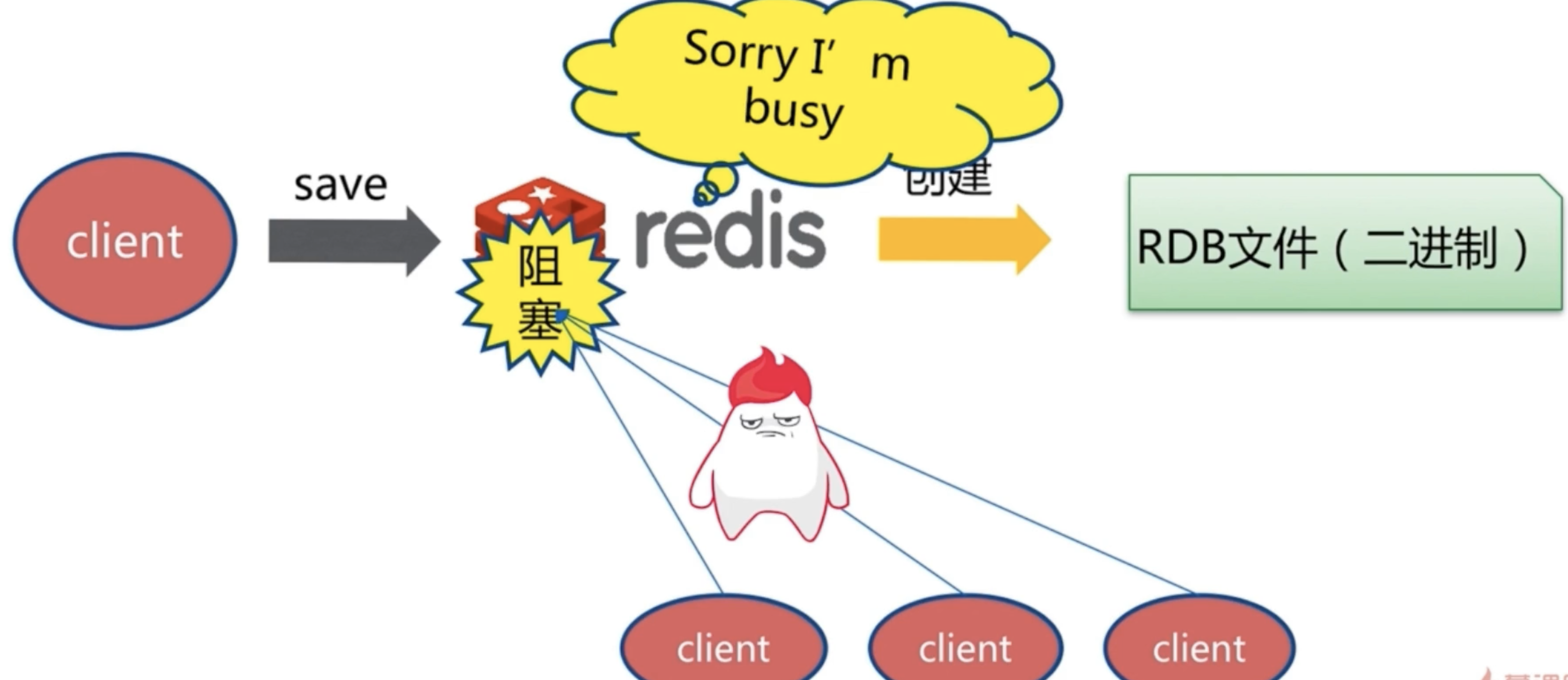
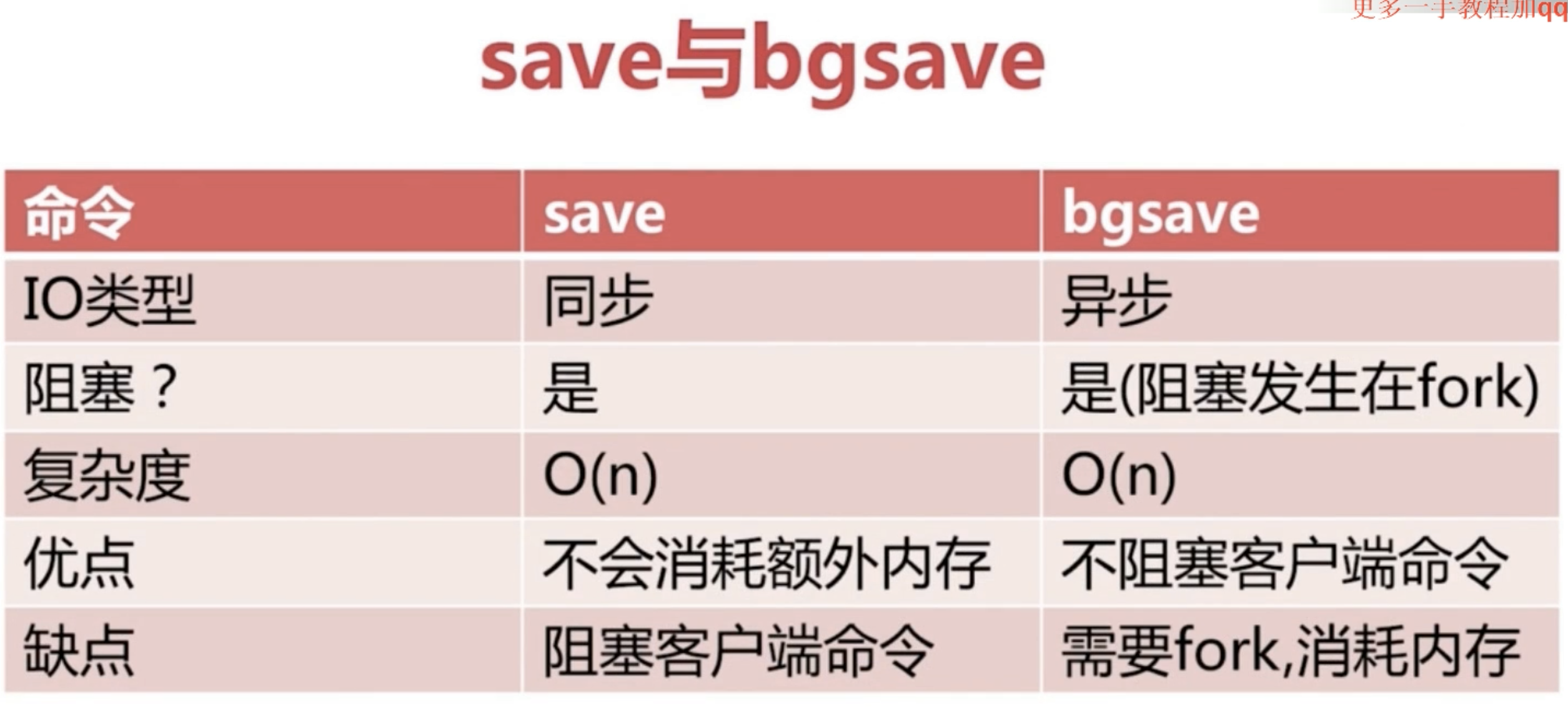
**方式一**:在登录状态,执行save即可 . 但是save是同步的,也就是说会阻塞后面的命令.如果数据量过大,那么后面的命令将会等待很长时间. 执行save命令后,如果存在老的RDB文件,新替换老.富足度是O(N)的
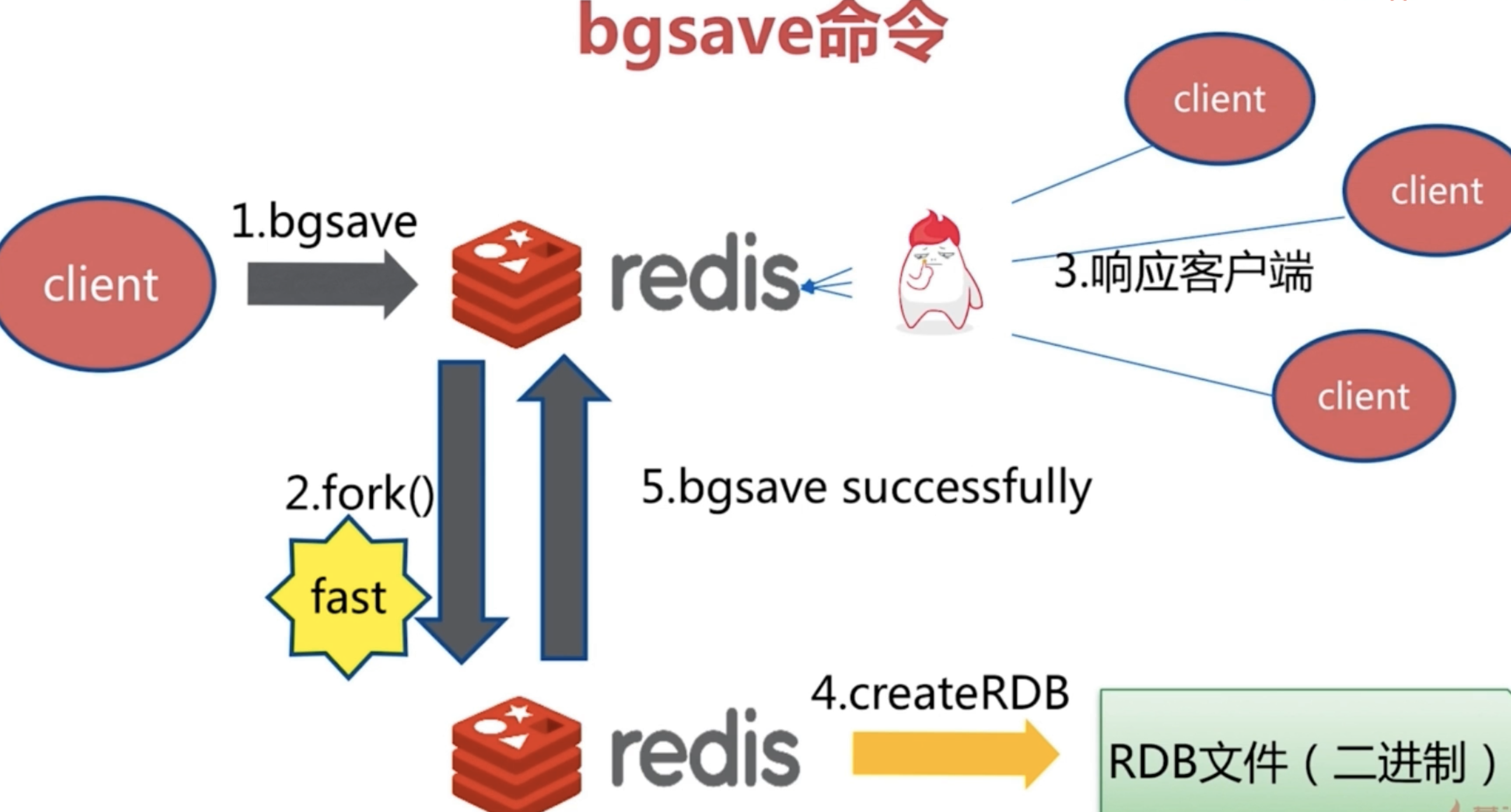
**方式二**:在命令行状态,执行bgsave . 相对于save,bgsave是fork一个子进程来存储文件的.相对来说不会后序阻塞命令和速度更快. 文件策略和复杂度和save是相同的.
### 对比
### 缺点
1. 由于快照方式是在一定间隔做一次的,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改,一般情况下保持默认就行了,时间间隔太短了,会造成服务器的压力。
2. 无法主动控制存储的时间.
### 相对最佳配置
1. 关闭自动保存;
2. 根据端口号保存rdb文件;
3. 当bgsave发生错误,停止;
4. 使用压缩方式;
5. 使用数据校验

### 触发机制--不容忽略方式
1. 全量复制;
2. debug reload;
3. shutdow;
### RDB总结
1. RDB是Redis内存到硬盘的快照,用于持久化;
2. save通常会阻塞Redis;
3. bgsave不会阻塞Redis,但是会fork新进程;
4. save自动配置满足任一条件就会被执行.(但是我们通常不会使用自动配置);
5. 有些触发机制不容忽视;
### RDB存在问题
1. 耗时耗性能;
2. 不可控,容易丢失数据;
- Redis简介
- 简介
- 典型应用场景
- Redis安装
- 安装
- redis可执行文件说明
- 三种启动方法
- Redis常用配置
- API的使用和理解
- 通用命令
- 数据结构和内部编码
- 单线程
- 数据类型
- 字符串
- 哈希
- 列表
- 集合
- 有序集合
- Redis常用功能
- 慢查询
- Pipline
- 发布订阅
- Bitmap
- Hyperloglog
- GEO
- 持久化机制
- 概述
- snapshotting快照方式持久化
- append only file追加方式持久化AOF
- RDB和AOF的抉择
- 开发运维常见问题
- fork操作
- 子进程外开销
- AOF追加阻塞
- 单机多实例部署
- Redis复制原理和优化
- 什么是主从复制
- 主从复制配置
- 全量复制和部分复制
- 故障处理
- 开发运维常见问题
- Sentinel
- 主从复制高可用
- 架构说明
- 安装配置
- 客户端连接
- 实现原理
- 常见开发运维问题
- 高可用读写分离
- 故障转移client怎么知道新的master地址
- 总结
- Sluster
- 呼唤集群
- 数据分布
- 搭建集群
- 集群通信
- 集群扩容
- 集群缩容
- 客户端路由
- 故障转移
- 故障发现
- 故障恢复
- 开发运维常见问题
- 缓存设计与优化
- 缓存收益和成本
- 缓存更新策略
- 缓存粒度控制
- 缓存穿透优化
- 缓存雪崩优化
- 无底洞问题优化
- 热点key重建优化
- 总结
- 布隆过滤器
- 引出布隆过滤器
- 布隆过滤器基本原理
- 布隆过滤器误差率
- 本地布隆过滤器
- Redis布隆过滤器
- 分布式布隆过滤器
- 开发规范
- 内存管理
- 开发运维常见坑
- 实战
- 对文章进行投票
- 数据库的概念
- 启动多实例