
在关系数据库管理系统中,表建立时各数据之间的关系不必确定,常把一个实体的所有信息存放在一个表中。当检索数据时,通过连接操作查询出存放在多个表中的不同实体的信息。连接操作给用户带来很大的灵活性,它们可以在任何时候增加新的数据类型。为不同实体创建新的表,之后通过连接进行查询。
连接可以在`SELECT`语句的`FROM`子句或`WHERE`子句中建立,似是而非在FROM子句中指出连接时有助于将连接操作与WHERE子句中的搜索条件区分开来。所以,在Transact-SQL中推荐使用这种方法。
SQL-92标准所定义的FROM子句的连接语法格式为:
~~~sql
FROM join_table join_type join_table
[ON (join_condition)]
~~~
其中`join_table`指出参与连接操作的表名,连接可以对同一个表操作,也可以对多表操作,对同一个表操作的连接又称做自连接。
`join_type` 指出连接类型,可分为三种:内连接、外连接和交叉连接。
* 内连接(`INNER JOIN`)使用比较运算符进行表间某(些)列数据的比较操作,并列出这些表中与连接条件相匹配的数据行。根据所使用的比较方式不同,内连接又分为等值连 接、自然连接和不等连接三种。
* 外连接分为左外连接(`LEFT OUTER JOIN`或`LEFT JOIN`)、右外连接(`RIGHT OUTER JOIN`或`RIGHT JOIN`)和全外连接(`FULL OUTER JOIN`或`FULL JOIN`)三种。与内连接不同的是,外连接不只列出与连接条件相匹配的行,而是列出左表(左外连接时)、右表(右外连接时)或两个表(全外连接时)中所有 符合搜索条件的数据行。
* 交叉连接(`CROSS JOIN`)没有`WHERE`子句,它返回连接表中所有数据行的笛卡尔积,其结果集合中的数据行数等于第一个表中符合查询条件的数据行数乘以第二个表中符合查询条件的数据行数。
连接操作中的`ON (join_condition)`子句指出连接条件,它由被连接表中的列和比较运算符、逻辑运算符等构成。
>[danger] ## 连接表- 简要概述SQL Server中的连接类型,包括内连接,左连接,右连接和完全外连接。
在关系数据库中,数据分布在多个逻辑表中。 要获得完整有意义的数据集,需要使用连接来查询这些表中的数据。 SQL Server支持多种连接,包括内连接,[左连接],右连接,全外连接]和交叉连接。 每种连接类型指定SQL Server如何使用一个表中的数据来选择另一个表中的行。
为了方便演示,下面将创建一些示例表。
#### A. 创建示例表
首先,创建一个名为`hr`的新模式:
~~~sql
CREATE SCHEMA hr;
GO
~~~
其次,在`hr`模式中创建两个名为`candidate`和`employees`的新表:
~~~sql
CREATE TABLE hr.candidates(
id INT PRIMARY KEY IDENTITY,
fullname VARCHAR(100) NOT NULL
);
CREATE TABLE hr.employees(
id INT PRIMARY KEY IDENTITY,
fullname VARCHAR(100) NOT NULL
);
~~~
第三,在`candidate`和`employees`表中插入一些行:
~~~sql
INSERT INTO
hr.candidates(fullname)
VALUES
('John Doe'),
('Lily Bush'),
('Peter Drucker'),
('Jane Doe');
INSERT INTO
hr.employees(fullname)
VALUES
('John Doe'),
('Jane Doe'),
('Michael Scott'),
('Jack Sparrow');
~~~
下面将`candidate`表用作左表,将`employees`表用作右表。
#### B. SQL Server内联接
内联接生成一个数据集,其中包含左表中的行,这些行具有右表中的匹配行。
以下示例使用`inner join`子句从`employees`表中获取在`candidates`表的`fullname`列中具有相同的值的行记录:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
INNER JOIN hr.employees e
ON e.fullname = c.fullname;
~~~
执行上面查询语句,得到以下结果:

下图说明了两个结果集的内联接的结果:

#### C. SQL Server左连接
左连接选择从左表开始的数据和右表中的匹配行。 左连接返回左表中的所有行和右表中的匹配行。 如果左表中的行在右表中没有匹配的行,则右表的列将具有空值。
左连接也称为左外连接。 `outer`关键字是可选的。
以下语句使用`left join`将`employees`表与`employees`表连接起来:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
LEFT JOIN hr.employees e
ON e.fullname = c.fullname;
~~~
执行上面查询语句,得到以下结果:
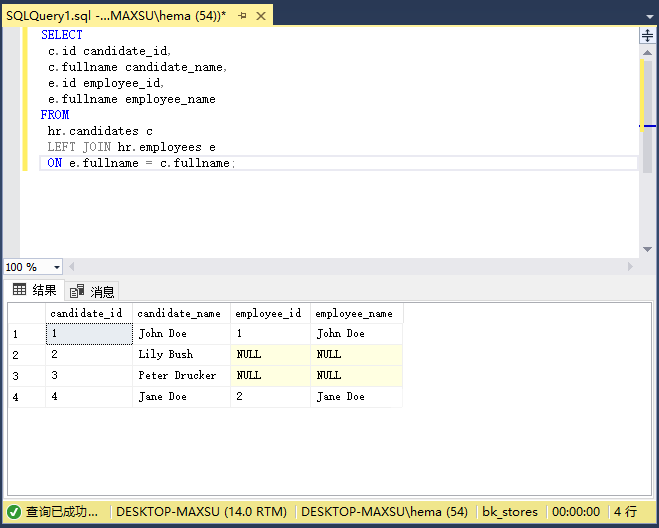
以下图说明了两个结果集的左连接结果:

要获取仅在左表中可用但不在右表中可用的行,可以在上面的查询中添加`WHERE`子句:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
LEFT JOIN hr.employees e
ON e.fullname = c.fullname
WHERE
e.id IS NULL;
~~~
执行上面查询语句,得到以下结果:
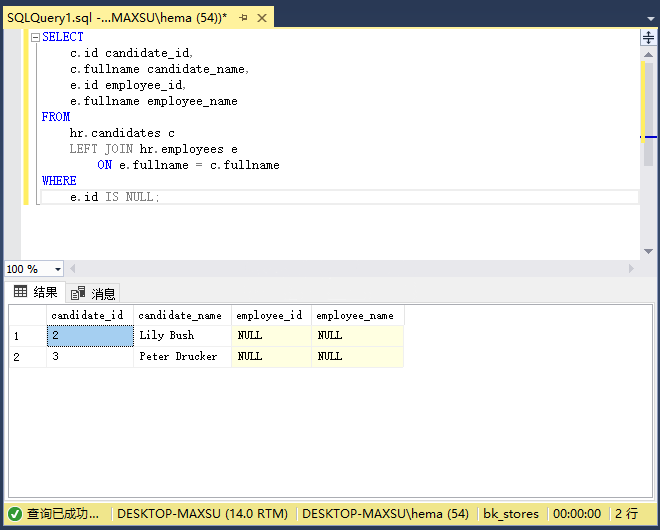
以下图说明左连接的结果,它选择仅在左表中可用的行:

#### D. SQL Server右连接
右连接或右外连接从右表开始选择数据。 它是左连接的反转版本。
右连接返回一个结果集,该结果集包含右表中的所有行和左表中的匹配行。 如果右表中的一行在左表中没有匹配的行,则左表中的所有列都将包含`NULL`值。
以下示例使用右连接查询`candidates` 和 `employees`表中的行:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
RIGHT JOIN hr.employees e
ON e.fullname = c.fullname;
~~~
执行上面查询语句,得到以下结果:
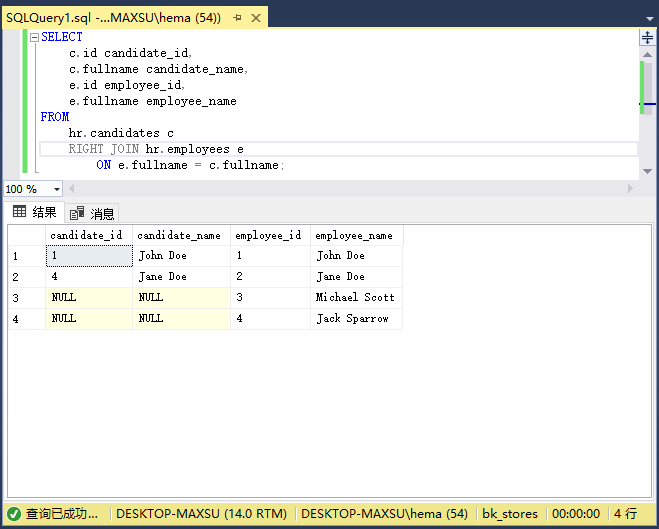
请注意,右表(`employees`)中的所有行都包含在结果集中。
下图表说明了两个结果集的右连接:

类似地,可以通过向上面的查询添加`WHERE`子句来获取仅在右表中可用的行,如下所示:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
RIGHT JOIN hr.employees e
ON e.fullname = c.fullname
WHERE
c.id IS NULL;
~~~
执行上面查询语句,得到以下结果:
下图说明了查询操作的结果:

#### E. SQL Server全连接
完整外连接或完全连接返回一个结果集,该结果集包含左右表中的所有行,两侧的匹配行可用。 如果没有匹配,则缺少的一方将具有`NULL`值。
以下示例显示如何在`candidates` 和 `employees`表之间执行完全联接:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
FULL JOIN hr.employees e
ON e.fullname = c.fullname;
~~~
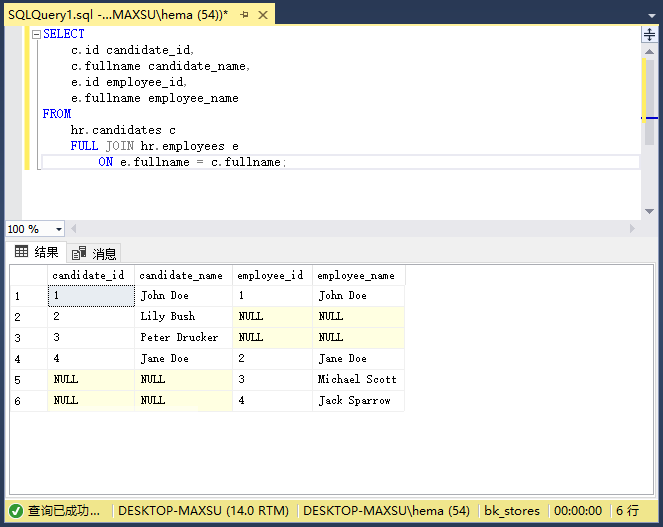
执行上面查询语句,得到以下结果:
下图说明了全连接:

要选择存在左表或右表的行,可以通过添加`WHERE`子句来排除两个表共有的行,如以下查询中所示:
~~~sql
SELECT
c.id candidate_id,
c.fullname candidate_name,
e.id employee_id,
e.fullname employee_name
FROM
hr.candidates c
FULL JOIN hr.employees e
ON e.fullname = c.fullname
WHERE
c.id IS NULL OR
e.id IS NULL;
~~~
执行上面查询语句,得到以下结果:
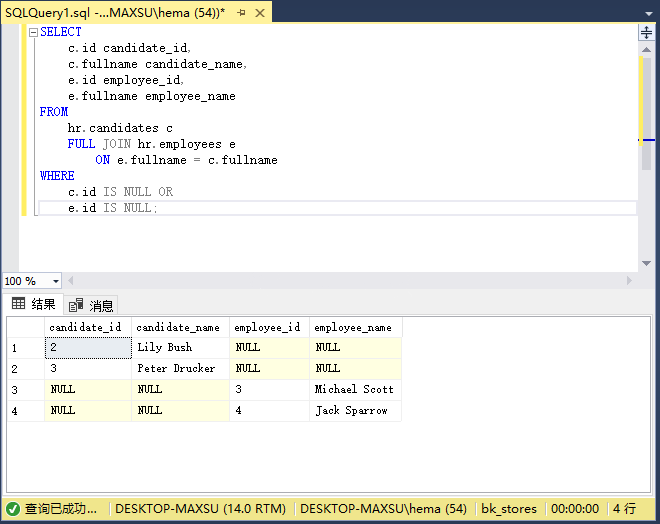
下图说明了上述操作的结果:

>[danger] ## INNER JOIN- 从表中选择在另一个表中具有匹配行的行。
## SQL Server INNER JOIN简介
内连接是SQL Server中最常用的连接之一。 内部联接子句用于查询来自两个或多个相关表的数据。
请参阅以下`products`和`categories`表:

以下语句从`products`表中检索产品信息:
~~~sql
SELECT
product_name,
list_price,
category_id
FROM
production.products
ORDER BY
product_name DESC;
~~~
执行上面查询语句,得到以下结果:
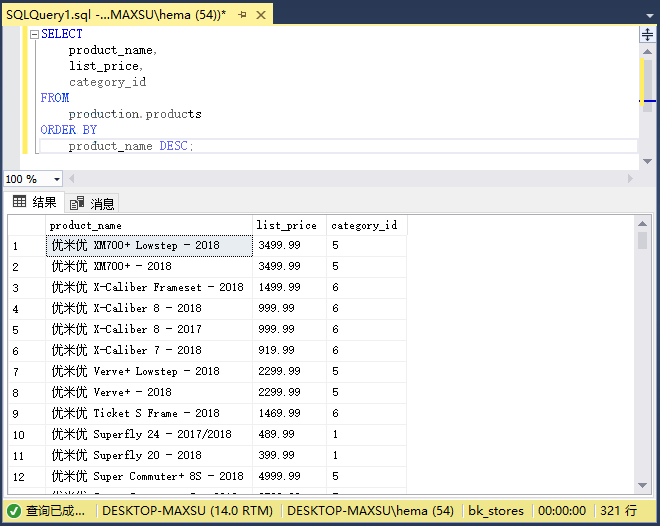
查询仅返回类分类编号列表,不返回分类名称。 要在结果集中包含分类名称,请使用`INNER JOIN`子句,如下所示:
~~~sql
SELECT
product_name,
category_name,
list_price
FROM
production.products p
INNER JOIN production.categories c ON c.category_id = p.category_id
ORDER BY
product_name DESC;
~~~
执行上面查询语句,得到以下结果:
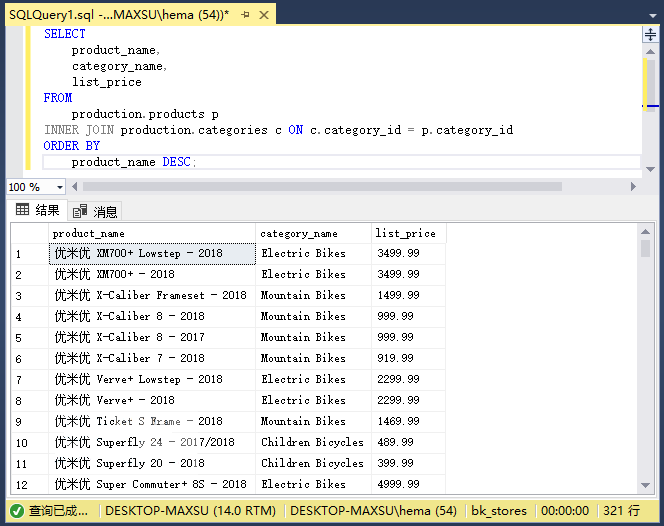
在此查询中,内部连接子句匹配`products`和`categories`表中的行。 如果`products`表中的行在`category_id`列中具有与`categories`表中的行(`ID`列)相同的值,则查询将选择列表中指定的列的值组合为新行,并在结果集中包含该新行。
## SQL Server INNER JOIN语法
以下显示了SQL Server `INNER JOIN`子句的语法:
~~~sql
SELECT
select_list
FROM
T1
INNER JOIN T2 ON join_predicate;
~~~
在此语法中,从`T1`和`T2`表中查询检索数据:
* 首先,在`FROM`子句中指定主表(`T1`)
* 其次,在`INNER JOIN`子句和连接谓词中指定第二个表(`T2`)。 只有连接谓词计算为`TRUE`的行才包含在结果集中。
`INNER JOIN`子句将表`T1`的每一行与表`T2`的行进行比较,以查找满足连接谓词的所有行对。 如果连接谓词的计算结果为`TRUE`,则匹配的`T1`和`T2`行的列值将合并为一个新行并包含在结果集中。
下表说明了两个表`T1(1,2,3)`和`T2(A,B,C)`的内部连接。 结果包括行:`(2,A)`和`(3,B)`,因为它们具有相同的模式。

## SQL Server内联接示例
请参阅以下几个表:`products`, `categories`和`brands`表:

以下语句使用两个`INNER JOIN`子句来查询三个表中的数据:
~~~sql
SELECT
product_name,
category_name,
brand_name,
list_price
FROM
production.products p
INNER JOIN production.categories c ON c.category_id = p.category_id
INNER JOIN production.brands b ON b.brand_id = p.brand_id
ORDER BY
product_name DESC;
~~~
执行上面查询语句,得到以下结果:
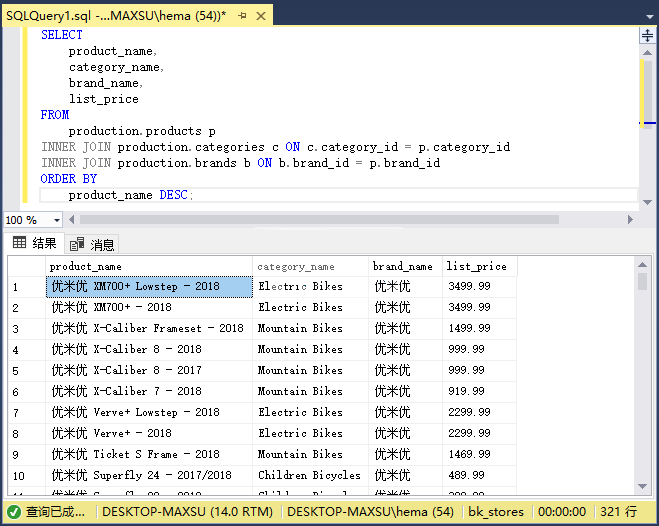
>[danger] ## LEFT JOIN- 返回左表中的所有行以及右表中的匹配行。 如果右表没有匹配的行,请对右表中的列值使用`NULL`值。
## SQL Server LEFT JOIN子句简介
`LEFT JOIN`子句用于查询来自多个表的数据。它返回左表中的所有行和右表中的匹配行。 如果在右表中找不到匹配的行,则使用`NULL`代替显示。
以下说明如何使用`LEFT JOIN`子句来连接两个表`T1`和`T2`:
~~~sql
SELECT
select_list
FROM
T1
LEFT JOIN T2 ON
join_predicate;
~~~
在上面语法中,`T1`和`T2`分别是左表和右表。
对于`T1`表中的每一行,查询将其与`T2`表中的所有行进行比较。 如果一对行导致连接谓词计算为`TRUE`,则将组合这些行中的列值以形成新行,然后将其包含在结果集中。
如果左表(`T1`)中的行没有与来自`T2`表的任何匹配行,则查询将左表中的行的列值与来自右表的每个列值的`NULL`组合。
简而言之,`LEFT JOIN`子句返回左表(`T1`)中的所有行以及右表(`T2`)中匹配的行或`NULL`值。
以下说明了两个表`T1(1,2,3)`和`T2(A,B,C)`的`LEFT JOIN`过程:

在上面图示中,`T2`表中的行不与`T1`表中的行`1`匹配,因此使用`NULL`。 `T1`表中的第`2`行和第`3`行分别与`T2`表中的行`A`和行`B`匹配。
## SQL Server LEFT JOIN示例
请参阅以下`products` 和 `order_items`表的结构:

每个销售订单项目包括一个产品。 `order_items`和`products`表之间的链接是通过`product_id`列中的值。
以下语句使用`LEFT JOIN`子句查询`products`和`order_items`表中的数据:
~~~sql
SELECT
product_name,
order_id
FROM
production.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
ORDER BY
order_id;
~~~
执行上面查询语句,得到以下结果:
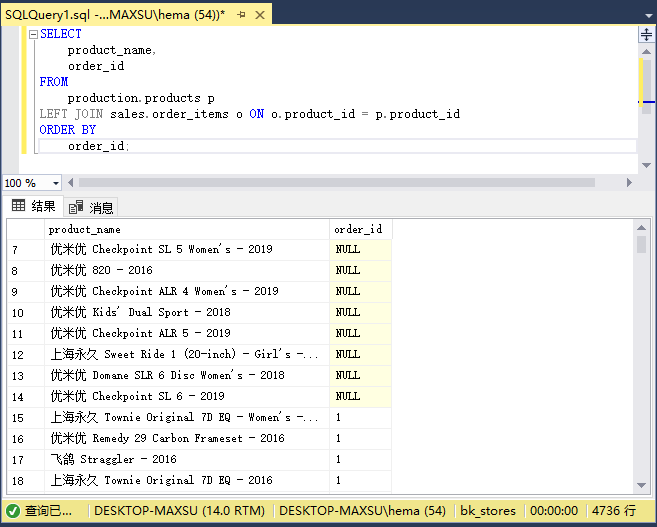
从结果集中可以清楚地看到,`order_id`列中的`NULL`列表表明相应的产品尚未销售给任何客户。
可以使用`WHERE`子句来过滤结果集。 以下查询返回未出现在任何销售订单中的产品:
~~~sql
SELECT
product_name,
order_id
FROM
production.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
WHERE order_id IS NULL
ORDER BY
order_id;
~~~
执行上面查询语句,得到以下结果:
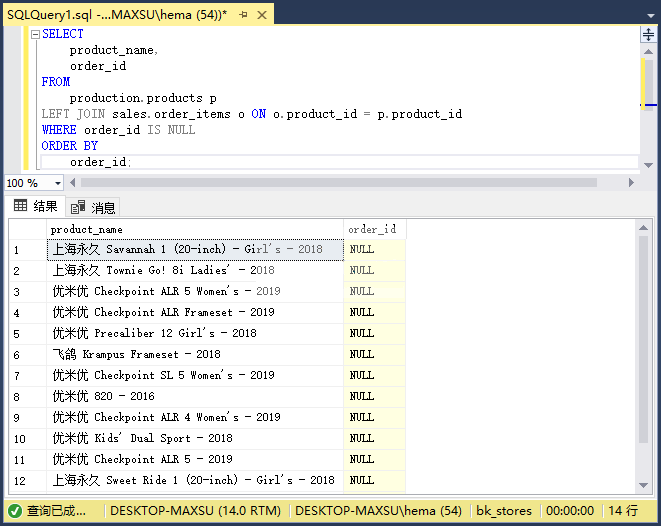
与往常一样,SQL Server在`LEFT JOIN`子句之后处理`WHERE`子句。
#### SQL Server LEFT JOIN的条件:ON与WHERE子句
以下查询查找属于订单ID为`100`的产品:
~~~sql
SELECT
product_name,
order_id
FROM
production.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id
WHERE order_id = 100
ORDER BY
order_id;
~~~
执行上面查询语句,得到以下结果:

如果将条件`order_id = 100`移动到`ON`子句:
~~~sql
SELECT
p.product_id,
product_name,
order_id
FROM
production.products p
LEFT JOIN sales.order_items o ON o.product_id = p.product_id AND p.product_id = 100
ORDER BY
order_id DESC;
~~~
执行上面查询语句,得到以下结果:
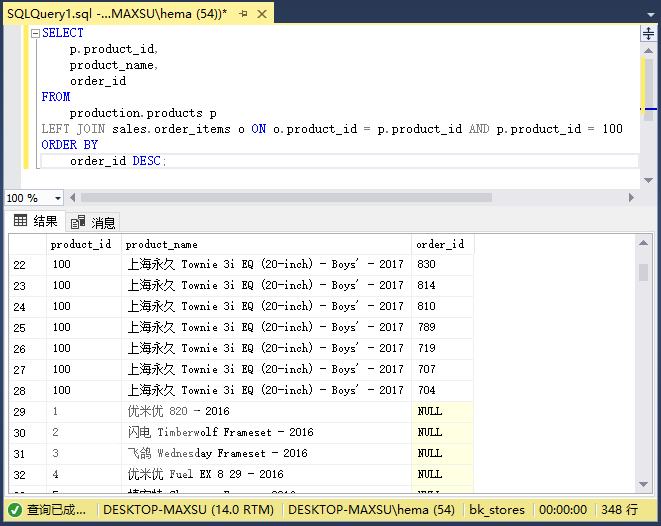
查询返回了所有产品,但只有ID为`100`的产品具有关联的订单数据。
请注意,对于`INNER JOIN`子句,如果将`ON`子句中的条件放在`WHERE`子句中,则它在功能上是等效的。
>[danger] ## RIGHT JOIN- 学习左连接的反转版本 - 右连接。
## SQL Server RIGHT JOIN子句简介
`RIGHT JOIN`子句组合来自两个或多个表的数据。 `RIGHT JOIN`开始从右表中选择数据并与左表中的行匹配。 `RIGHT JOIN`返回一个结果集,该结果集包含右表中的所有行,无论是否具有左表中的匹配行。 如果右表中的行没有来自右表的任何匹配行,则结果集中右表的列将使用`NULL`值。
以下是`RIGHT JOIN`的语法:
~~~sql
SELECT
select_list
FROM
T1
RIGHT JOIN T2 ON join_predicate;
~~~
在此语法中,`T1`是左表,`T2`是右表。
请注意,`RIGHT JOIN`和`RIGHT OUTER JOIN`是相同的。 `OUTER`关键字是可选的。
下图说明了`RIGHT JOIN`操作:

橙色部分表示返回的结果集。
## SQL Server RIGHT JOIN示例
我们将使用[示例数据库](https://www.yiibai.com/sqlserver/sql-server-sample-database.html "示例数据库")中的`sales.order_items`和`production.products`表进行演示。

以下语句返回`production.products`表中的产品名称和`sales.order_items`所有`order_id`:
~~~sql
SELECT
product_name,
order_id
FROM
sales.order_items o
RIGHT JOIN production.products p
ON o.product_id = p.product_id
ORDER BY
order_id;
~~~
执行上面查询语句,得到以下结果:
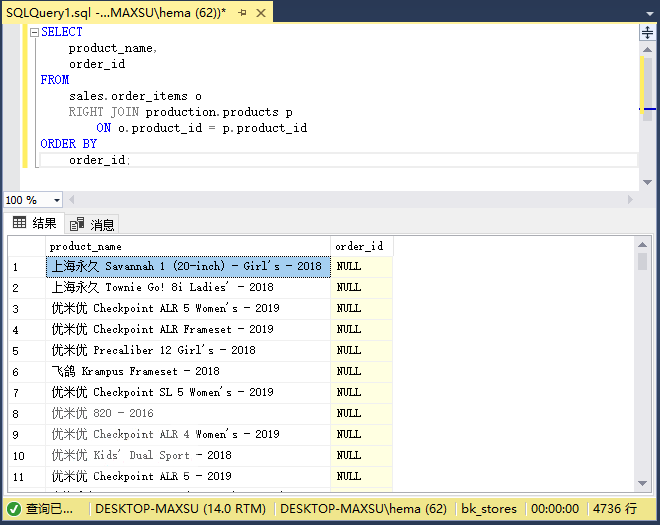
该查询返回了`production.products`表(右表)中的所有行和`sales.order_items`表(左表)中的行。 如果产品没有任何销售,则order\_id列将为null。
要获取没有任何销售记录的产品,请在上述查询中添加`WHERE`子句以过滤掉具有销售额的产品:
~~~sql
SELECT
product_name,
order_id
FROM
sales.order_items o
RIGHT JOIN production.products p
ON o.product_id = p.product_id
WHERE
order_id IS NULL
ORDER BY
product_name;
~~~
执行上面查询语句,得到以下结果:
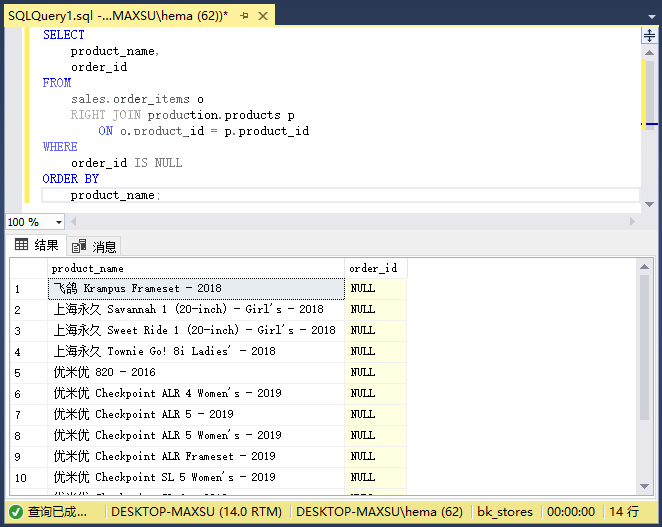
下面的图说明了上面的`RIGHT JOIN`操作:

>[danger] ## FULL OUTER JOIN - 如果不存在匹配的行,则返回左右表中的匹配行以及每侧的行。
## SQL Server全外连接简介
`FULL OUTER JOIN`返回一个包括左右表中行记录的结果集。 如果左表中的行不存在匹配的行,则右表的列将具有`NULL`值。 相反,如果右表中的行不存在匹配的行,则左表的列将具有`NULL`值。
下面显示了连接两个表时`FULL OUTER JOIN`的语法:
~~~sql
SELECT
select_list
FROM
T1
FULL OUTER JOIN T2 ON join_predicate;
~~~
`OUTER`关键字是可选的,因此可以不用写上它,如以下查询中所示:
~~~sql
SELECT
select_list
FROM
T1
FULL JOIN T2 ON join_predicate;
~~~
在这个语法中:
* 在`FROM`子句中指定左表`T1`。
* 指定右表`T2`和连接谓词。
下图说明了`FULL OUTER JOIN`的两个结果集:

## SQL Server完全外连接示例
下面创建一些示例表来演示全外连接。
首先,创建一个名为`pm`的新模式,它代表项目管理。
~~~sql
CREATE SCHEMA pm;
GO
~~~
接下来,在`pm`模式中创建名为`projects`和`members`的新表:
~~~sql
CREATE TABLE pm.projects(
id INT PRIMARY KEY IDENTITY,
title VARCHAR(255) NOT NULL
);
CREATE TABLE pm.members(
id INT PRIMARY KEY IDENTITY,
name VARCHAR(120) NOT NULL,
project_id INT,
FOREIGN KEY (project_id)
REFERENCES pm.projects(id)
);
~~~
假设每个成员只能参与一个项目,每个项目都有零个或多个成员。 如果项目处于构思阶段,则不会分配任何成员。
然后,向`projects`和`member`表中插入一些行记录:
~~~sql
INSERT INTO
pm.projects(title)
VALUES
('New CRM for Project Sales'),
('ERP Implementation'),
('Develop Mobile Sales Platform');
INSERT INTO
pm.members(name, project_id)
VALUES
('John Doe', 1),
('Lily Bush', 1),
('Jane Doe', 2),
('Jack Daniel', null);
~~~
之后,查询`projects`和`member`表中的数据:
~~~sql
SELECT * FROM pm.projects;
SELECT * FROM pm.members;
~~~
最后,使用`FULL OUTER JOIN`查询`projects`和`member`表中的数据:
~~~sql
SELECT
m.name member,
p.title project
FROM
pm.members m
FULL OUTER JOIN pm.projects p
ON p.id = m.project_id;
~~~
执行上面查询语句,得到以下结果:

在此示例中,查询返回参与项目的成员,不参与任何项目的成员以及没有任何成员的项目。
要查找不参与任何项目的成员和没有任何成员的项目,请在上述查询中添加`WHERE`子句:
~~~sql
SELECT
m.name member,
p.title project
FROM
pm.members m
FULL OUTER JOIN pm.projects p
ON p.id = m.project_id
WHERE
m.id IS NULL OR
P.id IS NULL;
~~~
执行上面查询语句,得到以下结果:

如输出中清楚显示,`Jack Daniel`不参与任何项目,而`Develop Mobile Sales Platform`这个项目没有任何成员。
>[danger] ## CROSS JOIN - 连接多个不相关的表,并在连接表中创建行的笛卡尔积。
以下是两个表的SQL Server `CROSS JOIN`的语法:
~~~sql
SELECT
select_list
FROM
T1
CROSS JOIN T2;
~~~
`CROSS JOIN`将第一个表(T1)中的每一行与第二个表(T2)中的每一行连接起来。 换句话说,交叉连接返回两个表中行的**笛卡尔积**。
与INNER JOIN或LEFT JOIN不同,交叉连接不会在连接的表之间建立关系。
假设`T1`表包含三行:`1`,`2`和`3`,`T2`表包含三行:`A`,`B`和`C`。
`CROSS JOIN`从第一个表(T1)获取一行,然后为第二个表(T2)中的每一行创建一个新行。 然后它对第一个表(T1)中的下一行执行相同操作,依此类推。

在此图中,`CROSS JOIN`总共创建了`9`行。 通常,如果第一个表有`n`行,第二个表有`m`行,则交叉连接将产生`n x m`行。
## SQL Server CROSS JOIN示例
以下语句返回所有产品和商店的组合。 结果集可用于月末和年终结算期间的盘点程序:
~~~sql
SELECT
product_id,
product_name,
store_id,
0 AS quantity
FROM
production.products
CROSS JOIN sales.stores
ORDER BY
product_name,
store_id;
~~~
执行上面查询语句,得到以下结果:
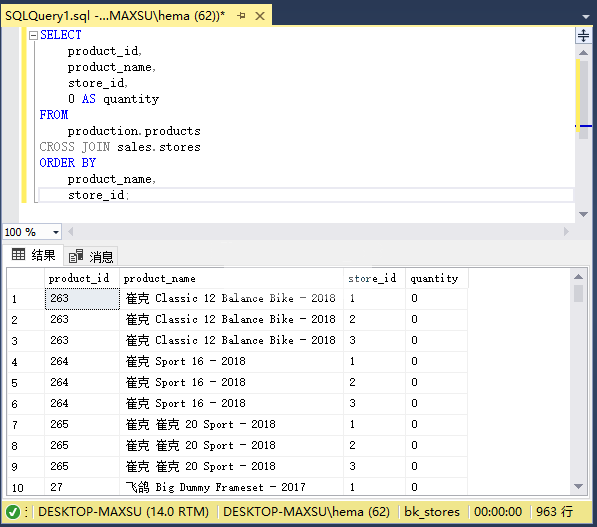
以下语句查找商店中没有销售的产品:
~~~sql
SELECT
s.store_id,
p.product_id,
ISNULL(sales, 0) sales
FROM
sales.stores s
CROSS JOIN production.products p
LEFT JOIN (
SELECT
s.store_id,
p.product_id,
SUM (quantity * i.list_price) sales
FROM
sales.orders o
INNER JOIN sales.order_items i ON i.order_id = o.order_id
INNER JOIN sales.stores s ON s.store_id = o.store_id
INNER JOIN production.products p ON p.product_id = i.product_id
GROUP BY
s.store_id,
p.product_id
) c ON c.store_id = s.store_id
AND c.product_id = p.product_id
WHERE
sales IS NULL
ORDER BY
product_id,
store_id;
~~~
执行上面查询语句,得到以下结果:
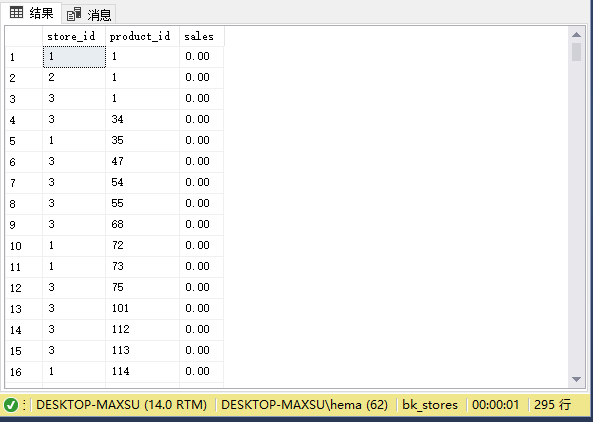
>[danger] ## 自联接- 显示如何使用自联接查询分层数据并比较同一表中的行。
## SQL Server自连接语法
自联接用于将表连接到自身(同一个表)。 它对于查询分层数据或比较同一个表中的行很有用。
自联接使用内连接或左连接子句。 由于使用自联接的查询引用同一个表,因此表别名用于为查询中的表分配不同的名称。
> 请注意,如果在不使用表别名的情况下在查询中多次引用同一个表,则会出现错误。
以下是将表`T`连接到自身的语法:
~~~sql
SELECT
select_list
FROM
T t1
[INNER | LEFT] JOIN T t2 ON
join_predicate;
~~~
上面查询语句中两次引用表`T`。表别名`t1`和`t2`用于为`T`表分配不同的名称。
## SQL Server自连接示例
让我们举几个例子来理解自连接的工作原理。
#### A. 使用自联接查询分层数据
请参考示例数据库中的`staffs`表:

表中存储的行记录如下:

`staffs`表存储员工信息,如身份证,名字,姓氏和电子邮件。 它还有一个名为`manager_id`的列,用于指定直接管理者。 例如,员工`Mireya`向管理员者`Fabiola`汇报工作,因为`Mireya`的`manager_id`列中的值是`Fabiola`。
`Fabiola`没有经理,因为它的`manager_id`列是一个`NULL`值。
要获取工作汇报关系,请使用自联接,如以下查询中所示:
~~~sql
SELECT
e.first_name + ' ' + e.last_name employee,
m.first_name + ' ' + m.last_name manager
FROM
sales.staffs e
INNER JOIN sales.staffs m ON m.staff_id = e.manager_id
ORDER BY
manager;
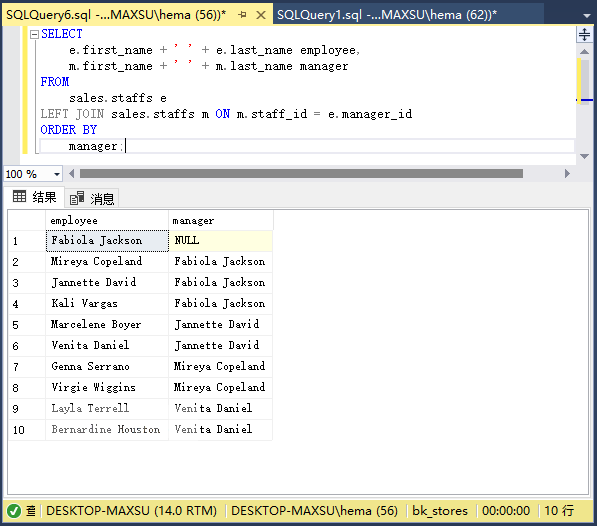
~~~
执行上面查询语句,得到以下结果:
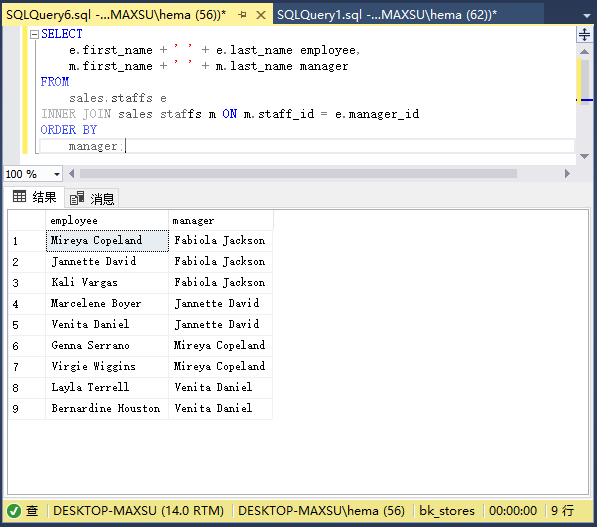
在这个例子中,两次引用了`staffs`表:一个是员工的`e`,另一个是管理者的`m`。 连接谓词使用`e.manager_id`和`m.staff_id`列中的值匹配`employee`和`manager`关系。
由于`INNER JOIN`效应,`employee`列没有`Fabiola Jackson`。 如果用`LEFT JOIN`子句替换`INNER JOIN`子句,如以下查询所示,将获得在`employee`列中包含`Fabiola Jackson`的结果集:
~~~sql
SELECT
e.first_name + ' ' + e.last_name employee,
m.first_name + ' ' + m.last_name manager
FROM
sales.staffs e
LEFT JOIN sales.staffs m ON m.staff_id = e.manager_id
ORDER BY
manager;
~~~
执行上面查询语句,得到以下结果:
#### B. 使用自联接来比较表中的行
请参阅以下`customers`表:

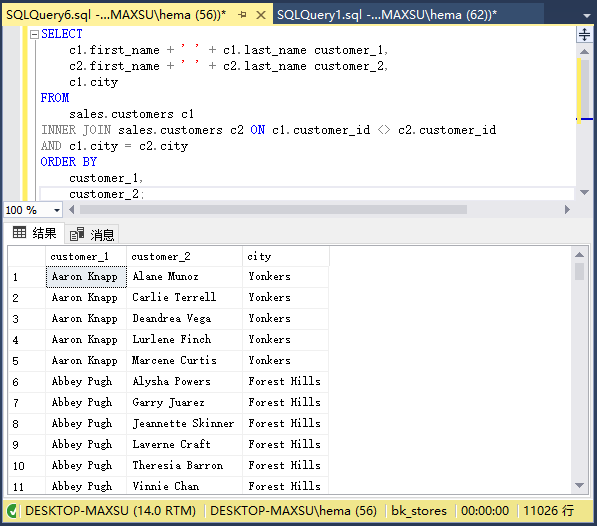
以下语句使用自联接查找位于同一城市的客户。
~~~sql
SELECT
c1.first_name + ' ' + c1.last_name customer_1,
c2.first_name + ' ' + c2.last_name customer_2,
c1.city
FROM
sales.customers c1
INNER JOIN sales.customers c2 ON c1.customer_id <> c2.customer_id
AND c1.city = c2.city
ORDER BY
customer_1,
customer_2;
~~~
执行上面查询语句,得到以下结果:
- 第一章-测试理论
- 1.1软件测试的概念
- 1.2测试的分类
- 1.3软件测试的流程
- 1.4黑盒测试的方法
- 1.5AxureRP的使用
- 1.6xmind,截图工具的使用
- 1.7测试计划
- 1.8测试用例
- 1.9测试报告
- 2.0 正交表附录
- 第二章-缺陷管理工具
- 2.1缺陷的内容
- 2.2书写规范
- 2.3缺陷的优先级
- 2.4缺陷的生命周期
- 2.5缺陷管理工具简介
- 2.6缺陷管理工具部署及使用
- 2.7软件测试基础面试
- 第三章-数据库
- 3.1 SQL Server简介及安装
- 3.2 SQL Server示例数据库
- 3.3 SQL Server 加载示例
- 3.3 SQL Server 中的数据类型
- 3.4 SQL Server 数据定义语言DDL
- 3.5 SQL Server 修改数据
- 3.6 SQL Server 查询数据
- 3.7 SQL Server 连表
- 3.8 SQL Server 数据分组
- 3.9 SQL Server 子查询
- 3.10.1 SQL Server 集合操作符
- 3.10.2 SQL Server聚合函数
- 3.10.3 SQL Server 日期函数
- 3.10.4 SQL Server 字符串函数
- 第四章-linux
- 第五章-接口测试
- 5.1 postman 接口测试简介
- 5.2 postman 安装
- 5.3 postman 创建请求及发送请求
- 5.4 postman 菜单及设置
- 5.5 postman New菜单功能介绍
- 5.6 postman 常用的断言
- 5.7 请求前脚本
- 5.8 fiddler网络基础及fiddler简介
- 5.9 fiddler原理及使用
- 5.10 fiddler 实例
- 5.11 Ant 介绍
- 5.12 Ant 环境搭建
- 5.13 Jmeter 简介
- 5.14 Jmeter 环境搭建
- 5.15 jmeter 初识
- 5.16 jmeter SOAP/XML-RPC Request
- 5.17 jmeter HTTP请求
- 5.18 jmeter JDBC Request
- 5.19 jmeter元件的作用域与执行顺序
- 5.20 jmeter 定时器
- 5.21 jmeter 断言
- 5.22 jmeter 逻辑控制器
- 5.23 jmeter 常用函数
- 5.24 soapUI概述
- 5.25 SoapUI 断言
- 5.26 soapUI数据源及参数化
- 5.27 SoapUI模拟REST MockService
- 5.28 Jenkins的部署与配置
- 5.29 Jmeter+Ant+Jenkins 搭建
- 5.30 jmeter脚本录制
- 5.31 badboy常见的问题
- 第六章-性能测试
- 6.1 性能测试理论
- 6.2 性能测试及LoadRunner简介
- 第七章-UI自动化
- 第八章-Maven
- 第九章-测试框架
- 第十章-移动测试
- 10.1 移动测试点及测试流程
- 10.2 移动测试分类及特点
- 10.3 ADB命令及Monkey使用
- 10.4 MonkeyRunner使用
- 10.5 appium工作原理及使用
- 10.6 Appium环境搭建(Java版)
- 10.7 Appium常用函数(Java版)
- 10.8 Appium常用函数(Python版)
- 10.9 兼容性测试