
SQL Server中分组查询通常用于配合聚合函数,实现分类汇总统计的信息。而其分类汇总的本质实际上就是先将信息排序,排序后相同类别的信息会聚在一起,然后通过需求进行统计计算。
SQL Server中分组查询通常用于配合聚合函数,实现分类汇总统计的信息。而其分类汇总的本质实际上就是先将信息排序,排序后相同类别的信息会聚在一起,然后通过需求进行统计计算。
SQL Server中常用的数据分组相关查询如下:
>[danger] ## GROUP BY- 根据指定列表达式列表中的值对查询结果进行分组。
## SQL Server GROUP BY子句简介
`GROUP BY`子句用于按分组排列查询的行。 这些分组由在`GROUP BY`子句中指定的列确定。
以下是`GROUP BY`子句的语法:
~~~sql
SELECT
select_list
FROM
table_name
GROUP BY
column_name1,
column_name2 ,...;
~~~
在此查询语法中,`GROUP BY`子句为列中的每个值组合生成一个组。
请考虑以下示例:
~~~sql
SELECT
customer_id,
YEAR (order_date) order_year
FROM
sales.orders
WHERE
customer_id IN (1, 2)
ORDER BY
customer_id;
~~~
执行上面查询语句,得到以下结果:
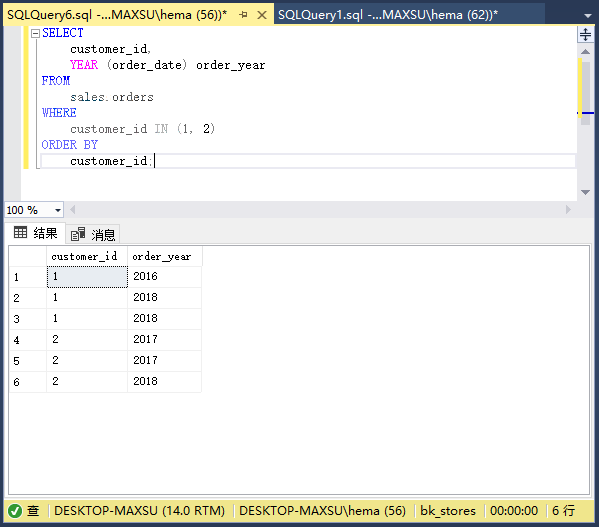
在此示例中,检索了客户ID为`1`,列是:`customer_id`和`order_date`。
从输出中可以清楚地看到,ID为`1`的客户在`2016`年下了一个订单,在`2018`年下了两个订单。ID为`2`的客户在`2017`年下了两个订单,在`2018`年下了一个订单。
在查询中添加一个`GROUP BY`子句来查看效果:
~~~sql
SELECT
customer_id,
YEAR (order_date) order_year
FROM
sales.orders
WHERE
customer_id IN (1, 2)
GROUP BY
customer_id,
YEAR (order_date)
ORDER BY
customer_id;
~~~
执行上面查询语句,得到以下结果:
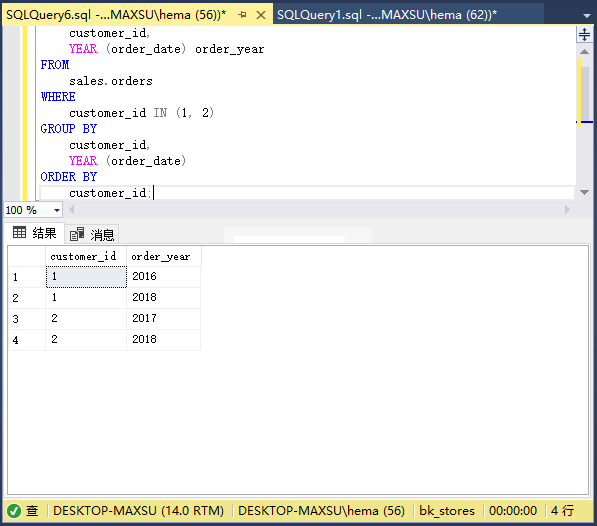
`GROUP BY`子句将前三行分为两组,接下来的三行分为另外两组,具有客户ID和订单年份的唯一组合。
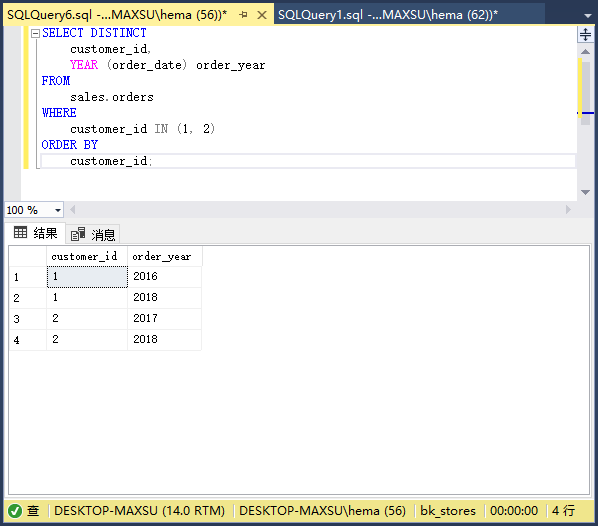
从功能上讲,上面查询中的`GROUP BY`子句产生的结果与使用`DISTINCT`子句的以下查询的结果相同:
~~~sql
SELECT DISTINCT
customer_id,
YEAR (order_date) order_year
FROM
sales.orders
WHERE
customer_id IN (1, 2)
ORDER BY
customer_id;
~~~
执行上面查询语句,得到以下结果:
#### 1\. GROUP BY子句和聚合函数
实际上,`GROUP BY`子句通常与聚合函数一起用于生成摘要报告。
聚合函数对组执行计算并返回每个组的唯一值。 例如,`COUNT()`函数返回每个组中的行数。 其他常用的聚合函数是:`SUM()`,`AVG()`,`MIN()`,`MAX()`。
`GROUP BY`子句将行排列成组,聚合函数返回每个组的摘要(总数量,最小值,最大值,平均值,总和等)。
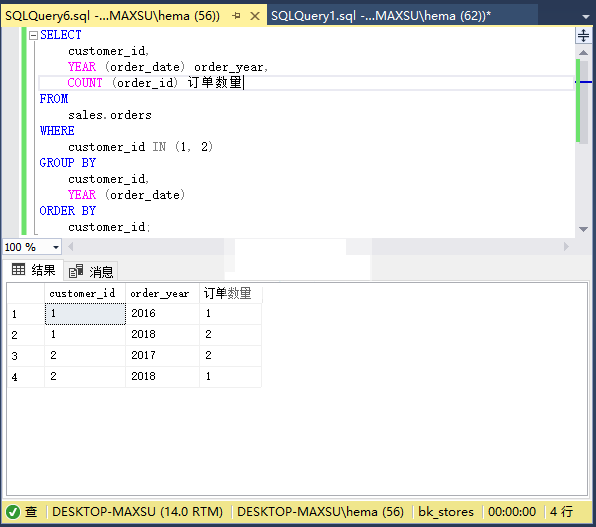
例如,以下查询返回客户按年度下达的订单数:
~~~sql
SELECT
customer_id,
YEAR (order_date) order_year,
COUNT (order_id) 订单数量
FROM
sales.orders
WHERE
customer_id IN (1, 2)
GROUP BY
customer_id,
YEAR (order_date)
ORDER BY
customer_id;
~~~
执行上面查询语句,得到以下结果:
如果要引用`GROUP BY`子句中未列出的任何列或表达式,则必须使用该列作为聚合函数的输入。 否则,数据库系统将会提示错误,因为无法保证列或表达式将为每个组返回单个值。 例如,以下查询将失败:
~~~sql
SELECT
customer_id,
YEAR (order_date) order_year,
order_status
FROM
sales.orders
WHERE
customer_id IN (1, 2)
GROUP BY
customer_id,
YEAR (order_date)
ORDER BY
customer_id;
~~~
> 这是因为`order_status`列未在`GROUP BY`子句中。
#### 2\. 更多GROUP BY子句示例
下面再举几个例子来理解`GROUP BY`子句的工作原理。
**2.1. 带有COUNT()函数示例的GROUP BY子句**
以下查询返回每个城市的客户数量:
~~~sql
SELECT
city,
COUNT (customer_id) customer_count
FROM
sales.customers
GROUP BY
city
ORDER BY
city;
~~~
执行上面查询语句,得到以下结果:
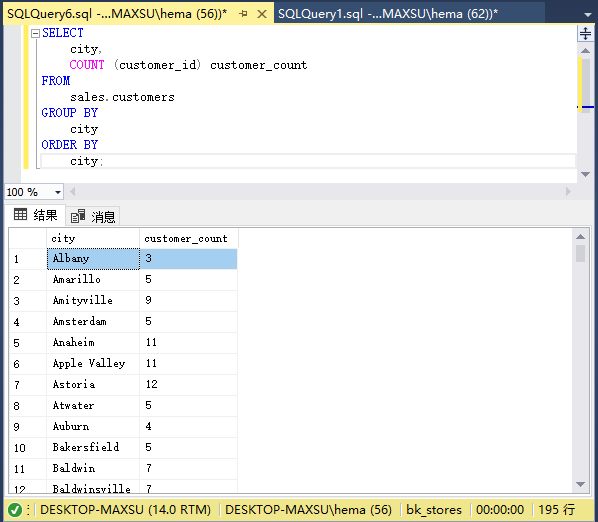
在此示例中,`GROUP BY`子句按城市将客户分组,`COUNT`函数返回每个城市的客户数。
同样,以下查询按州和城市返回客户数量。
~~~sql
SELECT
city,
state,
COUNT (customer_id) customer_count
FROM
sales.customers
GROUP BY
state,
city
ORDER BY
city,
state;
~~~
执行上面查询语句,得到以下结果:
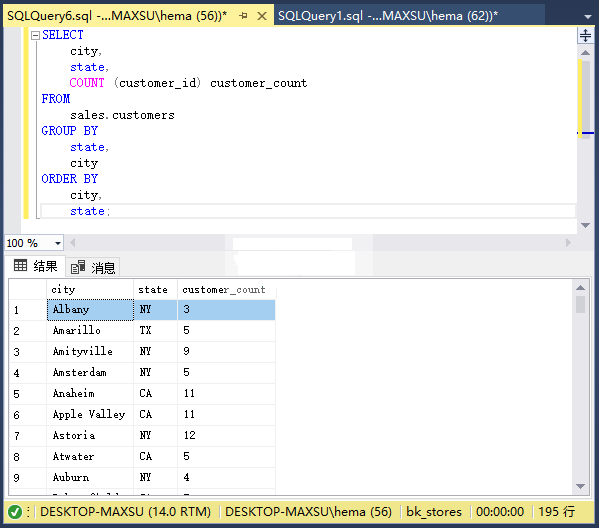
**2.2. GROUP BY子句带有MIN和MAX函数示例**
以下声明返回所有型号年份为`2018`的最低和最高价产品:
~~~sql
SELECT
brand_name,
MIN (list_price) min_price,
MAX (list_price) max_price
FROM
production.products p
INNER JOIN production.brands b ON b.brand_id = p.brand_id
WHERE
model_year = 2018
GROUP BY
brand_name
ORDER BY
brand_name;
~~~
执行上面查询语句,得到以下结果:
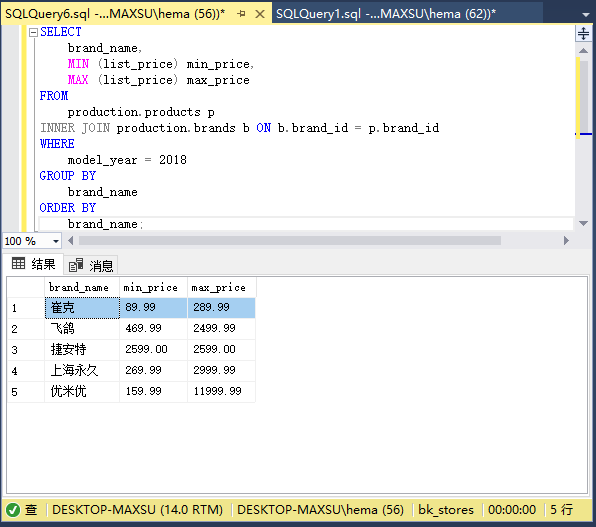
在此示例中,`WHERE`子句在`GROUP BY`子句之前。
**2.3. 带有AVG()函数示例的GROUP BY子句**
以下语句使用`AVG()`函数返回型号年份为`2018`年的所有产品的平均价格:
~~~sql
SELECT
brand_name,
AVG (list_price) avg_price
FROM
production.products p
INNER JOIN production.brands b ON b.brand_id = p.brand_id
WHERE
model_year = 2018
GROUP BY
brand_name
ORDER BY
brand_name;
~~~
执行上面查询语句,得到以下结果:
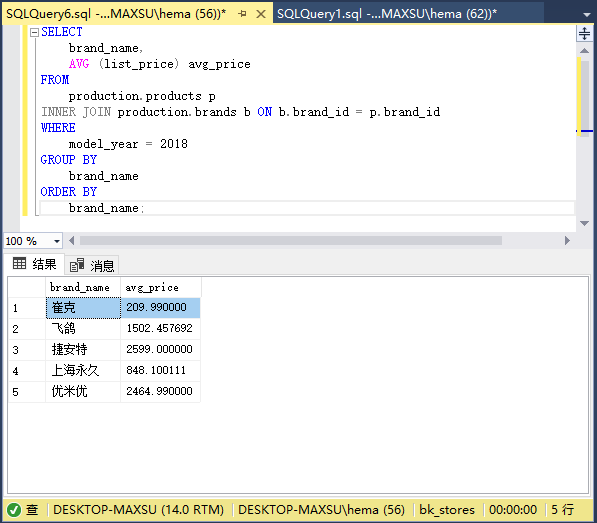
**2.4. 带有SUM函数示例的GROUP BY子句**
请参阅以下`order_items`表:

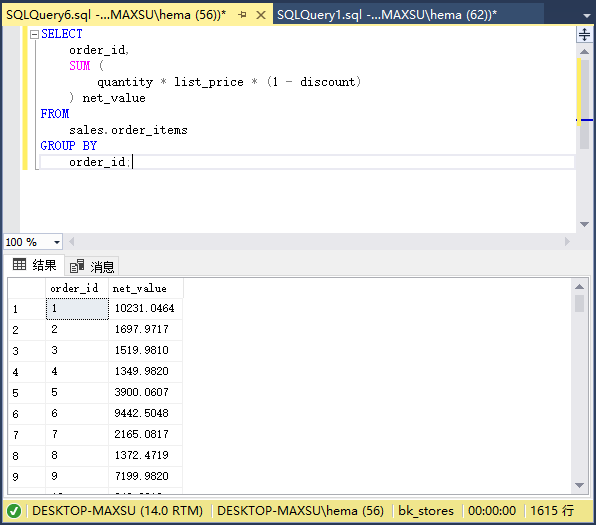
以下查询使用`SUM()`函数获取每个订单的净值:
~~~sql
SELECT
order_id,
SUM (
quantity * list_price * (1 - discount)
) net_value
FROM
sales.order_items
GROUP BY
order_id;
~~~
执行上面查询语句,得到以下结果:
>[danger] ## HAVING - 指定组或聚合的搜索条件。
在本教程中,将学习如何使用SQL Server `HAVING`子句根据指定的条件筛选组。
`HAVING`子句通常与GROUP BY子句一起使用,以根据指定的条件列表过滤分组。 以下是`HAVING`子句的语法:
~~~sql
SELECT
select_list
FROM
table_name
GROUP BY
group_list
HAVING
conditions;
~~~
在此语法中,`GROUP BY`子句将行汇总为分组,`HAVING`子句将一个或多个条件应用于这些每个分组。 只有使条件评估为`TRUE`的组才会包含在结果中。 换句话说,过滤掉条件评估为`FALSE`或`UNKNOWN`的组。
因为SQL Server在`GROUP BY`子句之后处理`HAVING`子句,所以不能通过使用列别名来引用选择列表中指定的聚合函数。以下查询将失败:
~~~sql
SELECT
column_name1,
column_name2,
aggregate_function (column_name3) column_alias
FROM
table_name
GROUP BY
column_name1,
column_name2
HAVING
column_alias > value;
~~~
必须明确使用`HAVING`子句中的聚合函数表达式,如下所示:
~~~sql
SELECT
column_name1,
column_name2,
aggregate_function (column_name3) alias
FROM
table_name
GROUP BY
column_name1,
column_name2
HAVING
aggregate_function (column_name3) > value;
~~~
## SQL Server HAVING示例
下面举一些例子来理解`HAVING`子句的工作原理。
#### 1\. HAVING子句与COUNT函数示例
请参阅示例数据库中的以下`orders`表:

以下声明查找每年至少下过两个订单的客户:
~~~sql
SELECT
customer_id,
YEAR (order_date),
COUNT (order_id) order_count
FROM
sales.orders
GROUP BY
customer_id,
YEAR (order_date)
HAVING
COUNT (order_id) >= 2
ORDER BY
customer_id;
~~~
执行上面查询语句,得到以下结果:
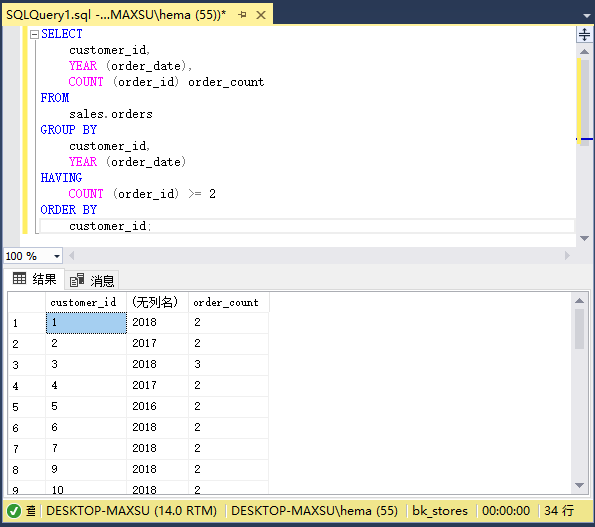
在上面查询示例中,
* 首先,`GROUP BY`子句按客户和订单年份对销售订单进行分组。 `COUNT()`函数返回每个客户每年下达的订单数。
* 其次,`HAVING`子句筛选出订单数至少为`2`的所有客户。
#### 2\. HAVING子句与SUM()函数的例子
请考虑以下`order_items`表:

以下语句查找净值大于`20000`的销售订单:
~~~sql
SELECT
order_id,
SUM (
quantity * list_price * (1 - discount)
) net_value
FROM
sales.order_items
GROUP BY
order_id
HAVING
SUM (
quantity * list_price * (1 - discount)
) > 20000
ORDER BY
net_value;
~~~
执行上面查询语句,得到以下结果:
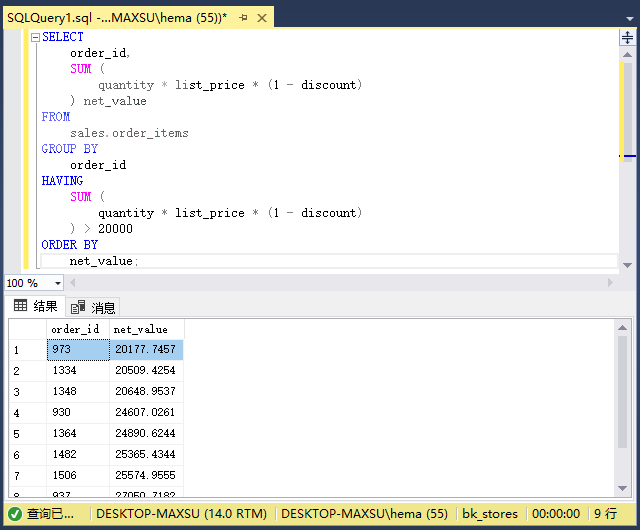
在这个例子中:
* 首先,`SUM`函数计算销售订单的净值。
* 其次,`HAVING`子句过滤净值小于或等于`20000`的销售订单。
#### 3\. HAVING子句与MAX和MIN函数的示例
请参阅以下`products`表:

以下语句首先查找每个产品类别中的最大和最小价格。 然后,它筛选出最大价格大于`4000`或最小价格小于`500`的类别:
~~~sql
SELECT
category_id,
MAX (list_price) max_list_price,
MIN (list_price) min_list_price
FROM
production.products
GROUP BY
category_id
HAVING
MAX (list_price) > 4000 OR MIN (list_price) < 500;
~~~
执行上面查询语句,得到以下结果:
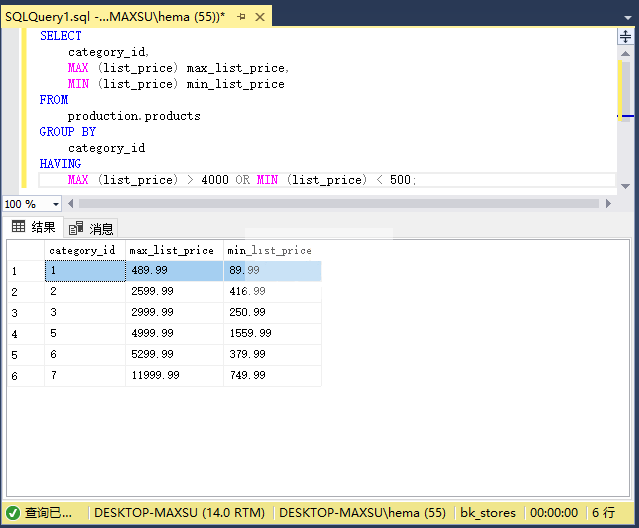
#### 4\. HAVING子句与AVG()函数示例
以下语句查找平均价格介于`500`和`1000`之间的产品类别:
~~~sql
SELECT
category_id,
AVG (list_price) avg_list_price
FROM
production.products
GROUP BY
category_id
HAVING
AVG (list_price) BETWEEN 500 AND 1000;
~~~
执行上面查询语句,得到以下结果:

>[danger] ## GROUPING SETS - 生成多个分组集。
#### 设置销售摘要表
为了方便演示,下面创建一个名为`sales.sales_summary`的新表。
~~~sql
SELECT
b.brand_name AS brand,
c.category_name AS category,
p.model_year,
round(
SUM (
quantity * i.list_price * (1 - discount)
),
0
) sales INTO sales.sales_summary
FROM
sales.order_items i
INNER JOIN production.products p ON p.product_id = i.product_id
INNER JOIN production.brands b ON b.brand_id = p.brand_id
INNER JOIN production.categories c ON c.category_id = p.category_id
GROUP BY
b.brand_name,
c.category_name,
p.model_year
ORDER BY
b.brand_name,
c.category_name,
p.model_year;
~~~
在此查询中,按品牌和类别检索销售额数据,并将其填充到`sales.sales_summary`表中。
以下查询从`sales.sales_summary`表返回数据:
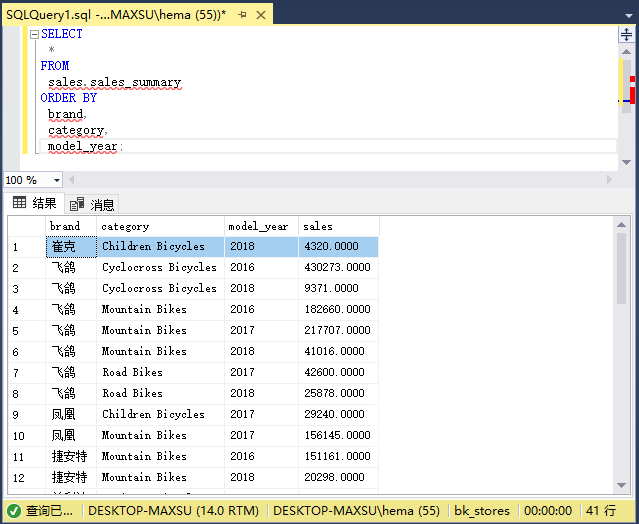
#### SQL Server GROUPING SETS入门
根据定义,分组集是分组的一组列。 通常,具有聚合的单个查询定义单个分组集。
例如,以下查询定义了一个分组集,其中包括品牌和类别,表示为(品牌,类别)。 查询返回按品牌和类别分组的销售额:
~~~sql
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
brand,
category
ORDER BY
brand,
category;
~~~
执行上面查询语句,得到以下结果:
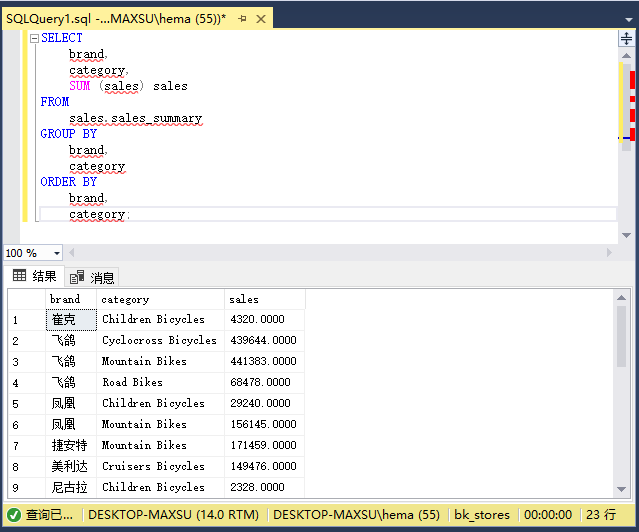
以下查询按品牌返回销售额。它定义了一个分组集(品牌):
~~~sql
SELECT
brand,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
brand
ORDER BY
brand;
~~~
执行上面查询语句,得到以下结果:
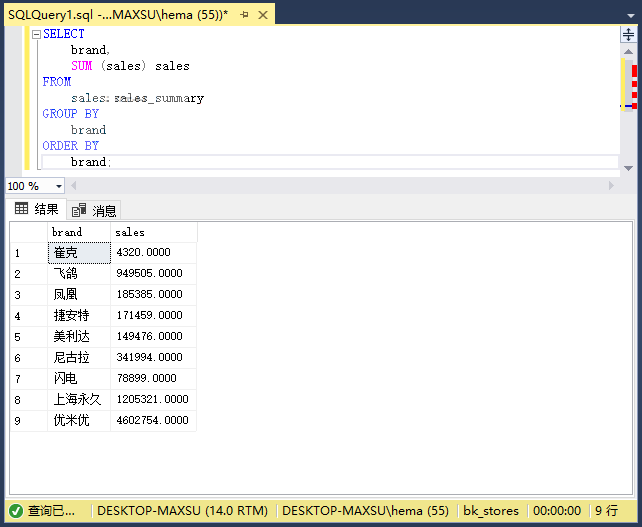
以下查询按类别返回销售额。 它定义了一个分组集(类别):
~~~sql
SELECT
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
category
ORDER BY
category;
~~~
执行上面查询语句,得到以下结果:
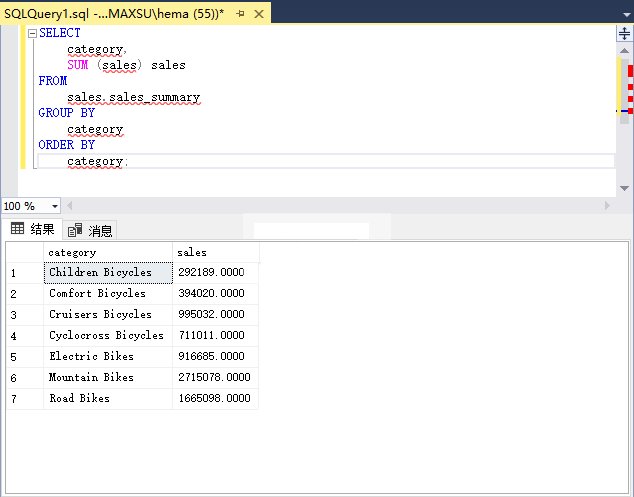
以下查询定义空分组集。 它返回所有品牌和类别的销售额。
~~~sql
SELECT
SUM (sales) sales
FROM
sales.sales_summary;
~~~
执行上面查询语句,得到以下结果:
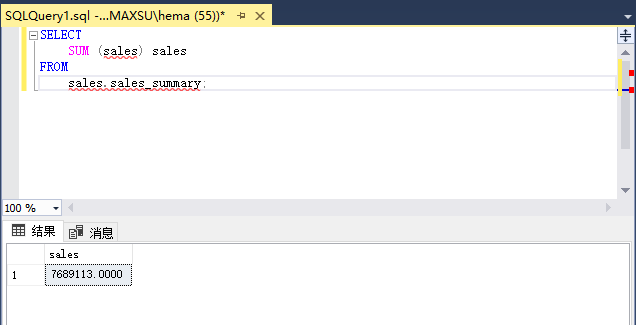
上面的四个查询返回四个结果集,其中包含四个分组集:
~~~shell
(brand, category)
(brand)
(category)
()
~~~
要使用所有分组集的聚合数据获得统一的结果集,可以使用`UNION ALL`运算符。
由于UNION ALL运算符要求所有结果集具有相同数量的列,因此需要将NULL添加到查询的选择列表中,如下所示:
~~~sql
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
brand,
category
UNION ALL
SELECT
brand,
NULL,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
brand
UNION ALL
SELECT
NULL,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
category
UNION ALL
SELECT
NULL,
NULL,
SUM (sales)
FROM
sales.sales_summary
ORDER BY brand, category;
~~~
执行上面查询语句,得到以下结果:

该查询生成了一个结果,其中包含了我们所期望的所有分组集的聚合。
但是,它有以下两个主要问题:
* 查询非常冗长(看起来是不是很累?)
* 查询很慢,因为SQL Server需要执行四个查询并将结果集合并为一个查询。
为了解决这些问题,SQL Server提供了一个名为`GROUPING SETS`的`GROUP BY`子句的子句。
`GROUPING SETS`在同一查询中定义多个分组集。 以下是`GROUPING SETS`的一般语法:
~~~sql
SELECT
column1,
column2,
aggregate_function (column3)
FROM
table_name
GROUP BY
GROUPING SETS (
(column1, column2),
(column1),
(column2),
()
);
~~~
此查询创建四个分组集:
~~~shell
(column1,column2)
(column1)
(column2)
()
~~~
使用此`GROUPING SETS`重写获取销售数据的查询,如下所示:
~~~sql
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
GROUPING SETS (
(brand, category),
(brand),
(category),
()
)
ORDER BY
brand,
category;
~~~
执行上面查询语句,得到以下结果:
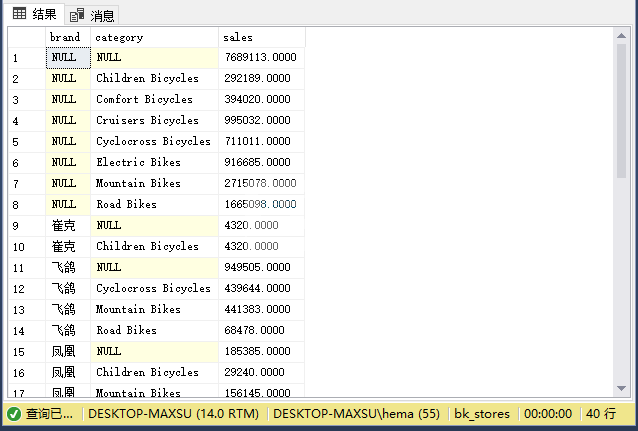
如上所示,查询产生的结果与使用`UNION ALL`运算符的结果相同。 但是,此查询更具可读性,当然也更有效。
**GROUPING函数**
`GROUPING`函数指示是否聚合`GROUP BY`子句中的指定列。 它是聚合则返回`1`,或者为结果集是未聚合返回`0`。
请参阅以下查询示例:
~~~sql
SELECT
GROUPING(brand) grouping_brand,
GROUPING(category) grouping_category,
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
GROUPING SETS (
(brand, category),
(brand),
(category),
()
)
ORDER BY
brand,
category;
~~~
执行上面查询语句,得到以下结果:
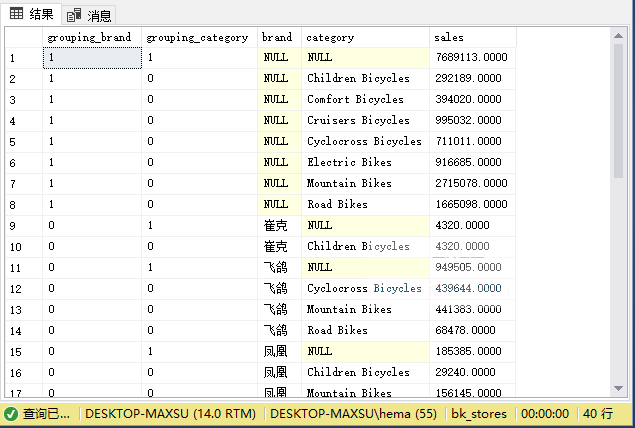
`grouping_brand`列中的值表示该行是否已聚合,`1`表示销售额按品牌汇总,`0`表示销售金额未按品牌汇总。 相同的概念应用于`grouping_category`列。
>[danger] ## CUBE - 生成包含维列的所有组合的分组集。
## SQL Server CUBE简介
分组集在单个查询中指定数据分组。 例如,以下查询定义表示为(品牌)的单个分组集:
~~~sql
SELECT
brand,
SUM(sales)
FROM
sales.sales_summary
GROUP BY
brand;
~~~
如果您没有学习过GROUPING SETS的使用,可使用以下查询创建`sales.sales_summary`表:
~~~sql
SELECT
b.brand_name AS brand,
c.category_name AS category,
p.model_year,
round(
SUM (
quantity * i.list_price * (1 - discount)
),
0
) sales INTO sales.sales_summary
FROM
sales.order_items i
INNER JOIN production.products p ON p.product_id = i.product_id
INNER JOIN production.brands b ON b.brand_id = p.brand_id
INNER JOIN production.categories c ON c.category_id = p.category_id
GROUP BY
b.brand_name,
c.category_name,
p.model_year
ORDER BY
b.brand_name,
c.category_name,
p.model_year;
~~~
即使以下查询不使用GROUP BY子句,它也会生成一个空的分组集,表示为`()`。
~~~sql
SELECT
SUM(sales)
FROM
sales.sales_summary
GROUP BY
brand;
~~~
`CUBE`是`GROUP BY`子句的子句,用于生成多个分组集。 以下是`CUBE`的一般语法:
~~~sql
SELECT
d1,
d2,
d3,
aggregate_function (c4)
FROM
table_name
GROUP BY
CUBE (d1, d2, d3);
~~~
在此语法中,`CUBE`根据在`CUBE`子句中指定的维度列:`d1`,`d2`和`d3`生成所有可能的分组集。
上面的查询返回与以下查询相同的结果集,该查询使用`GROUPING SETS`:
~~~sql
SELECT
d1,
d2,
d3,
aggregate_function (c4)
FROM
table_name
GROUP BY
GROUPING SETS (
(d1,d2,d3),
(d1,d2),
(d1,d3),
(d2,d3),
(d1),
(d2),
(d3),
()
);
~~~
如果在多维数据集中指定了`N`维列,则将具有`2N`个分组集。
通过部分使用`CUBE`可以减少分组集的数量,如以下查询所示:
~~~sql
SELECT
d1,
d2,
d3,
aggregate_function (c4)
FROM
table_name
GROUP BY
d1,
CUBE (d2, d3);
~~~
在这种情况下,查询生成四个分组集,因为在`CUBE`中只指定了两个维列。
## SQL Server CUBE示例
以下语句使用`CUBE`生成四个分组集:
~~~shell
(brand, category)
(brand)
(category)
()
~~~
参考以下查询语句:
~~~sql
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
CUBE(brand, category);
~~~
执行上面查询语句,得到以下结果:
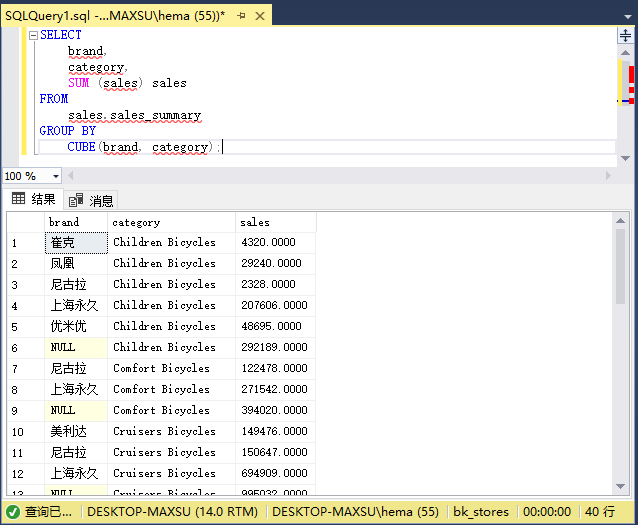
在此示例中,在`CUBE`子句中指定了两个维列,因此,我们总共有四个分组集。
以下示例说明如何执行部分`CUBE`以减少查询生成的分组集的数量:
~~~sql
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
brand,
CUBE(category);
~~~
执行上面查询语句,得到以下结果:
>[danger] ## ROLLUP - 生成分组集,假设输入列之间存在层次结构。
## SQL Server ROLLUP简介
SQL Server `ROLLUP`是`GROUP BY`子句的子句,它提供了定义多个分组集的简写。 与CUBE子句不同,`ROLLUP`不会根据维度列创建所有可能的分组集; `CUBE`是其中的一部分。
生成分组集时,`ROLLUP`假定维度列之间存在层次结构,并且仅基于此层次结构生成分组集。
`ROLLUP`通常用于生成小计和总计来生成报告目的。
考虑一个例子。 以下`CUBE(d1,d2,d3)`定义了八个可能的分组集:
~~~sql
(d1, d2, d3)
(d1, d2)
(d2, d3)
(d1, d3)
(d1)
(d2)
(d3)
()
~~~
并且`ROLLUP(d1,d2,d3)`仅创建四个分组集,假设层次结构`d1> d2> d3`,如下所示:
~~~sql
(d1, d2, d3)
(d1, d2)
(d1)
()
~~~
`ROLLUP`通常用于计算分层数据的聚合,例如:按年>季度>月的销售额。
## SQL Server ROLLUP语法
SQL Server `ROLLUP`的一般语法如下:
~~~sql
SELECT
d1,
d2,
d3,
aggregate_function(c4)
FROM
table_name
GROUP BY
ROLLUP (d1, d2, d3);
~~~
在此语法中,`d1`,`d2`和`d3`是维列。 该语句将根据层次结构`d1> d2> d3`计算列`c4`中的值的聚合。
还可以执行部分汇总以减少使用以下语法生成的小计:
~~~sql
SELECT
d1,
d2,
d3,
aggregate_function(c4)
FROM
table_name
GROUP BY
d1,
ROLLUP (d2, d3);
~~~
## SQL Server ROLLUP示例
在这个示例中将重用在GROUPING SETS教程中创建的`sales.sales_summary`表进行演示。 如果尚未创建`sales.sales_summary`表,则可以使用以下语句创建它。
~~~sql
SELECT
b.brand_name AS brand,
c.category_name AS category,
p.model_year,
round(
SUM (
quantity * i.list_price * (1 - discount)
),
0
) sales INTO sales.sales_summary
FROM
sales.order_items i
INNER JOIN production.products p ON p.product_id = i.product_id
INNER JOIN production.brands b ON b.brand_id = p.brand_id
INNER JOIN production.categories c ON c.category_id = p.category_id
GROUP BY
b.brand_name,
c.category_name,
p.model_year
ORDER BY
b.brand_name,
c.category_name,
p.model_year;
~~~
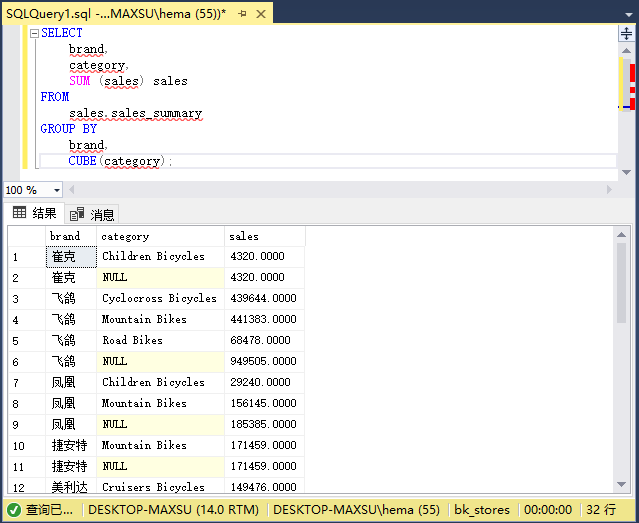
以下查询使用`ROLLUP`按品牌(小计)以及品牌和类别(总计)计算销售额。
~~~sql
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
ROLLUP(brand, category);
~~~
执行上面查询语句,得到以下结果:
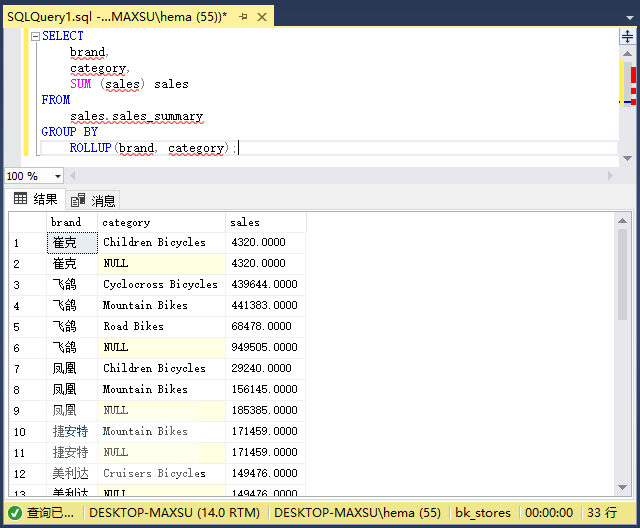
在此示例中,查询假定品牌和类别之间存在层次结构,即:品牌>类别。
请注意,如果更改品牌和类别的顺序,结果将会有所不同,如以下查询所示:
~~~sql
SELECT
category,
brand,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
ROLLUP (category, brand);
~~~
在此示例中,层次结构是类别>品牌,执行上面查询语句,得到以下结果:
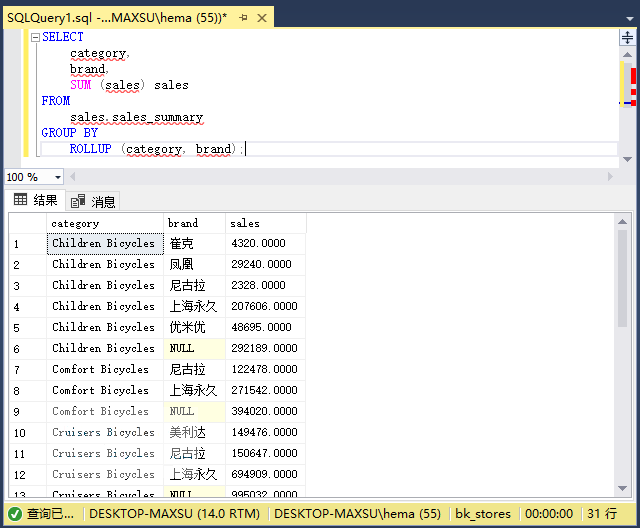
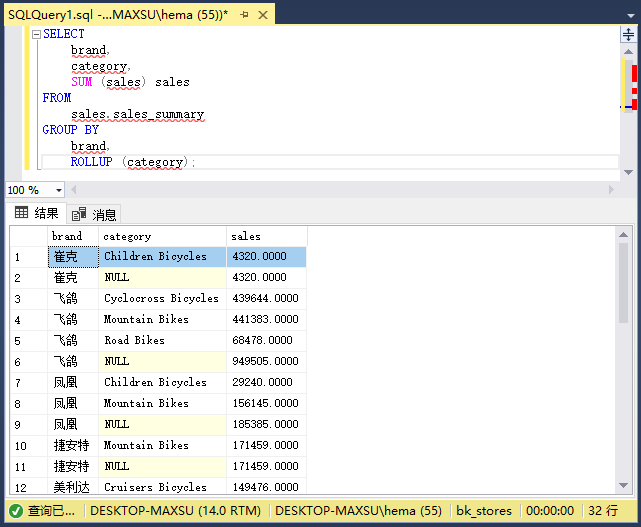
以下语句显示了如何执行部分汇总:
~~~sql
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
brand,
ROLLUP (category);
~~~
执行上面查询语句,得到以下结果:
- 第一章-测试理论
- 1.1软件测试的概念
- 1.2测试的分类
- 1.3软件测试的流程
- 1.4黑盒测试的方法
- 1.5AxureRP的使用
- 1.6xmind,截图工具的使用
- 1.7测试计划
- 1.8测试用例
- 1.9测试报告
- 2.0 正交表附录
- 第二章-缺陷管理工具
- 2.1缺陷的内容
- 2.2书写规范
- 2.3缺陷的优先级
- 2.4缺陷的生命周期
- 2.5缺陷管理工具简介
- 2.6缺陷管理工具部署及使用
- 2.7软件测试基础面试
- 第三章-数据库
- 3.1 SQL Server简介及安装
- 3.2 SQL Server示例数据库
- 3.3 SQL Server 加载示例
- 3.3 SQL Server 中的数据类型
- 3.4 SQL Server 数据定义语言DDL
- 3.5 SQL Server 修改数据
- 3.6 SQL Server 查询数据
- 3.7 SQL Server 连表
- 3.8 SQL Server 数据分组
- 3.9 SQL Server 子查询
- 3.10.1 SQL Server 集合操作符
- 3.10.2 SQL Server聚合函数
- 3.10.3 SQL Server 日期函数
- 3.10.4 SQL Server 字符串函数
- 第四章-linux
- 第五章-接口测试
- 5.1 postman 接口测试简介
- 5.2 postman 安装
- 5.3 postman 创建请求及发送请求
- 5.4 postman 菜单及设置
- 5.5 postman New菜单功能介绍
- 5.6 postman 常用的断言
- 5.7 请求前脚本
- 5.8 fiddler网络基础及fiddler简介
- 5.9 fiddler原理及使用
- 5.10 fiddler 实例
- 5.11 Ant 介绍
- 5.12 Ant 环境搭建
- 5.13 Jmeter 简介
- 5.14 Jmeter 环境搭建
- 5.15 jmeter 初识
- 5.16 jmeter SOAP/XML-RPC Request
- 5.17 jmeter HTTP请求
- 5.18 jmeter JDBC Request
- 5.19 jmeter元件的作用域与执行顺序
- 5.20 jmeter 定时器
- 5.21 jmeter 断言
- 5.22 jmeter 逻辑控制器
- 5.23 jmeter 常用函数
- 5.24 soapUI概述
- 5.25 SoapUI 断言
- 5.26 soapUI数据源及参数化
- 5.27 SoapUI模拟REST MockService
- 5.28 Jenkins的部署与配置
- 5.29 Jmeter+Ant+Jenkins 搭建
- 5.30 jmeter脚本录制
- 5.31 badboy常见的问题
- 第六章-性能测试
- 6.1 性能测试理论
- 6.2 性能测试及LoadRunner简介
- 第七章-UI自动化
- 第八章-Maven
- 第九章-测试框架
- 第十章-移动测试
- 10.1 移动测试点及测试流程
- 10.2 移动测试分类及特点
- 10.3 ADB命令及Monkey使用
- 10.4 MonkeyRunner使用
- 10.5 appium工作原理及使用
- 10.6 Appium环境搭建(Java版)
- 10.7 Appium常用函数(Java版)
- 10.8 Appium常用函数(Python版)
- 10.9 兼容性测试