# 索引
## 定义
**索引**是帮助MySQL高效获取数据的**排好序**的**数据结构**
## 索引分类
索引类型|区别
---|---
普通索引|简单索引,数据可以为空
主键索引|主键索引。索引列唯一且不能为空;一张表只能有一个主键索引
唯一索引|数据必须是唯一的,但可以为空
联合索引|多个列联合到一起建立的索引,使用时有最左原则需要注意
全文索引|全文搜索的索引。用于搜索很长一篇文章的时候,效果最好。用在比较短的文本,如果就一两行字的,普通的 INDEX 也可以。
## 索引的数据类型
`B+tree`、`hash`
### 为什么没有用`二叉树`
#### 二叉树的定义
[二叉树]()
如果选择二叉树做索引的话假如说在主键建立索引,因为索引一般都是主键自增的,那就不会往树的左节点做插入,那索引树就会降级成为单向链表,如下图所示:
原始二叉树的查找`时间复杂度`是`O(1)`, 降级成为单向链表后的时间复杂度是`O(n)`
### 为什么没有选择`红黑树`
红黑树是一种含有红黑结点并能自平衡的二叉查找树。
虽然它能够自平衡,但是树的高度不可控,假如树高20 那就需要查询20次。也就是20次磁盘IO,如果数据量大的情况下,红黑树也是搞不定的。
### 为什么没有用`BTree`
在计算机科学中,B树(英语:B-tree)是一种自平衡的树(多叉平衡树),能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数时间内完成。B树,概括来说是一个一般化的二叉查找树(binary search tree)一个节点可以拥有2个以上的子节点。与自平衡二叉查找树不同,B树适用于读写相对大的数据块的存储系统,例如磁盘。B树减少定位记录时所经历的中间过程,从而加快存取速度。B树这种数据结构可以用来描述外部存储。这种数据结构常被应用在数据库和文件系统的实现上。
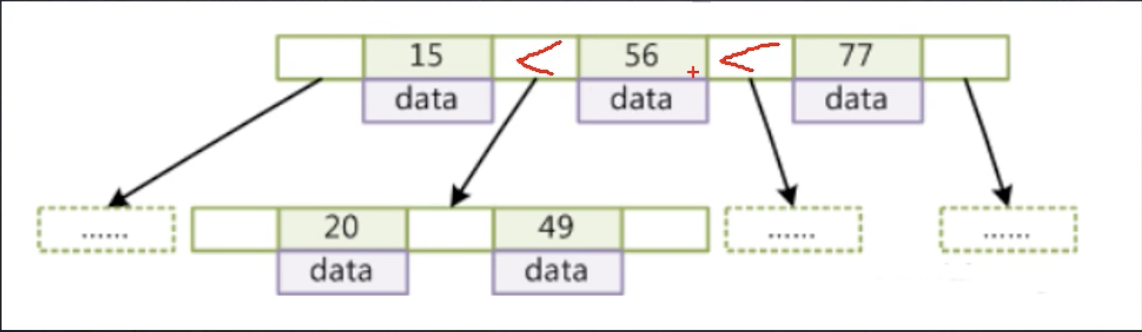
节点元素从左到右依次递增排列
子节点所有元素都在父节点区间内
没有选择B树的原因是因为B树的data是跟随每个子节点的而B+tree的的数据和节点是分开存放的数据存放在非叶子节点上 这样数据可以再有限的内存空间里面去维护更多的index
## B+tree
B+tree数据格式
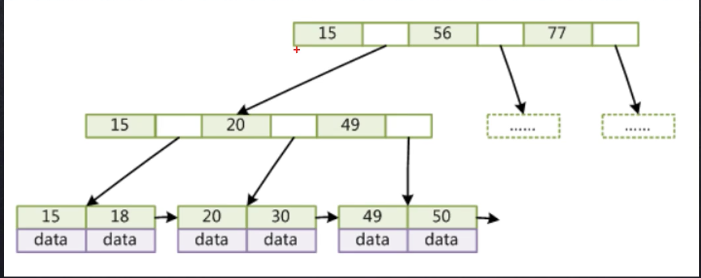
## hash
查询后经过hash运算可以快速获取到某个具体数据的磁盘地址,理论上定向的条件查询效率比较高,但是区间查询就没办法用索引了,所以不推荐hash
每次查找都会把数据load到内存中,从而提高查询效率
## index创建
ALTER TABLE `table_name` ADD INDEX `index_name` (`column_list`);
```shell script
ALTER TABLE user ADD INDEX index_name_city_age (NAME(16),CITY,AGE);
```
等价于
CREATE UNIQUE INDEX `index_name` ON `table_name` (`column_list`)
```shell script
CREATE INDEX user ON user (NAME(16),CITY,AGE)
```
### 其他创建语句
#### 主键索引
alter table `table_name` add primary key (`columns`);
#### 唯一索引
ALTER TABLE `table_name` ADD UNIQUE (`columns`);
#### 全文索引
ALTER TABLE `table_name` ADD FULLTEXT (`columns`);
## index删除
### 普通索引删除
DROP INDEX `index_name` ON `talbe_name`
等价于
ALTER TABLE `table_name` DROP INDEX `index_name`
### 主键索引删除
ALTER TABLE `table_name` DROP `PRIMARY KEY`
## index查看
show index from `table_name`;
## mysql索引命中过程
@todo
- 简介
- php
- php基础
- php常用数组函数
- php常用字符串函数
- php魔术方法
- php高阶
- swoole
- php优化
- workerman
- PHP底层运行机制和原理
- php框架
- laravel
- 前端
- react
- 爬虫
- Scrapy
- Linux
- IO复用
- nginx
- nginx进程工作原理
- nginx配置
- 正向代理反向代理
- UPSTREAM
- SERVER
- HTTPS
- queue
- kafka
- redis
- DB
- mysql
- 存储引擎
- 索引
- 锁
- 触发器
- 分库分表
- 三范式
- 负载均衡
- 事务
- EXPLAN
- mysql死锁
- mysql索引覆盖与回表
- mysql聚簇索引与非聚簇索引
- NoSql
- memcache
- redis
- mongo
- 网络协议
- tcp与udp
- https与http
- 架构
- LNMP架构下HTTP请求的调用次序
- 数据结构&算法
- 基础数据结构
- Linked List
- array
- stack
- queue
- tree
- hash
- heap
- 常见算法
- 排序算法
- 查找算法
- 其他
- php的一些坑
- 常问面试题
- 技术面试最后反问面试官的话
- hr
- redis缓存击穿、穿透、雪崩
- 面试中回答的不好的问题
- web攻击防范