
[TOC]
# React 的核心思想
React 最为核心的就是 Virtual DOM 和 Diff 算法。React 在内存中维护一颗虚拟 DOM 树,当数据发生改变时(state & props),会自动的更新虚拟 DOM,获得一个新的虚拟 DOM 树,然后通过 Diff 算法,比较新旧虚拟 DOM 树,找出最小的有变化的部分,将这个变化的部分(Patch)加入队列,最终批量的更新这些 Patch 到实际的 DOM 中。
<br>
<br>
# 传统 diff 算法
将一颗 Tree 通过最小操作步数映射为另一颗 Tree,这种算法称之为 Tree Edit Distance(树编辑距离)。如图:
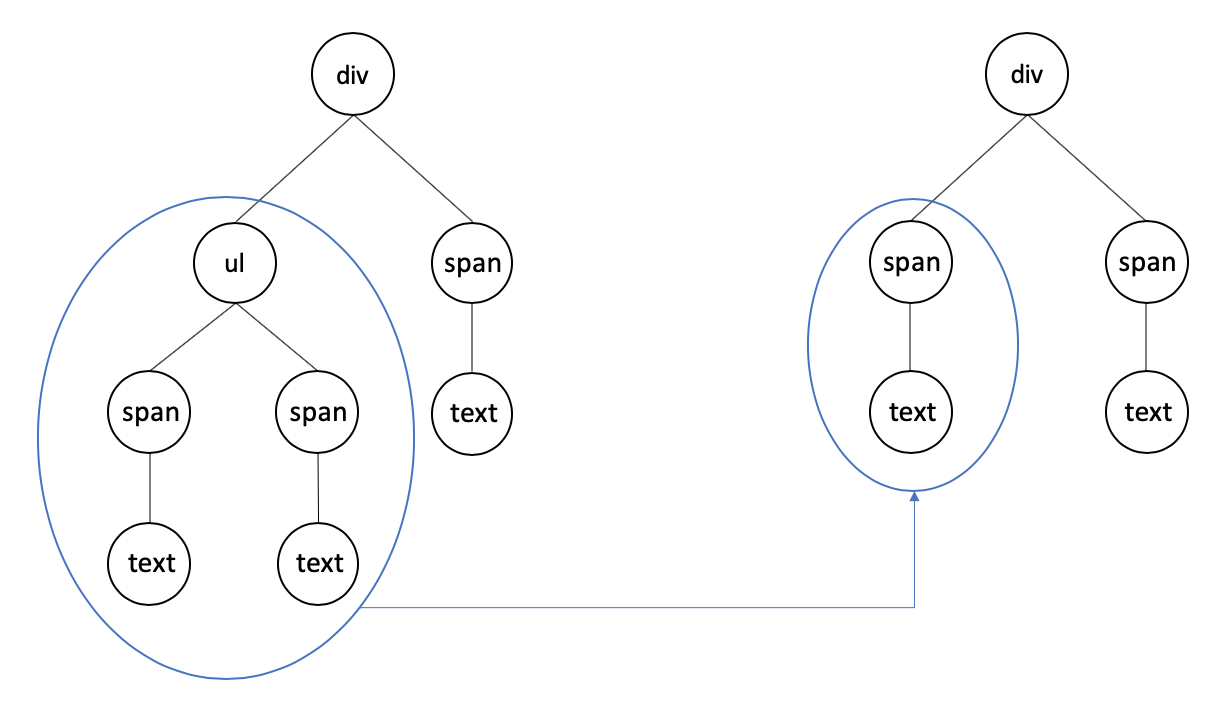
<br>
上图中,最小操作步数(编辑距离)为 3:
1. 删除 ul 节点
2. 添加 span 节点
3. 添加 text 节点
<br>
而 Tree Edit Distance 算法从 1979 年到 2011年,经过了30多年的发展演变,其时间复杂度最终被优化到 O(n^3),其发展历程大致如下(n 是树中节点的总数):
> 1. 1979年,Tai 提出了次个非幂级复杂度算法,时间复杂度为 O(m3\*n3)
> 2. 1989年,Zhang and Shasha 将 Tai 的算法进行优化,时间复杂度为 O(m2\*n2)
> 3. 1998年,Klein 将 Zhang and Shasha 的算法再次优化,时间复杂度为 O(n^2\*m\*log(m))
> 4. 2009年,Demiane 提出最坏情况下的计算公式,将时间复杂度控制在 O(n^2\*m\*(1+log(m/n)))
> 5. 2011年,Pawlik and N.Augsten 提出适用于所有形状的树的算法,并将时间复杂度控制在 O(n^3)
<br>
这里不会展开讨论 Tree Edit Distance 算法的具体实现和原理,有兴趣可以直接看这篇论文[A Robust Algorithm for the Tree Edit Distance](http://vldb.org/pvldb/vol5/p334_mateuszpawlik_vldb2012.pdf)
<br>
<br>
# React diff
传统 diff 算法其时间复杂度最优解是 O(n^3),那么如果有 1000 个节点,则一次 diff 就将进行 10 亿次比较,这显然无法达到高性能的要求。而 React 通过大胆的假设,并基于假设提出相关策略,成功的将 O(n^3) 复杂度的问题转化为 O(n) 复杂度的问题。
<br>
**两个假设**
为了优化 diff 算法,React 提出了两个假设:
1. 两个不同类型的元素会产生出不同的树
2. 开发者可以通过`key`prop 来暗示哪些子元素在不同的渲染下能保持稳定
<br>
**三个策略**
基于这上述两个假设,React 针对性的提出了三个策略以对 diff 算法进行优化:
1. Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计
2. 拥有相同类型的两个组件将会生成相似的树形结构,拥有不同类型的两个组件将会生成不同树形结构
3. 对于同一层级的一组子节点,它们可以通过唯一 key 进行区分
<br>
**diff 具体优化**
基于上述三个策略,React 分别对以下三个部分进行了 diff 算法优化
* tree diff
* component diff
* element diff
<br>
<br>
## tree diff
React 只对虚拟 DOM 树进行分层比较,不考虑节点的跨层级比较。如下图:
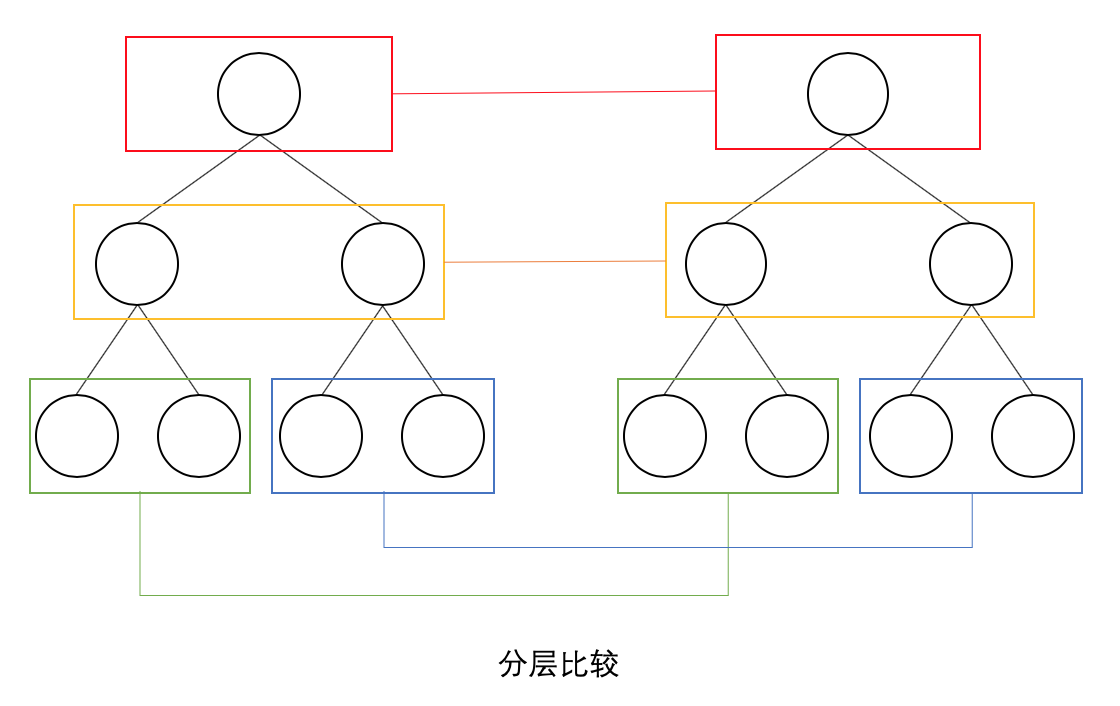
如上图,React 通过 updateDepth 对虚拟 Dom 树进行层级控制,只会对相同颜色框内的节点进行比较,根据对比结果,进行节点的新增和删除。如此只需要遍历一次虚拟 Dom 树,就可以完成整个的对比。
<br>
如果发生了跨层级的移动操作,如下图:
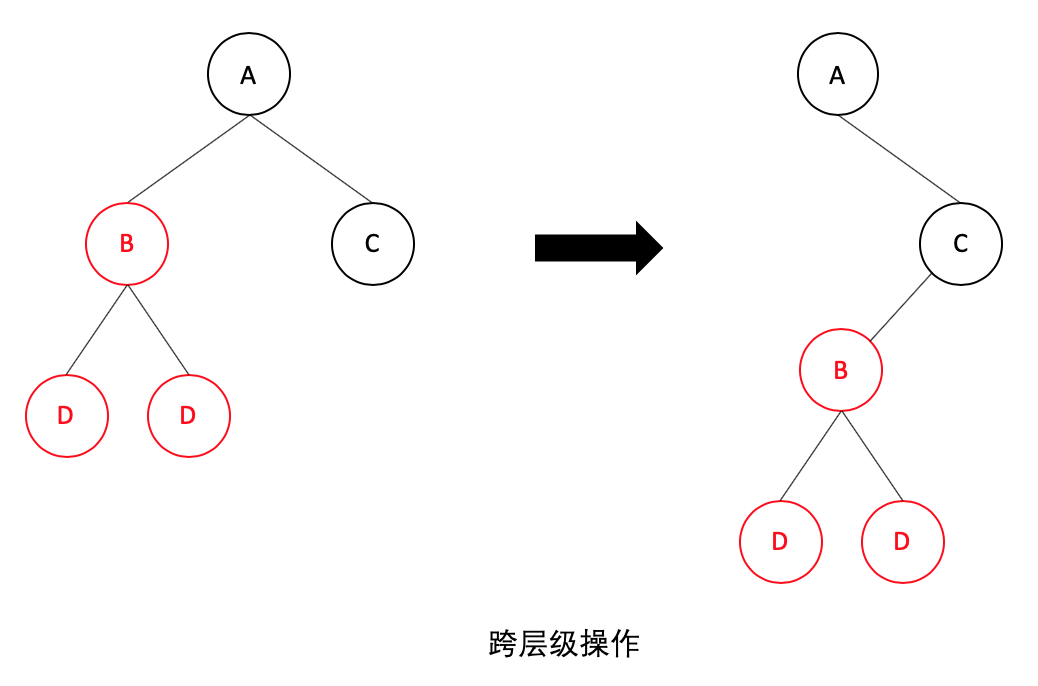
<br>
通过分层比较可知,React 并不会复用 B 节点及其子节点,而是会直接删除 A 节点下的 B 节点,然后再在 C 节点下创建新的 B 节点及其子节点。因此,如果发生跨级操作,React 是不能复用已有节点,可能会导致 React 进行大量重新创建操作,这会影响性能。所以 React 官方推荐尽量避免跨层级的操作。
<br>
<br>
## component diff
React 是基于组件构建的,对于组件间的比较所采用的策略如下:
* 如果是同类型组件,首先使用`shouldComponentUpdate()`方法判断是否需要进行比较,如果返回`true`,继续按照 React diff 策略比较组件的虚拟 DOM 树,否则不需要比较
* 如果是不同类型的组件,则将该组件判断为 dirty component,从而替换整个组件下的所有子节点
<br>
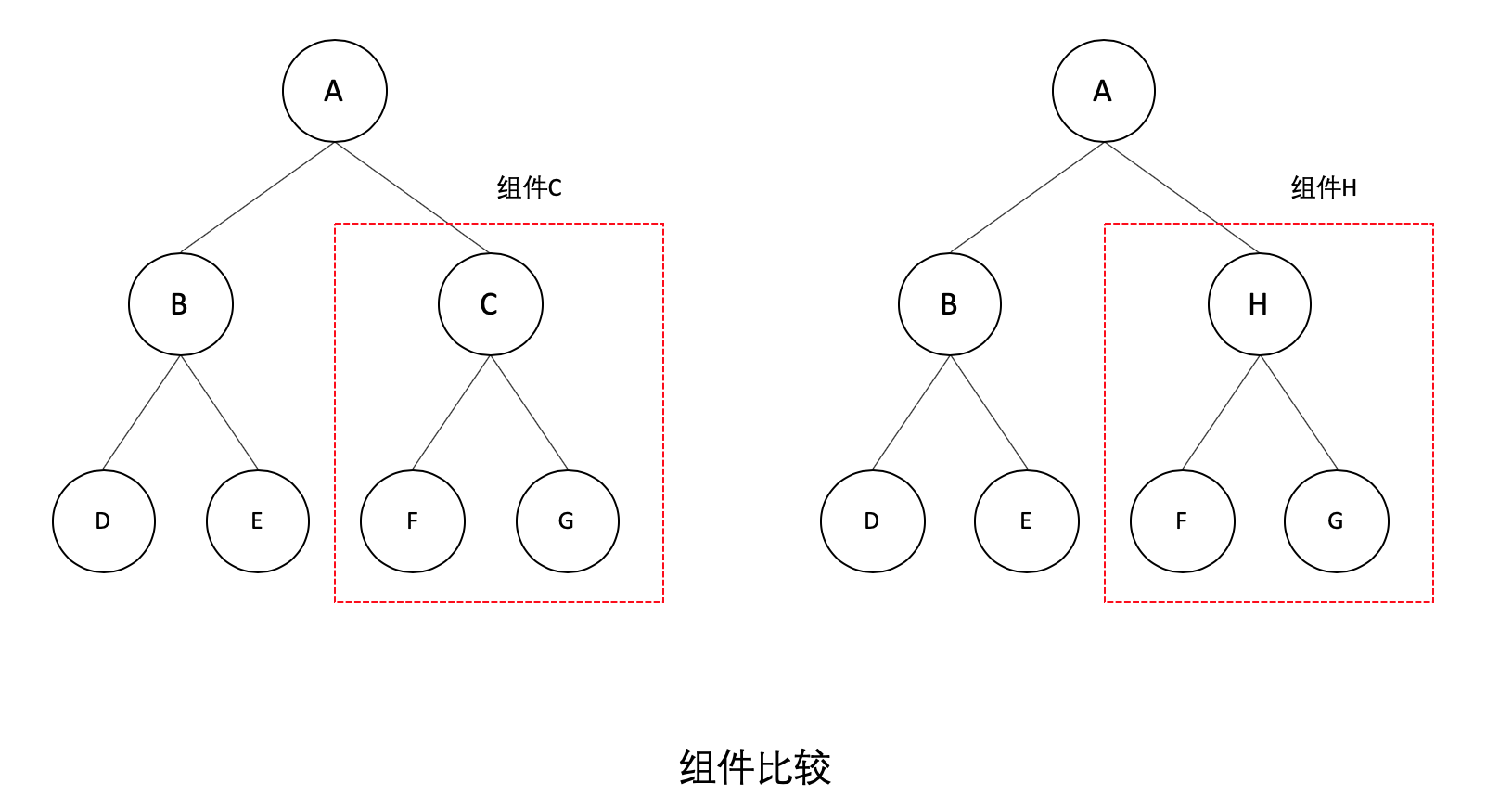
如上图,虽然组件 C 和组件 H 结构相似,但类型不同,React 不会进行比较,会直接删除组件 C,创建组件 H。
<br>
从上述 component diff 策略可以知道:
1. 对于不同类型的组件,默认不需要进行比较操作,直接重新创建。
2. 对于同类型组件, 通过让开发人员自定义`shouldComponentUpdate()`方法来进行比较优化,减少组件不必要的比较。如果没有自定义,`shouldComponentUpdate()`方法默认返回`true`,默认每次组件发生数据(state & props)变化时,都会进行比较。
<br>
## element diff
element diff 涉及三种操作:移动、创建、删除。对于同一层级的子节点,对于是否使用 key 分别进行讨论。
<br>
对于不使用 key 的情况,如下图:
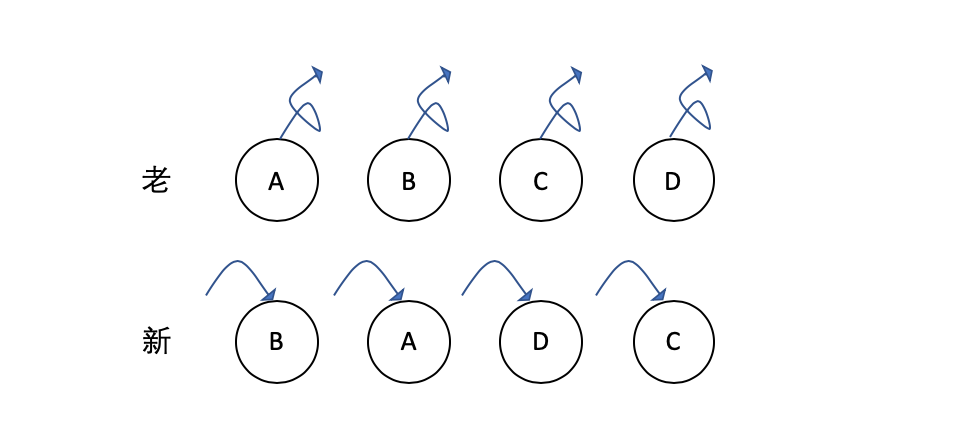
React 对新老同一层级的子节点对比,发现新集合中的 B 不等于老集合中的 A,于是删除 A,创建 B,依此类推,直到删除 D,创建 C。这会使得相同的节点不能复用,出现频繁的删除和创建操作,从而影响性能。
<br>
对于使用 key 的情况,如下图:
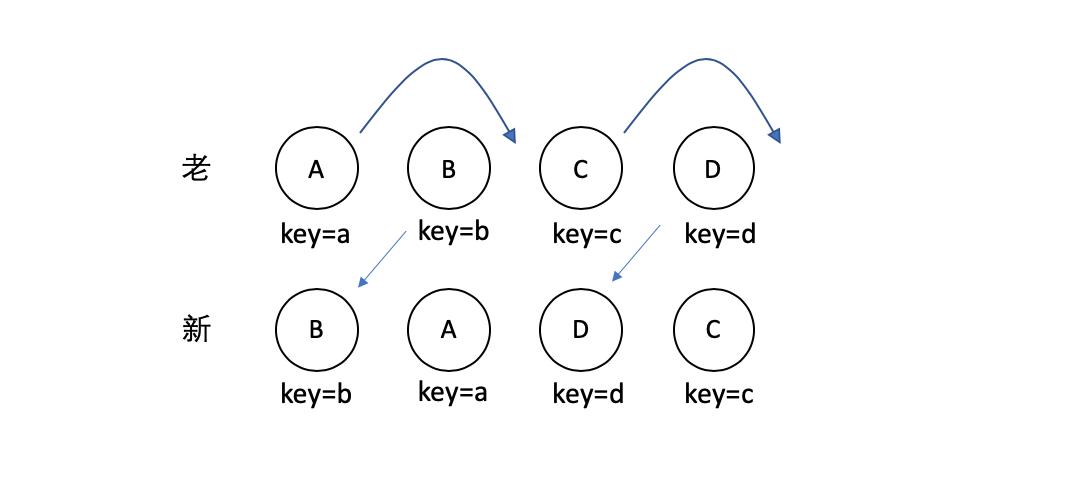
<br>
React 首先会对新集合进行遍历,通过唯一 key 来判断老集合中是否存在相同的节点,如果没有则创建,如果有的,则判断是否需要进行移动操作。并且 React 对于移动操作也采用了比较高效的算法,使用了一种顺序优化手段,这里不做详细讨论。
<br>
从上述可知,element diff 就是通过唯一 key 来进行 diff 优化,通过复用已有的节点,减少节点的删除和创建操作。
<br>
**如何进行 diff**
上面已经说完了 React 的 diff 策略和具体优化,这里简单谈一下 React 是如何应用这些策略来进行 diff :
<br>
React 是基于组件构建的,首先可以将整个虚拟 DOM 树,抽象为 React 组件树(每一个组件又是由一颗更小的组件树构成,依次类推),将 React diff 策略应用比较这颗组件树,若其中某个组件需要进行比较,将这个组件看成一颗较小的组件树,继续用 React diff 策略比较这颗较小的组件树,依次类推,直到层次遍历完所有的需要比较的组件。
<br>
# 小结
React 通过大胆的假设,制定对应的 diff 策略,将 O(n3) 复杂度的问题转换成 O(n) 复杂度的问题
* 通过分层对比策略,对 tree diff 进行算法优化
* 通过相同类生成相似树形结构,不同类生成不同树形结构以及`shouldComponentUpdate`策略,对 component diff 进行算法优化
* 通过设置唯一 key 策略,对 element diff 进行算法优化
<br>
综上,tree diff 和 component diff 是从顶层设计上降低了算法复杂度,而 element diff 则在在更加细节上做了进一步优化。
<br>
<br>
# 参考资料
* [深入理解React:diff 算法](https://www.cnblogs.com/forcheng/p/13246874.html)
- 第一部分 HTML
- meta
- meta标签
- HTML5
- 2.1 语义
- 2.2 通信
- 2.3 离线&存储
- 2.4 多媒体
- 2.5 3D,图像&效果
- 2.6 性能&集成
- 2.7 设备访问
- SEO
- Canvas
- 压缩图片
- 制作圆角矩形
- 全局属性
- 第二部分 CSS
- CSS原理
- 层叠上下文(stacking context)
- 外边距合并
- 块状格式化上下文(BFC)
- 盒模型
- important
- 样式继承
- 层叠
- 属性值处理流程
- 分辨率
- 视口
- CSS API
- grid(未完成)
- flex
- 选择器
- 3D
- Matrix
- AT规则
- line-height 和 vertical-align
- CSS技术
- 居中
- 响应式布局
- 兼容性
- 移动端适配方案
- CSS应用
- CSS Modules(未完成)
- 分层
- 面向对象CSS(未完成)
- 布局
- 三列布局
- 单列等宽,其他多列自适应均匀
- 多列等高
- 圣杯布局
- 双飞翼布局
- 瀑布流
- 1px问题
- 适配iPhoneX
- 横屏适配
- 图片模糊问题
- stylelint
- 第三部分 JavaScript
- JavaScript原理
- 内存空间
- 作用域
- 执行上下文栈
- 变量对象
- 作用域链
- this
- 类型转换
- 闭包(未完成)
- 原型、面向对象
- class和extend
- 继承
- new
- DOM
- Event Loop
- 垃圾回收机制
- 内存泄漏
- 数值存储
- 连等赋值
- 基本类型
- 堆栈溢出
- JavaScriptAPI
- document.referrer
- Promise(未完成)
- Object.create
- 遍历对象属性
- 宽度、高度
- performance
- 位运算
- tostring( ) 与 valueOf( )方法
- JavaScript技术
- 错误
- 异常处理
- 存储
- Cookie与Session
- ES6(未完成)
- Babel转码
- let和const命令
- 变量的解构赋值
- 字符串的扩展
- 正则的扩展
- 数值的扩展
- 数组的扩展
- 函数的扩展
- 对象的扩展
- Symbol
- Set 和 Map 数据结构
- proxy
- Reflect
- module
- AJAX
- ES5
- 严格模式
- JSON
- 数组方法
- 对象方法
- 函数方法
- 服务端推送(未完成)
- JavaScript应用
- 复杂判断
- 3D 全景图
- 重载
- 上传(未完成)
- 上传方式
- 文件格式
- 渲染大量数据
- 图片裁剪
- 斐波那契数列
- 编码
- 数组去重
- 浅拷贝、深拷贝
- instanceof
- 模拟 new
- 防抖
- 节流
- 数组扁平化
- sleep函数
- 模拟bind
- 柯里化
- 零碎知识点
- 第四部分 进阶
- 计算机原理
- 数据结构(未完成)
- 算法(未完成)
- 排序算法
- 冒泡排序
- 选择排序
- 插入排序
- 快速排序
- 搜索算法
- 动态规划
- 二叉树
- 浏览器
- 浏览器结构
- 浏览器工作原理
- HTML解析
- CSS解析
- 渲染树构建
- 布局(Layout)
- 渲染
- 浏览器输入 URL 后发生了什么
- 跨域
- 缓存机制
- reflow(回流)和repaint(重绘)
- 渲染层合并
- 编译(未完成)
- Babel
- 设计模式(未完成)
- 函数式编程(未完成)
- 正则表达式(未完成)
- 性能
- 性能分析
- 性能指标
- 首屏加载
- 优化
- 浏览器层面
- HTTP层面
- 代码层面
- 构建层面
- 移动端首屏优化
- 服务器层面
- bigpipe
- 构建工具
- Gulp
- webpack
- Webpack概念
- Webpack工具
- Webpack优化
- Webpack原理
- 实现loader
- 实现plugin
- tapable
- Webpack打包后代码
- rollup.js
- parcel
- 模块化
- ESM
- 安全
- XSS
- CSRF
- 点击劫持
- 中间人攻击
- 密码存储
- 测试(未完成)
- 单元测试
- E2E测试
- 框架测试
- 样式回归测试
- 异步测试
- 自动化测试
- PWA
- PWA官网
- web app manifest
- service worker
- app install banners
- 调试PWA
- PWA教程
- 框架
- MVVM原理
- Vue
- Vue 饿了么整理
- 样式
- 技巧
- Vue音乐播放器
- Vue源码
- Virtual Dom
- computed原理
- 数组绑定原理
- 双向绑定
- nextTick
- keep-alive
- 导航守卫
- 组件通信
- React
- Diff 算法
- Fiber 原理
- batchUpdate
- React 生命周期
- Redux
- 动画(未完成)
- 异常监控、收集(未完成)
- 数据采集
- Sentry
- 贝塞尔曲线
- 视频
- 服务端渲染
- 服务端渲染的利与弊
- Vue SSR
- React SSR
- 客户端
- 离线包
- 第五部分 网络
- 五层协议
- TCP
- UDP
- HTTP
- 方法
- 首部
- 状态码
- 持久连接
- TLS
- content-type
- Redirect
- CSP
- 请求流程
- HTTP/2 及 HTTP/3
- CDN
- DNS
- HTTPDNS
- 第六部分 服务端
- Linux
- Linux命令
- 权限
- XAMPP
- Node.js
- 安装
- Node模块化
- 设置环境变量
- Node的event loop
- 进程
- 全局对象
- 异步IO与事件驱动
- 文件系统
- Node错误处理
- koa
- koa-compose
- koa-router
- Nginx
- Nginx配置文件
- 代理服务
- 负载均衡
- 获取用户IP
- 解决跨域
- 适配PC与移动环境
- 简单的访问限制
- 页面内容修改
- 图片处理
- 合并请求
- PM2
- MongoDB
- MySQL
- 常用MySql命令
- 自动化(未完成)
- docker
- 创建CLI
- 持续集成
- 持续交付
- 持续部署
- Jenkins
- 部署与发布
- 远程登录服务器
- 增强服务器安全等级
- 搭建 Nodejs 生产环境
- 配置 Nginx 实现反向代理
- 管理域名解析
- 配置 PM2 一键部署
- 发布上线
- 部署HTTPS
- Node 应用
- 爬虫(未完成)
- 例子
- 反爬虫
- 中间件
- body-parser
- connect-redis
- cookie-parser
- cors
- csurf
- express-session
- helmet
- ioredis
- log4js(未完成)
- uuid
- errorhandler
- nodeclub源码
- app.js
- config.js
- 消息队列
- RPC
- 性能优化
- 第七部分 总结
- Web服务器
- 目录结构
- 依赖
- 功能
- 代码片段
- 整理
- 知识清单、博客
- 项目、组件、库
- Node代码
- 面试必考
- 91算法
- 第八部分 工作代码总结
- 样式代码
- 框架代码
- 组件代码
- 功能代码
- 通用代码