
[TOC]
# 范畴论
## 范畴
范畴就是使用箭头连接的物体。也就是说,彼此之间存在某种关系的概念、事物、对象等等,都构成"范畴"。随便什么东西,只要能找出它们之间的关系,就能定义一个"范畴"。
<br>
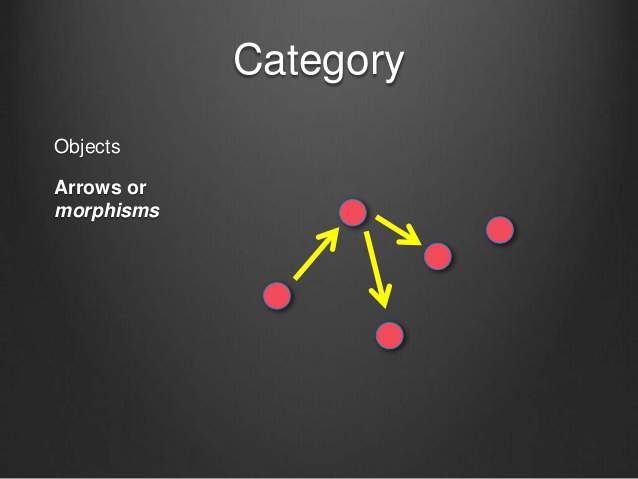
<br>
上图中,各个点范畴的成员,与它们之间的箭头,就构成一个范畴。
<br>
箭头表示范畴成员之间的关系,正式的名称叫做"态射"(morphism)。范畴论认为,同一个范畴的所有成员,就是不同状态的"变形"(transformation)。通过"态射",一个成员可以变形成另一个成员。
<br>
<br>
## 范畴与容器
我们可以把"范畴"想象成是一个容器,里面包含两样东西。
* 值(value)
* 值的变形关系,也就是函数。
<br>
下面我们使用代码,定义一个简单的范畴。
```
class Category {
constructor(val) {
this.val = val;
}
addOne(x) {
return x + 1;
}
}
```
上面代码中,Category是一个类,也是一个容器,里面包含一个值(this.val)和一种变形关系(addOne)。你可能已经看出来了,这里的范畴,就是所有彼此之间相差1的数字。
<br>
## 范畴论与函数式编程的关系
范畴论使用函数,表达范畴之间的关系。
<br>
伴随着范畴论的发展,就发展出一整套函数的运算方法。这套方法起初只用于数学运算,后来有人将它在计算机上实现了,就变成了今天的"函数式编程"。
<br>
本质上,函数式编程只是范畴论的运算方法,跟数理逻辑、微积分、行列式是同一类东西,都是数学方法,只是碰巧它能用来写程序。
<br>
<br>
# 函数式编程的特点
* 函数是”第一等公民”。所谓”第一等公民”(first class),指的是函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
* 只用”表达式",不用"语句"。
* 没有”副作用"。如果函数与外部可变状态进行交互,则它是有副作用的。如:
* 修改一个变量
* 直接修改数据结构
* 设置一个对象的成员
* 抛出一个异常或以一个错误终止
* 打印到终端或读取用户的输入
* 读取或写入一个文件
* 在屏幕上绘画
* 不修改状态。在函数式编程中变量仅仅代表某个表达式。这里所说的’变量’是不能被修改的。所有的变量只能被赋一次初值。
* 引用透明(函数运行只靠参数)
<br>
<br>
# 函数式编程的优点与缺点
优点
* 效降低系统的复杂度
* 可缓存性
```
import _ from 'lodash';
var sin = _.memorize(x =>Math.sin(x));
//第一次计算的时候会稍慢一点
var a = sin(1);
//第二次有了缓存,速度极快
var b = sin(1);
```
<br>
缺点
* 扩展性比较差
```
// 不纯的
var min = 18;
var checkage = age => age > min;
// 纯函数
var checkage = age => age > 18;
```
在不纯的版本中,checkage 不仅取决于 age还有外部依赖的变量 min。纯的 checkage 把关键数字 18 硬编码在函数内部,,柯里化优雅的函数式解决。
<br>
<br>
# 核心概念
## 纯函数(Purity)
对于相同的输入,永远会得到相同的输出,而且没有任何可观察的副作用,也不依赖外部环境的状态。
```
const greet = (name) => `hello, ${name}`
greet('world')
```
<br>
以下代码函数依赖外部状态,不是纯函数:
```
window.name = 'Brianne'
const greet = () => `Hi, ${window.name}`
greet() // "Hi, Brianne"
```
<br>
以下代码函数修改了外部状态,不是纯函数:
```
let greeting
const greet = (name) => {
greeting = `Hi, ${name}`
}
greet('Brianne')
greeting // "Hi, Brianne"
```
<br>
## 幂等性 (Idempotent)
幂等性是指执行无数次后还具有相同的效果,同一的参数运行一次函数应该与连续两次结果一致。幂等性在函数式编程中与纯度相关,但有不一致。
```
f(f(x)) = f(x)
```
<br>
```
Math.abs(Math.abs(10))
```
<br>
```
sort(sort(sort([2, 1])))
```
<br>
## 偏应用函数 (Partial Function)
传递给函数一部分参数来调用它,让它返回一个函数去处理剩下的参数。
<br>
```
// 创建偏函数,固定一些参数
const partical = (f, ...args) =>
// 返回一个带有剩余参数的函数
(...moreArgs) =>
// 调用原始函数
f(...args, ...moreArgs)
const add3 = (a, b, c) => a + b + c
// (...args) => add3(2, 3, ...args)
// (c) => 2 + 3 + c
const fivePlus = partical(add3, 2, 3)
fivePlus(4) // 9
```
<br>
也可以使用 Function.prototype.bind 实现偏函数。
```
const add1More = add3.bind(null, 2, 3)
```
<br>
偏函数应用通过对复杂的函数填充一部分数据来构成一个简单的函数。柯里化通过偏函数实现。
<br>
偏函数之所以“偏”,在就在于其只能处理那些能与至少一个case语句匹配的输入,而不能处理所有可能的输入。
<br>
## 柯里化 (Currying)
将一个多元函数转变为一元函数的过程。 每当函数被调用时,它仅仅接收一个参数并且返回带有一个参数的函数,直到传递完所有的参数。
```
var checkage = min => (age => age > min);
var checkage18 = checkage(18);
checkage18(20);
const sum = (a, b) => a + b
const curriedSum = (a) => (b) => a + b
curriedSum(3)(4) // 7
const add2 = curriedSum(2)
add2(10) // 12
```
<br>
优点
事实上柯里化是一种“预加载”函数的方法,通过传递较少的参数,得到一个已经记住了这些参数的新函数,某种意义上讲,这是一种对参数的“缓存”,是一种非常高效的编写函数的方法。
<br>
## 函数组合 (Function Composing)
接收多个函数作为参数,从右到左,一个函数的输入为另一个函数的输出。

```
const compose = function (f, g) {
return function (x) {
return f(g(x));
};
}
var first = arr => arr[0];
var reverse = arr => arr.reverse();
var last = compose(first, reverse);
console.log(last([1,2,3,4,5])) // 5
```
<br>
函数的合成还必须满足结合律。

```
compose(f, compose(g, h))
// 等同于
compose(compose(f, g), h)
// 等同于
compose(f, g, h)
```
<br>
## Point-Free
把一些对象自带的方法转化成纯函数,不要命名转瞬即逝的中间变量。
<br>
这个函数中,我们使用了 str 作为我们的中间变量,但这个中间变量除了让代码变得长了一点以外是毫无意义的。
<br>
```
const f = str => str.toUpperCase().split(' ');
```
<br>
使用point-free风格:
```
var toUpperCase = word => word.toUpperCase();
var split = x => (str => str.split(x));
var f = compose(split(' '), toUpperCase);
f("abcd efgh");
```
<br>
这种风格能够帮助我们减少不必要的命名,让代码保持简洁和通用。
<br>
## 高阶函数 (Higher-Order Function / HOF)
函数当参数,把传入的函数做一个封装,然后返回这个封装函数,达到更高程度的抽象。
```
// 命令式
var add = function(a,b){
return a + b;
};
function math(func,array){
return func(array[0],array[1]);
}
math(add,[1,2]); // 3
```
* 它是一等公民
* 它已一个函数作为参数
* 已一个函数作为返回结果
<br>
## 尾调用
### 什么是尾调用
指函数内部的最后一个动作是函数调用。该调用的返回值,直接返回给函数。
```
function f(x){
return g(x);
}
```
上面代码中,函数f的最后一步是调用函数g,这就叫尾调用。
<br>
以下三种情况,都不属于尾调用。
```
// 情况一
function f(x){
let y = g(x);
return y;
}
// 情况二
function f(x){
return g(x) + 1;
}
// 情况三
function f(x){
g(x);
}
```
上面代码中,情况一是调用函数g之后,还有赋值操作,所以不属于尾调用,即使语义完全一样。
情况二也属于调用后还有操作,即使写在一行内。
情况三等同于下面的代码。
```
function f(x){
g(x);
return undefined;
}
```
<br>
尾调用**不一定出现在函数尾部**,**只要是最后一步操作即可**。
```
function f(x) {
if (x > 0) {
return m(x)
}
return n(x);
}
```
上面代码中,函数m和n都属于尾调用,因为它们都是函数f的最后一步操作。
> 函数调用自身,称为递归。
如果尾调用自身,就称为尾递归。
递归需要保存大量的调用记录,很容易发生栈溢出错误,如果使用尾递归优化,将递归变为循环,那么只需要保存一个调用记录,这样就不会发生栈溢出错误了。
<br>
### 尾调用优化
尾调用之所以与其他调用不同,就在于它的特殊的调用位置。
<br>
我们知道,函数调用会在内存形成一个“调用记录”,又称“调用帧”(call frame),保存调用位置和内部变量等信息。如果在函数A的内部调用函数B,那么在A的调用帧上方,还会形成一个B的调用帧。等到B运行结束,将结果返回到A,B的调用帧才会消失。如果函数B内部还调用函数C,那就还有一个C的调用帧,以此类推。所有的调用帧,就形成一个“调用栈”(call stack)。
<br>
**尾调用由于是函数的最后一步操作,所以不需要保留外层函数的调用帧,因为调用位置、内部变量等信息都不会再用到了,只要直接用内层函数的调用帧,取代外层函数的调用帧就可以了。**
```
function f() {
let m = 1;
let n = 2;
return g(m + n);
}
f();
// 等同于
function f() {
return g(3);
}
f();
// 等同于
g(3);
```
<br>
上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除f(x)的调用帧,只保留g(3)的调用帧。
<br>
这就叫做“尾调用优化”(Tail call optimization),即只保留内层函数的调用帧。**如果所有函数都是尾调用,那么完全可以做到每次执行时,调用帧只有一项,这将大大节省内存**。这就是“尾调用优化”的意义。
<br>
注意,**只有不再用到外层函数的内部变量,内层函数的调用帧才会取代外层函数的调用帧**,否则就无法进行“尾调用优化”。
<br>
```
function addOne(a){
var one = 1;
function inner(b){
return b + one;
}
return inner(a);
}
```
<br>
上面的函数不会进行尾调用优化,因为内层函数inner用到了外层函数addOne的内部变量one。
<br>
### 传统递归
普通递归时,内存需要记录调用的堆栈所出的深度和位置信息。在最底层计算返回值,再根据记录的信息,跳回上一层级计算,然后再跳回更高一层,依次运行,直到最外层的调用函数。在cpu计算和内存会消耗很多,而且当深度过大时,会出现堆栈溢出。
```
function sum(n) {
if (n === 1) return 1;
return n + sum(n - 1);
}
// sum(5)
// (5 + sum(4))
// (5 + (4 + sum(3)))
// (5 + (4 + (3 + sum(2))))
// (5 + (4 + (3 + (2 + sum(1)))))
// (5 + (4 + (3 + (2 + 1))))
// (5 + (4 + (3 + 3)))
// (5 + (4 + 6))
// (5 + 10)
// 15
```
<br>
### 尾递归
整个计算过程是线性的,调用一次sum(x, total)后,会进入下一个栈,相关的数据信息和跟随进入,不再放在堆栈上保存。当计算完最后的值之后,直接返回到最上层的sum(5,0)。这能有效的防止堆栈溢出。
在ECMAScript 6,我们将迎来尾递归优化,通过尾递归优化,javascript代码在解释成机器码的时候,将会向while看齐,也就是说,同时拥有数学表达能力和while的效能。
```
function sum(x, total) {
if (x === 1) {
return x + total;
}
return sum(x - 1, x + total);
}
// sum(5, 0)
// sum(4, 5)
// sum(3, 9)
// sum(2, 12)
// sum(1, 14)
// 15
```
<br>
还有一个比较著名的例子,就是计算 Fibonacci 数列,也能充分说明尾递归优化的重要性。
<br>
非尾递归的 Fibonacci 数列实现如下。
```
function Fibonacci (n) {
if ( n <= 1 ) {return 1};
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
Fibonacci(10) // 89
Fibonacci(100) // 超时
Fibonacci(500) // 超时
```
<br>
尾递归优化过的 Fibonacci 数列实现如下。
```
function Fibonacci2 (n , ac1 = 1 , ac2 = 1) {
if( n <= 1 ) {return ac2};
return Fibonacci2 (n - 1, ac2, ac1 + ac2);
}
Fibonacci2(100) // 573147844013817200000
Fibonacci2(1000) // 7.0330367711422765e+208
Fibonacci2(10000) // Infinity
```
<br>
尾递归的判断标准是函数运行【最后一步】是否调用自身,而不是是否在函数的【最后一行】调用自身,最后一行调用其他函数并返回叫尾调用。
<br>
按道理尾递归调用调用栈永远都是更新当前的栈帧而已,这样就完全避免了爆栈的危险。但是现如今的浏览器并未完全支持。原因有二:
* 在引擎层面消除递归是一个隐式的行为,程序员意识不到。
* 堆栈信息丢失了 开发者难已调试
<br>
### 严格模式
ES6 的尾调用优化只在严格模式下开启,正常模式是无效的。
这是因为在正常模式下,函数内部有两个变量,可以跟踪函数的调用栈。
* `func.arguments`:返回调用时函数的参数。
* `func.caller`:返回调用当前函数的那个函数。
<br>
尾调用优化发生时,函数的调用栈会改写,因此上面两个变量就会失真。严格模式禁用这两个变量,所以尾调用模式仅在严格模式下生效。
~~~javascript
function restricted() {
'use strict';
restricted.caller; // 报错
restricted.arguments; // 报错
}
restricted();
~~~
<br>
### 尾递归优化的实现
尾递归优化只在严格模式下生效,那么正常模式下,或者那些不支持该功能的环境中,有没有办法也使用尾递归优化呢?回答是可以的,就是自己实现尾递归优化。
<br>
它的原理非常简单。尾递归之所以需要优化,原因是调用栈太多,造成溢出,那么只要减少调用栈,就不会溢出。怎么做可以减少调用栈呢?就是采用“循环”换掉“递归”。
<br>
下面是一个正常的递归函数。
~~~javascript
function sum(x, y) {
if (y > 0) {
return sum(x + 1, y - 1);
} else {
return x;
}
}
sum(1, 100000)
// Uncaught RangeError: Maximum call stack size exceeded(…)
~~~
<br>
上面代码中,`sum`是一个递归函数,参数`x`是需要累加的值,参数`y`控制递归次数。一旦指定`sum`递归 100000 次,就会报错,提示超出调用栈的最大次数。
<br>
蹦床函数(trampoline)可以将递归执行转为循环执行。
~~~javascript
function trampoline(f) {
while (f && f instanceof Function) {
f = f();
}
return f;
}
~~~
<br>
上面就是蹦床函数的一个实现,它接受一个函数`f`作为参数。只要`f`执行后返回一个函数,就继续执行。注意,这里是返回一个函数,然后执行该函数,而不是函数里面调用函数,这样就避免了递归执行,从而就消除了调用栈过大的问题。
<br>
然后,要做的就是将原来的递归函数,改写为每一步返回另一个函数。
~~~javascript
function sum(x, y) {
if (y > 0) {
return sum.bind(null, x + 1, y - 1);
} else {
return x;
}
}
~~~
<br>
上面代码中,`sum`函数的每次执行,都会返回自身的另一个版本。
<br>
现在,使用蹦床函数执行`sum`,就不会发生调用栈溢出。
~~~javascript
trampoline(sum(1, 100000))
// 100001
~~~
<br>
蹦床函数并不是真正的尾递归优化,下面的实现才是。
~~~javascript
function tco(f) {
var value;
var active = false;
var accumulated = [];
return function accumulator() {
accumulated.push(arguments);
if (!active) {
active = true;
while (accumulated.length) {
value = f.apply(this, accumulated.shift());
}
active = false;
return value;
}
};
}
var sum = tco(function(x, y) {
if (y > 0) {
return sum(x + 1, y - 1)
}
else {
return x
}
});
sum(1, 100000)
// 100001
~~~
<br>
上面代码中,`tco`函数是尾递归优化的实现,它的奥妙就在于状态变量`active`。默认情况下,这个变量是不激活的。一旦进入尾递归优化的过程,这个变量就激活了。然后,每一轮递归`sum`返回的都是`undefined`,所以就避免了递归执行;而`accumulated`数组存放每一轮`sum`执行的参数,总是有值的,这就保证了`accumulator`函数内部的`while`循环总是会执行。这样就很巧妙地将“递归”改成了“循环”,而后一轮的参数会取代前一轮的参数,保证了调用栈只有一层。
<br>
## 函子
函数不仅可以用于同一个范畴之中值的转换,还可以用于将一个范畴转成另一个范畴。这就涉及到了函子(Functor)。
<br>
函子是函数式编程里面最重要的数据类型,也是基本的运算单位和功能单位。
<br>
它首先是一种范畴,也就是说,是一个容器,包含了值和变形关系。比较特殊的是,它的变形关系可以依次作用于每一个值,将当前容器变形成另一个容器。
<br>
`Functor `是一个对于函数调用的抽象,我们赋予容器自己去调用函数的能力。把东西装进一个容器,只留出一个接口 `map `给容器外的函数,`map `一个函数时,我们让容器自己来运行这个函数,这样容器就可以自由地选择何时何地如何操作这个函数,以致于拥有惰性求值、错误处理、异步调用等等非常的特性。
<br>
任何具有map方法的数据结构,都可以当作函子的实现。
```
class Functor {
constructor(val) {
this.val = val;
}
map(f) {
return new Functor(f(this.val));
}
}
```
<br>
上面代码中,`Functor`是一个函子,它的`map`方法接受函数f作为参数,然后返回一个新的函子,里面包含的值是被f处理过的(`f(this.val)`)。
<br>
一般约定,函子的标志就是容器具有map方法。该方法将容器里面的每一个值,映射到另一个容器。
<br>
下面是一些用法的示例。
```
(new Functor(2)).map(function (two) {
return two + 2;
});
// Functor(4)
(new Functor('flamethrowers')).map(function(s) {
return s.toUpperCase();
});
// Functor('FLAMETHROWERS')
(new Functor('bombs')).map(_.concat(' away')).map(_.prop('length'));
// Functor(10)
```
<br>
上面的例子说明,函数式编程里面的运算,都是通过函子完成,即运算不直接针对值,而是针对这个值的容器----函子。函子本身具有对外接口(map方法),各种函数就是运算符,通过接口接入容器,引发容器里面的值的变形。
<br>
## of 方法
上面生成新的函子的时候,用了new命令。这实在太不像函数式编程了,因为new命令是面向对象编程的标志。函数式编程一般约定,函子有一个of方法,用来生成新的容器。
```
Functor.of = function(val) {
return new Functor(val);
};
```
<br>
## maybe函子
函子接受各种函数,处理容器内部的值。这里就有一个问题,容器内部的值可能是一个空值(比如null),而外部函数未必有处理空值的机制,如果传入空值,很可能就会出错。
<br>
Maybe 函子就是为了解决这一类问题而设计的。简单说,它的map方法里面设置了空值检查。
```
class Maybe {
constructor(val) {
this.val = val
}
static of(val) {
// 生成新的容器
return new Maybe(val)
}
isNothing() {
return (this.val === null || this.val === undefined)
}
map(f) {
return this.isNothing() ? Maybe.of(null) : Maybe.of(f(this.val))
}
}
```
<br>
有了 Maybe 函子,处理空值就不会出错了。
```
Maybe.of(null).map(function (s) {
return s.toUpperCase();
});
// Maybe(null)
```
<br>
## Either 函子
条件运算if...else是最常见的运算之一,函数式编程里面,使用 Either 函子表达。
<br>
Either 函子内部有两个值:左值(Left)和右值(Right)。右值是正常情况下使用的值,左值是右值不存在时使用的默认值。
```
class Either {
constructor(left, right) {
this.left = left
this.right = right
}
static of(left, right) {
return new Either(left, right)
}
map(f) {
return this.right ?
Either.of(this.left, f(this.right)) :
Either.of(f(this.left), this.right)
}
}
```
<br>
Either 函子的常见用途是提供默认值。下面是一个例子。
```
Either
.of({address: 'xxx'}, currentUser.address)
.map(updateField);
```
上面代码中,如果用户没有提供地址,Either 函子就会使用左值的默认地址。
<br>
Either 函子的另一个用途是代替try...catch,使用左值表示错误。
```
class Left {
constructor(val) {
this.val = val
}
static of (x) {
return new Left(x)
}
map (f) {
return this
}
}
class Right {
constructor(val) {
this.val = val
}
static of (x) {
return new Left(x)
}
map (f) {
return Right.of(f(this.val))
}
}
var getAge = user => user.age ? Right.of(user.age) : Left.of('ERROR!');
console.log(getAge({name: 'stark', age: '21'}).map(age => 'Age is ' + age)) // Left { val: '21' }
console.log(getAge({name: 'stark'}).map(age => 'Age is ' + age)) // Left('ERROR!')
```
Left 可以让调用链中任意一环的错误立刻返回到调用链的尾部,这给我们错误处理带来了很大的方便,再也不用一层又一层的 try/catch。
<br>
## AP 函子
函子里面包含的值,完全可能是函数。我们可以想象这样一种情况,一个函子的值是数值,另一个函子的值是函数。
```
class Ap {
constructor(val) {
this.val = val
}
static of(val) {
// 生成新的容器
return new Ap(val)
}
ap(F) {
return Ap.of(this.val(F.val));
}
}
function addTwo(x) {
return x + 2;
}
console.log(Ap.of(addTwo).ap(Ap.of(2)))
```
<br>
## Monad函子
Monad就是一种设计模式,表示将一个运算过程,通过函数拆解成互相连接的多个步骤。你只要提供下一步运算所需的函数,整个运算就会自动进行下去。
<br>
Promise 就是一种 Monad。Monad 让我们避开了嵌套地狱,可以轻松地进行深度嵌套的函数式编程,比如IO和其它异步任务。
<br>
Monad 函子的作用是,总是返回一个单层的函子。它有一个flatMap方法,与map方法作用相同,唯一的区别是如果生成了一个嵌套函子,它会取出后者内部的值,保证返回的永远是一个单层的容器,不会出现嵌套的情况。
<br>
```
class Monad extends Functor {
join() {
return this.val;
}
flatMap(f) {
return this.map(f).join();
}
}
```
上面代码中,如果函数f返回的是一个函子,那么this.map(f)就会生成一个嵌套的函子。所以,join方法保证了flatMap方法总是返回一个单层的函子。这意味着嵌套的函子会被铺平(flatten)。
<br>
## IO 操作
Monad 函子的重要应用,就是实现 I/O (输入输出)操作。
<br>
I/O 是不纯的操作,普通的函数式编程没法做,这时就需要把 IO 操作写成Monad函子,通过它来完成。
<br>
```
var fs = require('fs');
var path = require('path')
var _ = require('lodash');
var compose = _.flowRight;
//基础函子
class Functor {
constructor(val) {
this.val = val;
}
}
//Monad 函子
class Monad extends Functor {
join() {
return this.val;
}
flatMap(f) {
//1.f 接受一个函数返回的IO函子
//2.this.val 等于上一步的脏操作
//3.this.map(f) compose(f, this.val) 函数组合 需要手动执行
//4.返回这个组合函数并执行 注意先后的顺序
return this.map(f).join();
}
}
//IO函子用来包裹脏操作
class IO extends Monad {
//val是最初的脏操作
static of(val) {
return new IO(val);
}
map(f) {
return IO.of(compose(f, this.val))
}
}
var readFile = function(filename) {
return new IO(function() {
return fs.readFileSync(filename, 'utf-8');
});
};
var print = function(x) {
return new IO(function() {
console.log(x);
return x;
});
}
```
上面代码中,读取文件和打印本身都是不纯的操作,但是readFile和print却是纯函数,因为它们总是返回 IO 函子。
<br>
如果 IO 函子是一个Monad,具有flatMap方法,那么我们就可以像下面这样调用这两个函数。
```
readFile('./user.txt')
.flatMap(print)
```
<br>
这就是神奇的地方,上面的代码完成了不纯的操作,但是因为flatMap返回的还是一个 IO 函子,所以这个表达式是纯的。我们通过一个纯的表达式,完成带有副作用的操作,这就是 Monad 的作用。
<br>
由于返回还是 IO 函子,所以可以实现链式操作。因此,在大多数库里面,flatMap方法被改名成chain。
```
var tail = function(x) {
return new IO(function() {
return x[x.length - 1];
});
}
readFile('./user.txt')
.flatMap(tail)
.flatMap(print)
// 等同于
readFile('./user.txt')
.chain(tail)
.chain(print)
```
上面代码读取了文件user.txt,然后选取最后一行输出。
<br>
<br>
# 流行的几大函数式编程库
* RxJS
* cycleJS
* lodashJS、lazy(惰性求值)
* underscoreJS
* ramdajs
<br>
# 实际应用场景
* 易调试、热部署、并发
* 单元测试
<br>
<br>
# 参考资料
[函数式编程入门教程](http://www.ruanyifeng.com/blog/2017/02/fp-tutorial.html)
[函数式编程术语](https://github.com/shfshanyue/fp-jargon-zh#monad)
[函数式编程指南](https://legacy.gitbook.com/book/llh911001/mostly-adequate-guide-chinese)
[ES6入门指南 - 尾调用优化](http://es6.ruanyifeng.com/#docs/function#尾调用优化)
[Pointfree Javascript | Lucas Reis' Blog](https://lucasmreis.github.io/blog/pointfree-javascript/)
- 第一部分 HTML
- meta
- meta标签
- HTML5
- 2.1 语义
- 2.2 通信
- 2.3 离线&存储
- 2.4 多媒体
- 2.5 3D,图像&效果
- 2.6 性能&集成
- 2.7 设备访问
- SEO
- Canvas
- 压缩图片
- 制作圆角矩形
- 全局属性
- 第二部分 CSS
- CSS原理
- 层叠上下文(stacking context)
- 外边距合并
- 块状格式化上下文(BFC)
- 盒模型
- important
- 样式继承
- 层叠
- 属性值处理流程
- 分辨率
- 视口
- CSS API
- grid(未完成)
- flex
- 选择器
- 3D
- Matrix
- AT规则
- line-height 和 vertical-align
- CSS技术
- 居中
- 响应式布局
- 兼容性
- 移动端适配方案
- CSS应用
- CSS Modules(未完成)
- 分层
- 面向对象CSS(未完成)
- 布局
- 三列布局
- 单列等宽,其他多列自适应均匀
- 多列等高
- 圣杯布局
- 双飞翼布局
- 瀑布流
- 1px问题
- 适配iPhoneX
- 横屏适配
- 图片模糊问题
- stylelint
- 第三部分 JavaScript
- JavaScript原理
- 内存空间
- 作用域
- 执行上下文栈
- 变量对象
- 作用域链
- this
- 类型转换
- 闭包(未完成)
- 原型、面向对象
- class和extend
- 继承
- new
- DOM
- Event Loop
- 垃圾回收机制
- 内存泄漏
- 数值存储
- 连等赋值
- 基本类型
- 堆栈溢出
- JavaScriptAPI
- document.referrer
- Promise(未完成)
- Object.create
- 遍历对象属性
- 宽度、高度
- performance
- 位运算
- tostring( ) 与 valueOf( )方法
- JavaScript技术
- 错误
- 异常处理
- 存储
- Cookie与Session
- ES6(未完成)
- Babel转码
- let和const命令
- 变量的解构赋值
- 字符串的扩展
- 正则的扩展
- 数值的扩展
- 数组的扩展
- 函数的扩展
- 对象的扩展
- Symbol
- Set 和 Map 数据结构
- proxy
- Reflect
- module
- AJAX
- ES5
- 严格模式
- JSON
- 数组方法
- 对象方法
- 函数方法
- 服务端推送(未完成)
- JavaScript应用
- 复杂判断
- 3D 全景图
- 重载
- 上传(未完成)
- 上传方式
- 文件格式
- 渲染大量数据
- 图片裁剪
- 斐波那契数列
- 编码
- 数组去重
- 浅拷贝、深拷贝
- instanceof
- 模拟 new
- 防抖
- 节流
- 数组扁平化
- sleep函数
- 模拟bind
- 柯里化
- 零碎知识点
- 第四部分 进阶
- 计算机原理
- 数据结构(未完成)
- 算法(未完成)
- 排序算法
- 冒泡排序
- 选择排序
- 插入排序
- 快速排序
- 搜索算法
- 动态规划
- 二叉树
- 浏览器
- 浏览器结构
- 浏览器工作原理
- HTML解析
- CSS解析
- 渲染树构建
- 布局(Layout)
- 渲染
- 浏览器输入 URL 后发生了什么
- 跨域
- 缓存机制
- reflow(回流)和repaint(重绘)
- 渲染层合并
- 编译(未完成)
- Babel
- 设计模式(未完成)
- 函数式编程(未完成)
- 正则表达式(未完成)
- 性能
- 性能分析
- 性能指标
- 首屏加载
- 优化
- 浏览器层面
- HTTP层面
- 代码层面
- 构建层面
- 移动端首屏优化
- 服务器层面
- bigpipe
- 构建工具
- Gulp
- webpack
- Webpack概念
- Webpack工具
- Webpack优化
- Webpack原理
- 实现loader
- 实现plugin
- tapable
- Webpack打包后代码
- rollup.js
- parcel
- 模块化
- ESM
- 安全
- XSS
- CSRF
- 点击劫持
- 中间人攻击
- 密码存储
- 测试(未完成)
- 单元测试
- E2E测试
- 框架测试
- 样式回归测试
- 异步测试
- 自动化测试
- PWA
- PWA官网
- web app manifest
- service worker
- app install banners
- 调试PWA
- PWA教程
- 框架
- MVVM原理
- Vue
- Vue 饿了么整理
- 样式
- 技巧
- Vue音乐播放器
- Vue源码
- Virtual Dom
- computed原理
- 数组绑定原理
- 双向绑定
- nextTick
- keep-alive
- 导航守卫
- 组件通信
- React
- Diff 算法
- Fiber 原理
- batchUpdate
- React 生命周期
- Redux
- 动画(未完成)
- 异常监控、收集(未完成)
- 数据采集
- Sentry
- 贝塞尔曲线
- 视频
- 服务端渲染
- 服务端渲染的利与弊
- Vue SSR
- React SSR
- 客户端
- 离线包
- 第五部分 网络
- 五层协议
- TCP
- UDP
- HTTP
- 方法
- 首部
- 状态码
- 持久连接
- TLS
- content-type
- Redirect
- CSP
- 请求流程
- HTTP/2 及 HTTP/3
- CDN
- DNS
- HTTPDNS
- 第六部分 服务端
- Linux
- Linux命令
- 权限
- XAMPP
- Node.js
- 安装
- Node模块化
- 设置环境变量
- Node的event loop
- 进程
- 全局对象
- 异步IO与事件驱动
- 文件系统
- Node错误处理
- koa
- koa-compose
- koa-router
- Nginx
- Nginx配置文件
- 代理服务
- 负载均衡
- 获取用户IP
- 解决跨域
- 适配PC与移动环境
- 简单的访问限制
- 页面内容修改
- 图片处理
- 合并请求
- PM2
- MongoDB
- MySQL
- 常用MySql命令
- 自动化(未完成)
- docker
- 创建CLI
- 持续集成
- 持续交付
- 持续部署
- Jenkins
- 部署与发布
- 远程登录服务器
- 增强服务器安全等级
- 搭建 Nodejs 生产环境
- 配置 Nginx 实现反向代理
- 管理域名解析
- 配置 PM2 一键部署
- 发布上线
- 部署HTTPS
- Node 应用
- 爬虫(未完成)
- 例子
- 反爬虫
- 中间件
- body-parser
- connect-redis
- cookie-parser
- cors
- csurf
- express-session
- helmet
- ioredis
- log4js(未完成)
- uuid
- errorhandler
- nodeclub源码
- app.js
- config.js
- 消息队列
- RPC
- 性能优化
- 第七部分 总结
- Web服务器
- 目录结构
- 依赖
- 功能
- 代码片段
- 整理
- 知识清单、博客
- 项目、组件、库
- Node代码
- 面试必考
- 91算法
- 第八部分 工作代码总结
- 样式代码
- 框架代码
- 组件代码
- 功能代码
- 通用代码