
在数据文件内部(堆表和索引,以及空闲空间映射和可见性映射),它被分成固定长度的页(或块),默认为8192字节(8 KB)。 每个文件中的那些页从 0 开始按顺序编号,这样的编号称为块编号。 如果文件已被填满,PostgreSQL 会在文件末尾添加一个新的空页以增加文件大小。
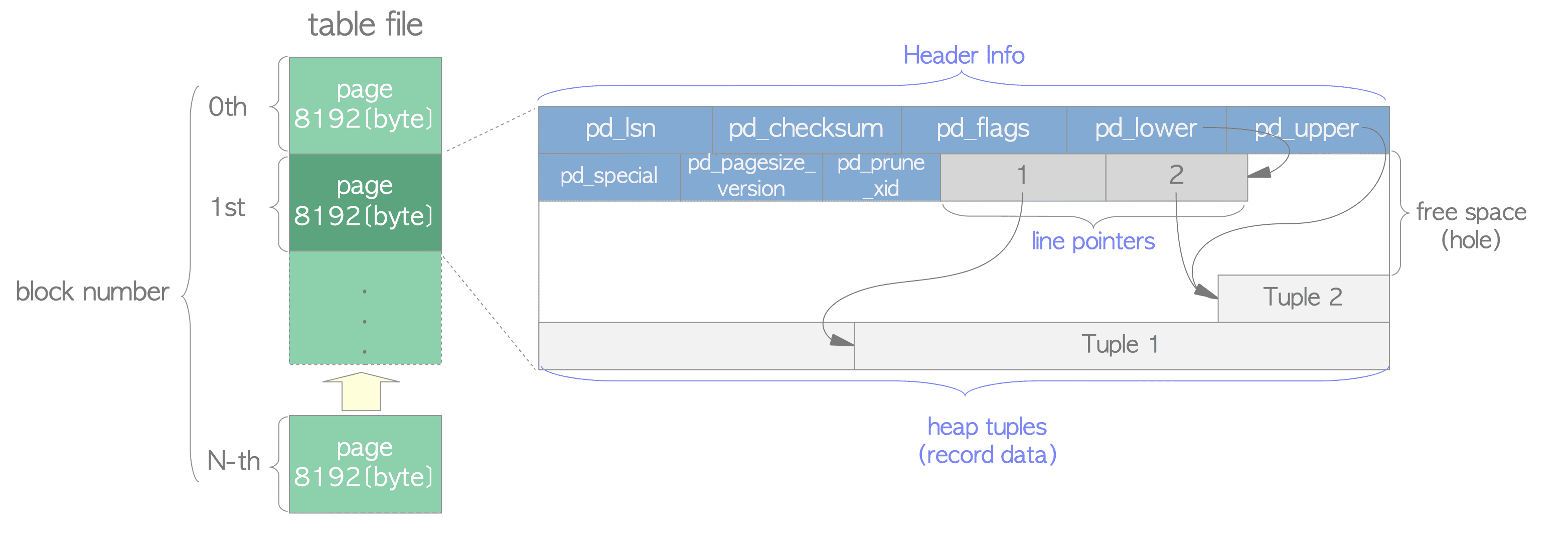
表中的页面包含三种数据:
* heap tuples: 行数据
* line pointers: 行指针,指向对应的tuple,offffset number从1开始
* header data:
* pd_lsn :保存此page的最新的WAL记录的lsn,用于数据恢复的
* pd_lower :指向最新的line pointer
* pd_upper: 指向最新的tuple
* pd_checksum:此变量存储此页面的校验和值。
* pd_special:此变量用于索引。 在表格内的页面中,它指向页面的末尾。 (在索引内页中,它指向特殊空间的开始,即只由索引保存的数据区,根据B-tree、GiST、GiN等索引类型包含特定数据。)
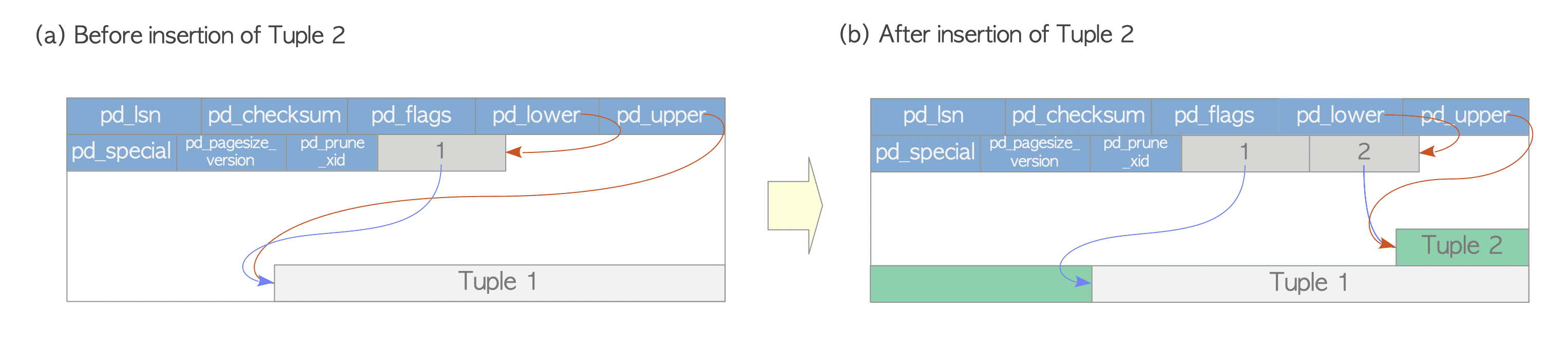
**写操作**
假设一个表由一页组成,其中只包含一个堆元组。 本页的pd_lower指向第一行指针,行指针和pd_upper都指向第一个堆元组。 见图 (a)。
当插入第二个元组时,它被放置在第一个元组之后。 第二行指针被推到第一行指针上,它指向第二个元组。 pd_lower 更改为指向第二行指针,pd_upper 更改为指向第二个堆元组。 见图 (b)。 此页中的其他头数据(例如,pd_lsn、pg_checksum、pg_flag)也被重写为适当的值
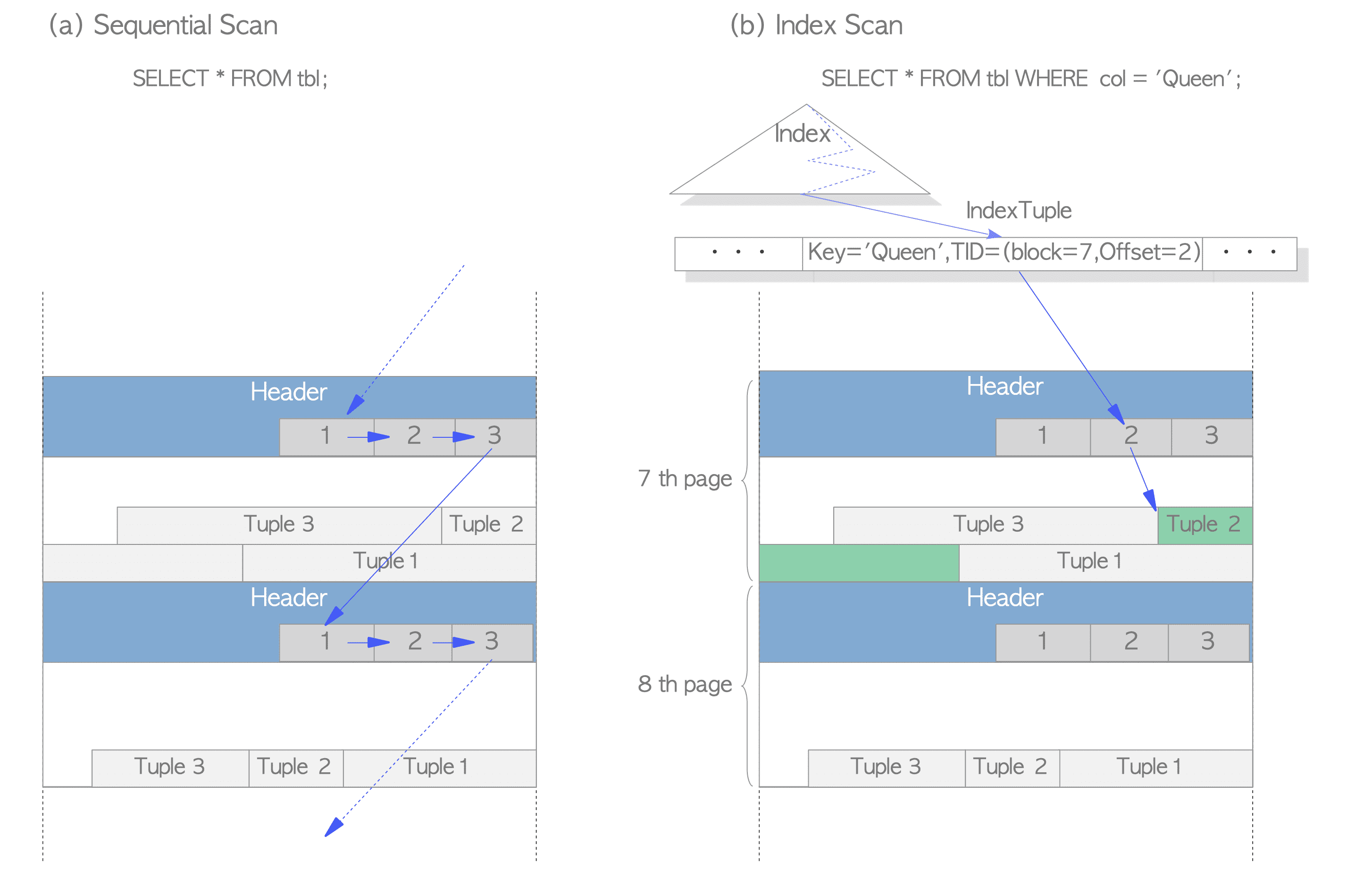
**读操作**
* sequential scan:遍历所有的pages的line pointers获取所有的tuples;
* index scan:通过索引获取tids,然后再根据tids获取tuples;
* index only scan:一般来说只扫描索引就能获取需要的字段,不需要回表读,需要VM配合使用;
* bitmap index scan:当index scan命中大量的rows时,将会构造一个page的bitmap(一个bit对应一个 page),然后在recheck每个page找到符合条件的rows,这样可以避免重复扫描page;
- PHP
- PHP基础
- PHP介绍
- 如何理解PHP是弱类型语言
- 超全局变量
- $_SERVER详解
- 字符串处理函数
- 常用数组函数
- 文件处理函数
- 常用时间函数
- 日历函数
- 常用url处理函数
- 易混淆函数区别(面试题常见)
- 时间戳
- PHP进阶
- PSR规范
- RESTFUL规范
- 面向对象
- 三大基本特征和五大基本原则
- 访问权限
- static关键字
- static关键字
- 静态变量与普通变量
- 静态方法与普通方法
- const关键字
- final关键字
- abstract关键字
- self、$this、parent::关键字
- 接口(interface)
- trait关键字
- instanceof关键字
- 魔术方法
- 构造函数和析构函数
- 私有属性的设置获取
- __toString()方法
- __clone()方法
- __call()方法
- 类的自动加载
- 设计模式详解
- 关于设计模式的一些建议
- 工厂模式
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
- 区别和适用范围
- 策略模式
- 单例模式
- HTTP
- 定义
- 特点
- 工作过程
- request
- response
- HTTP状态码
- URL
- GET和POST的区别
- HTTPS
- session与cookie
- 排序算法
- 冒泡排序算法
- 二分查找算法
- 直接插入排序算法
- 希尔排序算法
- 选择排序算法
- 快速排序算法
- 循环算法
- 递归与尾递归
- 迭代
- 日期相关的类
- DateTimeInterface接口
- DateTime类
- DateTimeImmutable类
- DateInterval类
- DateTimeZone类
- DatePeriod类
- format参数格式
- DateInterval的format格式化参数
- 预定义接口
- ArrayAccess(数组式访问)接口
- Serializable (序列化)接口
- Traversable(遍历)接口
- Closure类
- Iterator(迭代器)接口
- IteratorAggregate(聚合迭代器) 接口
- Generator (生成器)接口
- composer
- composer安装与使用
- python
- python3执行tarfile解压文件报错:tarfile.ReadError:file could not be opened successfully
- golang
- 单元测试
- 单元测试框架
- Golang内置testing包
- GoConvey库
- testify库
- 打桩与mock
- GoMock框架
- Gomonkey框架
- HTTP Mock
- httpMock
- mux库/httptest
- 数据库
- MYSQL
- SQL语言的分类
- 事务(重点)
- 索引
- 存储过程
- 触发器
- 视图
- 导入导出数据库
- 优化mysql数据库的方法
- MyISAM与InnoDB区别
- 外连接、内连接的区别
- 物理文件结构
- PostgreSQL
- 编译安装
- pgsql常用命令
- pgsql应用目录(bin目录)文件结构解析
- pg_ctl
- initdb
- psql
- clusterdb
- cluster命令
- createdb
- dropdb
- createuser
- dropuser
- pg_config
- pg_controldata
- pg_checksums
- pgbench
- pg_basebackup
- pg_dump
- pg_dumpall
- pg_isready
- pg_receivewal
- pg_recvlogical
- pg_resetwal
- pg_restore
- pg_rewind
- pg_test_fsync
- pg_test_timing
- pg_upgrade
- pg_verifybackup
- pg_archivecleanup
- pg_waldump
- postgres
- reindexdb
- vacuumdb
- ecpg
- pgsql数据目录文件结构解析
- pgsql数据目录文件结构解析
- postgresql.conf解析
- pgsql系统配置参数说明
- pgsql索引类型
- 四种索引类型解析
- 索引之ctid解析
- 索引相关操作
- pgsql函数解析
- pgsql系统函数解析
- pgsql窗口函数解析
- pgsql聚合函数解析
- pgsql系统表解析
- pg_stat_all_indexes
- pg_stat_all_tables
- pg_statio_all_indexes
- pg_statio_all_tables
- pg_stat_database
- pg_stat_statements
- pg_extension
- pg_available_extensions
- pg_available_extension_versions
- pgsql基本原理
- 进程和内存结构
- 存储结构
- 数据文件的内部结构
- 垃圾回收机制VACUUM
- 事务日志WAL
- 并发控制
- 介绍
- 事务ID-txid
- 元组结构-Tuple Structure
- 事务状态记录-Commit Log (clog)
- 事务快照-Transaction Snapshot
- 事务快照实例
- 事务隔离
- 事务隔离级别
- 读已提交-Read committed
- 可重复读-Repeatable read
- 可序列化-Serializable
- 读未提交-Read uncommitted
- 锁机制
- 扩展机制解析
- 扩展的定义
- 扩展的安装方式
- 自定义创建扩展
- 扩展的管理
- 扩展使用实例
- 在pgsql中使用last、first聚合函数
- pgsql模糊查询不走索引的解决方案
- pgsql的pg_trgm扩展解析与验证
- 高可用
- LNMP
- LNMP环境搭建
- 一键安装包
- 搭建方法
- 配置文件目录
- 服务器管理系统
- 宝塔(Linux)
- 安装与使用
- 开放API
- 自定义apache日志
- 一键安装包LNMP1.5
- LNMP1.5:添加、删除站点
- LNMP1.5:php多版本切换
- LNMP1.5 部署 thinkphp项目
- Operation not permitted解决方法
- Nginx
- Nginx的产生
- 正向代理和反向代理
- 负载均衡
- Linux常用命令
- 目录与文件相关命令
- 目录操作命令
- 文件编辑命令
- 文件查看命令
- 文件查找命令
- 文件权限命令
- 文件上传下载命令
- 用户和群组相关命令
- 用户与用户组的关系
- 用户相关的系统配置文件
- 用户相关命令
- 用户组相关命令
- 压缩与解压相关命令
- .zip格式
- .tar.gz格式
- .gz格式
- .bz2格式
- 查看系统版本
- cpuinfo详解
- meminfo详解
- getconf获取系统信息
- 磁盘空间相关命令
- 查看系统负载情况
- 系统环境变量
- 网络相关命令
- ip命令详解
- ip命令格式详解
- ip address命令详解
- ip link命令详解
- ip rule命令详解
- ip route命令详解
- nslookup命令详解
- traceroute命令详解
- netstat命令详解
- route命令详解
- tcpdump命令详解
- 系统进程相关命令
- ps命令详解
- pstree命令详解
- kill命令详解
- 守护进程-supervisord
- 性能监控相关命令
- top命令详解
- iostat命令详解
- pidstat命令详解
- iotop命令详解
- mpstat命令详解
- vmstat命令详解
- ifstat命令详解
- sar命令详解
- iftop命令详解
- 定时任务相关命令
- ssh登录远程主机
- ssh口令登录
- ssh公钥登录
- ssh带密码登录
- ssh端口映射
- ssh配置文件
- ssh安全设置
- 历史纪录
- history命令详解
- linux开启操作日志记录
- 拓展
- git
- git初始化本地仓库-https
- git初始化仓库-ssh
- git-查看和设置config配置
- docker
- 概念
- docker原理
- docker镜像原理
- docker Overlay2 文件系统原理
- docker日志原理
- docker日志驱动
- docker容器日志管理
- 原理论证
- 验证容器的启动是作为Docker Daemon的子进程
- 验证syslog类型日志驱动
- 验证journald类型日志驱动
- 验证local类型日志驱动
- 修改容器的hostname
- 修改容器的hosts
- 验证联合挂载技术
- 验证启动多个容器对于磁盘的占用情况
- 验证写时复制原理
- 验证docker内容寻址原理
- docker存储目录
- /var/lib/docker目录
- image目录
- overlay2目录
- 数据卷
- 具名挂载和匿名挂载
- 数据卷容器
- Dockerfile详解
- dockerfile指令详解
- 实例:构造centos
- 实例:CMD和ENTRYPOINT的区别
- docker网络详解
- docker-compose
- 缓存
- redis
- redis的数据类型和应用场景
- redis持久化
- RDB持久化
- AOF持久化
- redis缓存穿透、缓存击穿、缓存雪崩
- 常见网络攻击类型
- CSRF攻击
- XSS攻击
- SQL注入
- Cookie攻击
- 历史项目经验
- 图片上传项目实例
- 原生php上传方法实例
- base64图片流
- tp5的上传方法封装实例
- 多级关系的递归查询
- 数组转树结构
- thinkphp5.1+ajax实现导出Excel
- JS 删除数组的某一项
- 判断是否为索引数组
- ip操作