Kubernetes是一个用于容器编排的开源工具,是应用程序级别的虚拟化技术的必然结果。容器化技术运行单个内核上有多个独立的用户空间实例,这些实例就是容器。容器提供了将应用程序的代码、运行时、系统工具、系统库和配置打包到一个实例中的标准方法,并且容器是共享一个内核的。由于容器技术的兴起,导致大量的容器应用出现,所以出现了一些用来支持应用程序容器化部署和组织的容器编排技术,其中Kubernetes现在已经成为了容器编排领域事实上的一个标准。
**欢迎关注技术手册每日必更新,带你一步步成长为架构师......**
###

###
Kubernetes是一个由Google团队发起的开源项目,旨在管理跨多个主机的容器,用于自动部署、扩展和管理容器化的应用程序。Kubernetes的主要实现语言为Go语言。该项目的理论基础源于Google内部的Borg项目,这使得Kubernetes在理论上比其他开源项目更加先进。Borg系统一直被认为是Google公司内部最强大的“私密武器”,因此Kubernetes的理论基础也非常强大。
###
# 架构
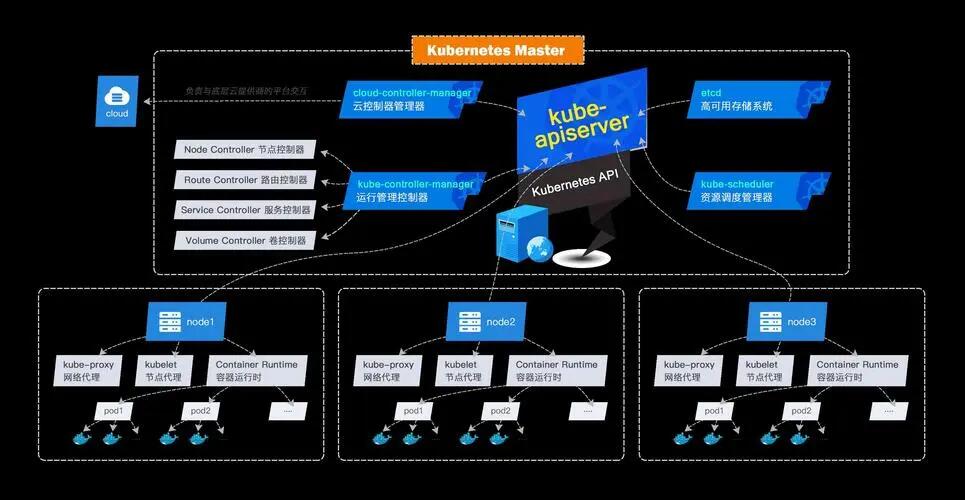
Kubernetes 项目依托着 Borg 项目的理论优势,确定了一个如下图所示的全局架构图:
###
Kubernetes由Master节点和Node节点两种角色组成。Master节点是控制节点,负责管理整个Kubernetes集群的状态和配置信息。Node节点是工作节点,负责运行容器应用。可以将Master节点看作老板,负责管理和控制整个集群的运行状态;将Node节点看作员工,负责实际运行容器应用。这种角色分工使得Kubernetes可以高效地管理和运行容器化应用程序。
###
Kubernetes的Master节点由三个独立的组件组成,它们分别是kube-apiserver、kube-scheduler和kube-controller-manager。
> kube-apiserver是整个集群通信的核心组件,负责接收来自用户和管理员的请求,并将请求转发给其他组件进行处理。
>
> kube-scheduler负责容器的调度,将容器应用程序调度到合适的节点上运行**。
>
> kube-controller-manager则负责维护整个集群的状态,包括容器的运行状态、节点的状态等**。
整个集群的数据都是通过kube-apiserver保存到etcd数据库中的,其他所有组件之间的通信也都是通过kube-apiserver和etcd数据库进行通信,而不会直接与etcd进行通信。这种架构使得Kubernetes具有高可用性和可扩展性,能够满足各种规模的容器化应用程序的需求。
###
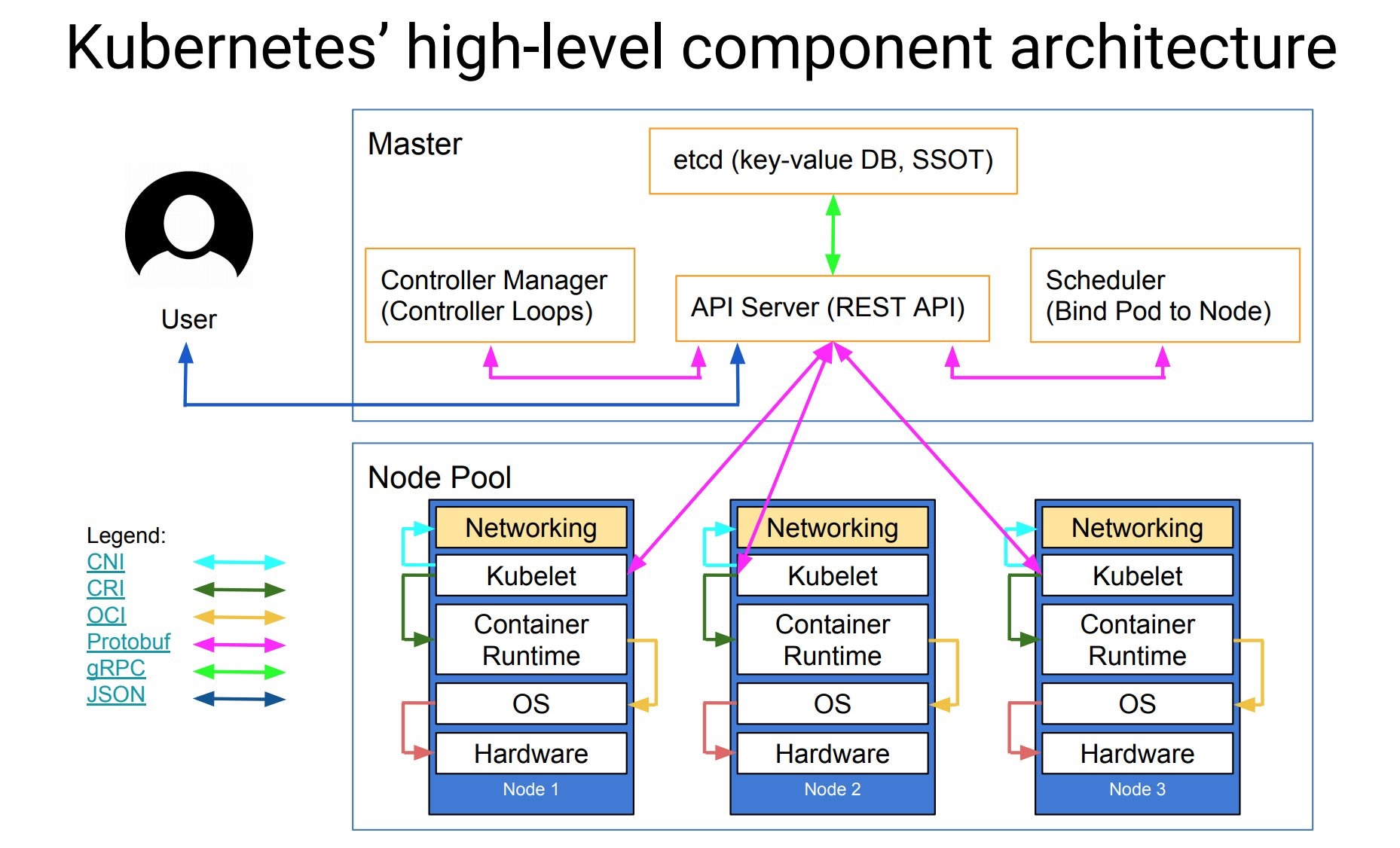
工作节点(Node节点)上最核心的组件是kubelet,它负责与底层的容器运行时进行通信,比如Docker。Kubernetes将这个通信过程抽象成了一个远程调用接口,称为CRI(Container Runtime Interface)。这个接口定义了容器运行时的所有标准操作,例如创建和删除容器。目前,kubelet内置了Docker关于CRI的实现,因此如果底层使用的是Docker容器,则不需要单独安装CRI实现的组件。但是,其他容器运行时需要提供这样的接口实现组件。因此,Kubernetes不关心所部署的容器运行时是什么,只要它能够实现CRI接口,就可以被Kubernetes管理。这种设计使得Kubernetes具有很强的扩展性和灵活性,可以支持多种不同的容器运行时。
###
kubelet 的另外一个重要功能就是调用网络插件(`CNI`)和存储插件(`CSI`)为容器配置网络和存储功能,同样的 kubelet 也是把这两个重要功能通过接口暴露给外部了,所以如果我们想要实现自己的网络插件,只需要使用 CNI 就可以很方便的对接到 Kubernetes 集群当中去。
###
可能下面的架构图看上去更清晰一些:
- 基础
- 开篇简介
- 组件介绍
- 环境准备
- Docker安装
- Kubeadm kubelet kubectl安装
- 初始化集群
- k8s集群导入Rancher2
- 集群清理
- Pod原理
- Pod的状态
- Pod重启策略
- Pod初始化容器
- init-pod.yaml
- Pod Hook钩子
- poststart-pod.yaml
- prestop-pod.yaml
- Pod健康检查
- 存活探针exec和http
- liveness-exec.yaml
- liveness-http.yaml
- 启动探针
- startup-http.yaml
- 就绪探针
- readiness-http.yaml
- Pod资源配置
- 静态Pod
- static-web.yaml
- Downward API
- 环境变量
- env-pod.yaml
- Volume挂载
- volume-pod.yaml
- 控制器
- ReplicaSet
- nginx-rs.yaml
- Deployment
- nginx-deploy.yaml
- 水平伸缩
- 滚动更新
- 有无状态服务
- 初识Service
- 初识HeadlessService
- HeadlessService.yaml
- 初识PV
- pv-demo.yaml
- StatefulSet
- pv.yaml
- headless-svc.yaml
- nginx-sts.yaml
- DaemonSet
- nignx-ds.yaml
- Job
- job-demo.yaml
- CronJob
- cronjob-demo.yaml
- HPA介绍
- MetricsServer安装
- HPA实战(基于cpu)
- hpa-demo-cpu.yaml
- HPA实现(基于内存)
- hpa-demo-mem.yaml
- 配置管理
- ConfigMap的创建
- configmap-demo.yaml
- Configmap的使用
- 环境变量中使用
- configmap_create_1.yaml
- 命令行当中使用
- configmap_create_2.yaml
- 数据卷挂载使用
- configmap_create_3.yaml
- configmap_create_4.yaml
- 安全
- RBAC
- 网络
- 网络插件
- 网络策略
- Service服务
- 三种IP
- 定义Service
- kube-proxy
- Iptables
- Ipvs
- Service
- NodePort类型
- deployment-service-demo2.yaml
- ExternalName
- endpoints-service.yaml
- ClusterIp
- deployment-service-demo1.yaml
- Service服务是如何被访问到的以及iptable和ipvs转发原理
- ClusterIP和NodePort再讲解
- 获取客户端IP
- DNS
- k8s当中service服务发现之DNS
- k8s当中通过dns访问普通service服务总结
- k8s当中通过dns域名的形式直接访问到具体的pod
- k8s当中pod的dns策略有哪些?
- DNS优化
- 超时问题
- 性能测试
- 优化方案(一)
- 优化方案(二)
- Ingress
- Traefik
- 安装traefik
- k8s当中基于traefik创建一个用于Dashboard访问的资源清单
- k8s当中利用traefik部署一个http请求的简单的小项目
- k8s当中利用traefik部署一个https请求的简单的小项目
- k8s当中traefik里面实现使用 Let’s Encrypt 来进行自动化 HTTPS
- k8s当中traefik当中的中间件讲解
- k8s当中traefik当中的灰度发布
- k8s当中traefik当中的流量复制
- 调度器
- k8s当中的调度器之kube-scheduler
- k8s当中调度器之调度器调优以及pod优先级调优
- k8s当中pod调度之nodeselector的用法将pod调度到指定node节点
- k8s当中的pod调度之节点亲和性
- k8s当中pod调度之pod亲和性
- k8s当中pod调度之pod反亲和性
- k8s当中pod调度之污点与容忍
- 存储
- k8s当中pv和pvc的创建以及注意点之local本地存储
- k8s当中的local pv的创建和注意点
- k8s当中nfs存储pv pvc绑定的具体使用说明
- DevOps工具部署
- JenKins GitLab Harbor系列
- JenKins安装部署
- Jenkins架构
- GitLab安装部署和排坑
- Git实战以及Gitlab使用
- Harbor的部署和排坑
- Harbor推送和拉取镜像
- k8s当中自定义域名集群内外访问的话该如何配置
- (Golang-CICD)k8s当中JenKins+GitLab+Harbor实现CICD(1)
- (Golang-CICD)k8s当中JenKins+GitLab+Harbor实现CICD(2)
- (Golang-CICD)k8s当中JenKins+GitLab+Harbor实现CICD(3)
- (Golang-CICD)k8s当中JenKins+GitLab+Harbor实现CICD(4)
- (Java-CICD)k8s当中Jenkins+GitLab+Harbor实现CICD
- (Php-CICD)k8s当中Jenkins+GitLab+Harbor实现CICD
- 集群备份
- (业务)velero备份集群到阿里云oss(实战一)
- (业务)集群命名空间恢复实战(实战二)
- (业务)velero备份集群常用命令总结(实战三)
- 集群磁盘扩容
- vm虚机磁盘扩容准备工作
- 执行库容操作