

下面是视频(优酷的清晰度有限):还是建议大家去B站观看:[B站观看地址](https://www.bilibili.com/video/BV1sE411P7C1/)。如果您觉得我做的工作对您有帮助,请去B站点赞、关注、转发、收藏,您的支持是我不竭的创作动力!
```[youku]
XNDYxMzYyODYzMg
```
## 一、粉丝的反馈

**问:stream比for循环慢5倍,用这个是为了啥?**
答:互联网是一个新闻泛滥的时代,三人成虎,以假乱真的事情时候发生。作为一个技术开发者,要自己去动手去做,不要人云亦云。
的确,这位粉丝说的这篇文章我也看过,我就不贴地址了,也没必要给他带流量。怎么说呢?就是一个不懂得测试的、不入流开发工程师做的性能测试,给出了一个危言耸听的结论。
## 二、所有性能测试结论都是片面的
性能测试是必要的,但针对性能测试的结果,永远要持怀疑态度。为什么这么说?
* 性能测试脱离业务场景就是片面的性能测试。你能覆盖所有的业务场景么?
* 性能测试脱离硬件环境就是片面的性能测试。你能覆盖所有的硬件环境么?
* 性能测试脱离开发人员的知识面就是片面的性能测试。你能覆盖各种开发人员奇奇怪怪的代码么?
所以,我从来不相信网上的任何性能测试的文章。凡是我自己的从事的业务场景,我都要在接近生产环境的机器上自己测试一遍。 **所有性能测试结论都是片面的,只有你生产环境下的运行结果才是真的。**
## 三、动手测试Stream的性能
### 3.1.环境
windows10 、16G内存、i7-7700HQ 2.8HZ 、64位操作系统、JDK 1.8.0_171
### 3.2.测试用例与测试结论
我们在上一节,已经讲过:
* 针对不同的数据结构,Stream流的执行效率是不一样的
* 针对不同的数据源,Stream流的执行效率也是不一样的
所以记住笔者的话:**所有性能测试结论都是片面的**,你要自己动手做,相信你自己的代码和你的环境下的测试!我的测试结果仅仅代表我自己的测试用例和测试数据结构!
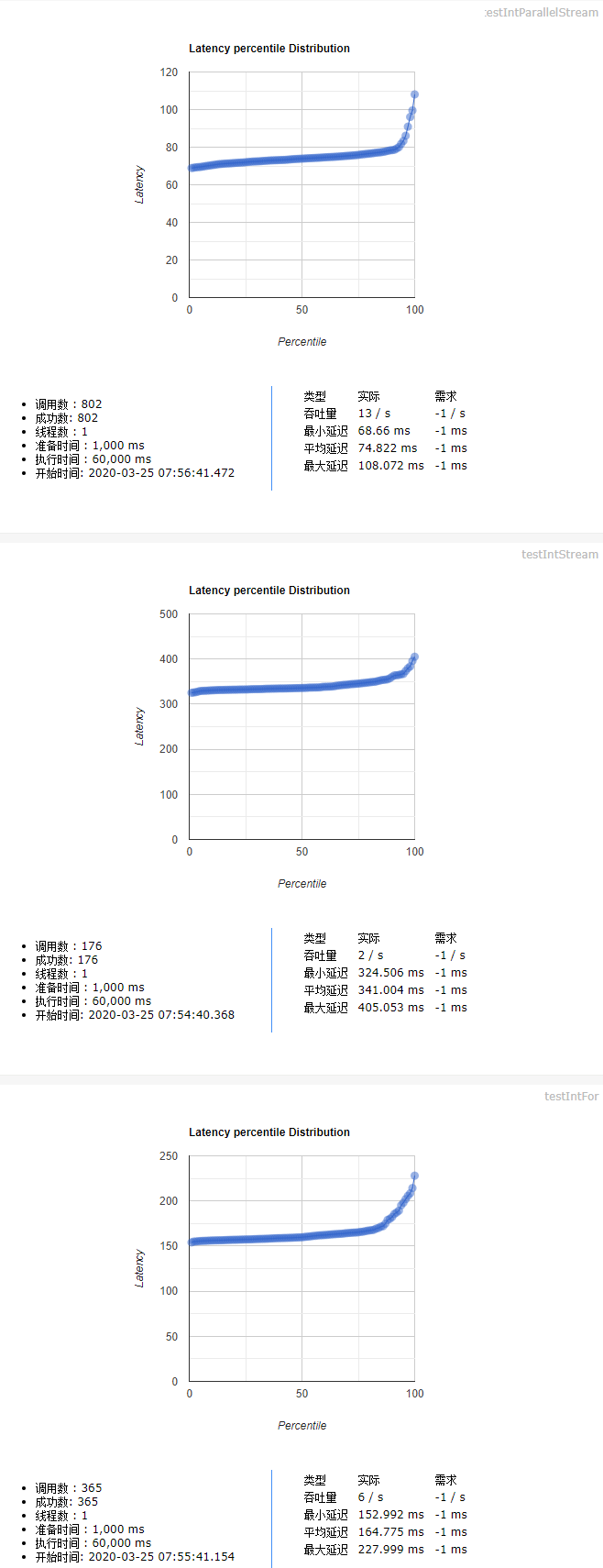
#### 3.2.1.测试用例一
测试用例:5亿个int随机数,求最小值
测试结论(测试代码见后文):
* 使用普通for循环,执行效率是Stream串行流的2倍。也就是说普通for循环性能更好。
* Stream并行流计算是普通for循环执行效率的4-5倍。
* Stream并行流计算 > 普通for循环 > Stream串行流计算
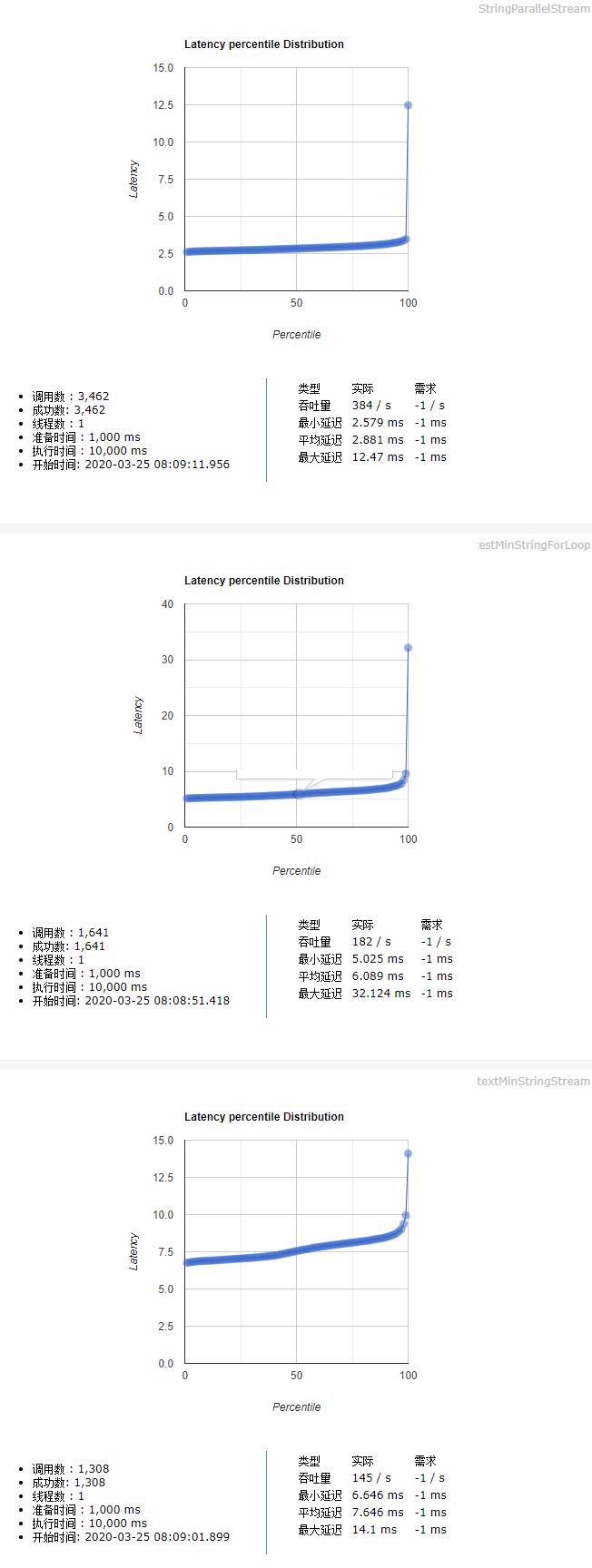
### 3.2.测试用例二
测试用例:长度为10的1000000随机字符串,求最小值
测试结论(测试代码见后文):
* 普通for循环执行效率与Stream串行流不相上下
* Stream并行流的执行效率远高于普通for循环
* Stream并行流计算 > 普通for循环 = Stream串行流计算
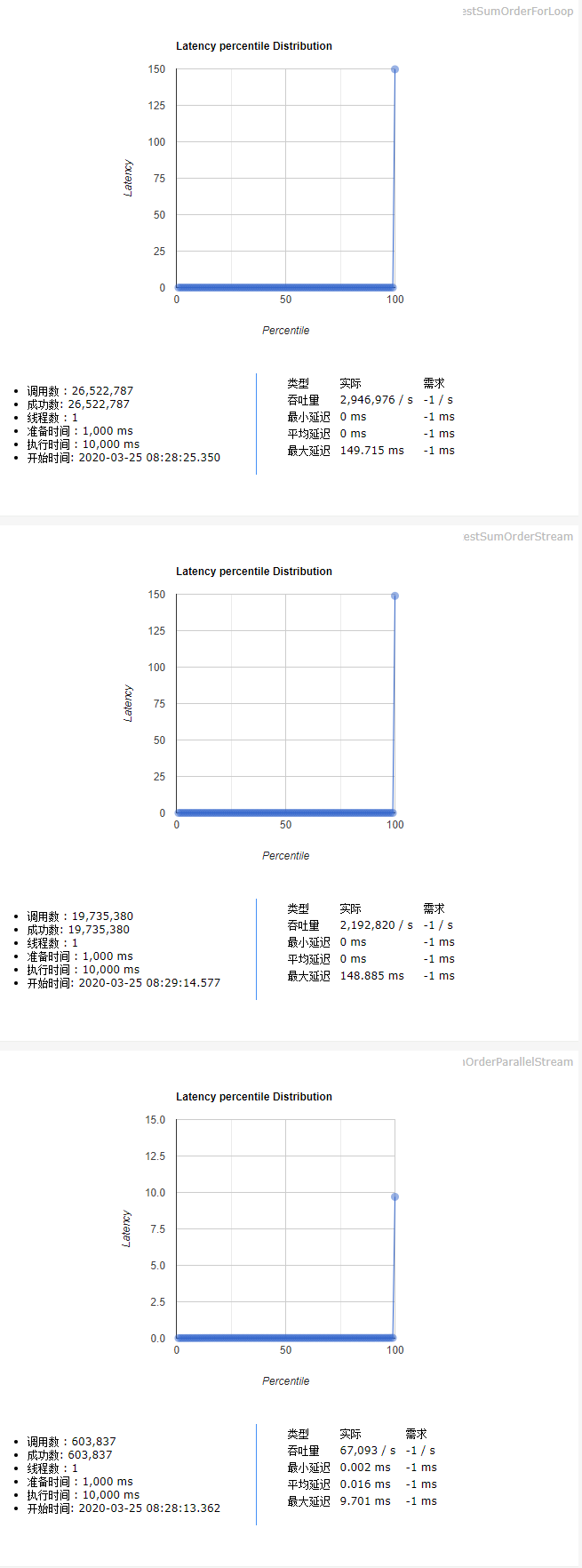
### 3.3.测试用例三
测试用例:10个用户,每人200个订单。按用户统计订单的总价。
测试结论(测试代码见后文):
* Stream并行流的执行效率远高于普通for循环
* Stream串行流的执行效率大于等于普通for循环
* Stream并行流计算 > Stream串行流计算 >= 普通for循环
## 四、最终测试结论
* 对于简单的数字(list-Int)遍历,普通for循环效率的确比Stream串行流执行效率高(1.5-2.5倍)。但是Stream流可以利用并行执行的方式发挥CPU的多核优势,因此并行流计算执行效率高于for循环。
* 对于list-Object类型的数据遍历,普通for循环和Stream串行流比也没有任何优势可言,更不用提Stream并行流计算。
虽然在不同的场景、不同的数据结构、不同的硬件环境下。Stream流与for循环性能测试结果差异较大,甚至发生逆转。**但是总体上而言**:
* Stream并行流计算 >> 普通for循环 ~= Stream串行流计算 (之所以用两个大于号,你细品)
* 数据容量越大,Stream流的执行效率越高。
* Stream并行流计算通常能够比较好的利用CPU的多核优势。CPU核心越多,Stream并行流计算效率越高。
stream比for循环慢5倍?也许吧,单核CPU、串行Stream的int类型数据遍历?我没试过这种场景,但是我知道这不是应用系统的核心场景。看了十几篇测试博文,和我的测试结果。我的结论是: **在大多数的核心业务场景下及常用数据结构下,Stream的执行效率比for循环更高。** 毕竟我们的业务中通常是实实在在的实体对象,没事谁总对`List<Int>`类型进行遍历?谁的生产服务器是单核?。
## 五、测试代码
~~~
<dependency>
<groupId>com.github.houbb</groupId>
<artifactId>junitperf</artifactId>
<version>2.0.0</version>
</dependency>
~~~
测试用例一:
~~~
import com.github.houbb.junitperf.core.annotation.JunitPerfConfig;
import com.github.houbb.junitperf.core.report.impl.HtmlReporter;
import org.junit.jupiter.api.BeforeAll;
import java.util.Arrays;
import java.util.Random;
public class StreamIntTest {
public static int[] arr;
@BeforeAll
public static void init() {
arr = new int[500000000]; //5亿个随机Int
randomInt(arr);
}
@JunitPerfConfig( warmUp = 1000, reporter = {HtmlReporter.class})
public void testIntFor() {
minIntFor(arr);
}
@JunitPerfConfig( warmUp = 1000, reporter = {HtmlReporter.class})
public void testIntParallelStream() {
minIntParallelStream(arr);
}
@JunitPerfConfig( warmUp = 1000, reporter = {HtmlReporter.class})
public void testIntStream() {
minIntStream(arr);
}
private int minIntStream(int[] arr) {
return Arrays.stream(arr).min().getAsInt();
}
private int minIntParallelStream(int[] arr) {
return Arrays.stream(arr).parallel().min().getAsInt();
}
private int minIntFor(int[] arr) {
int min = Integer.MAX_VALUE;
for (int anArr : arr) {
if (anArr < min) {
min = anArr;
}
}
return min;
}
private static void randomInt(int[] arr) {
Random r = new Random();
for (int i = 0; i < arr.length; i++) {
arr[i] = r.nextInt();
}
}
}
~~~
测试用例二:
~~~
import com.github.houbb.junitperf.core.annotation.JunitPerfConfig;
import com.github.houbb.junitperf.core.report.impl.HtmlReporter;
import org.junit.jupiter.api.BeforeAll;
import java.util.ArrayList;
import java.util.Random;
public class StreamStringTest {
public static ArrayList<String> list;
@BeforeAll
public static void init() {
list = randomStringList(1000000);
}
@JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class})
public void testMinStringForLoop(){
String minStr = null;
boolean first = true;
for(String str : list){
if(first){
first = false;
minStr = str;
}
if(minStr.compareTo(str)>0){
minStr = str;
}
}
}
@JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class})
public void textMinStringStream(){
list.stream().min(String::compareTo).get();
}
@JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class})
public void testMinStringParallelStream(){
list.stream().parallel().min(String::compareTo).get();
}
private static ArrayList<String> randomStringList(int listLength){
ArrayList<String> list = new ArrayList<>(listLength);
Random rand = new Random();
int strLength = 10;
StringBuilder buf = new StringBuilder(strLength);
for(int i=0; i<listLength; i++){
buf.delete(0, buf.length());
for(int j=0; j<strLength; j++){
buf.append((char)('a'+ rand.nextInt(26)));
}
list.add(buf.toString());
}
return list;
}
}
~~~
测试用例三:
~~~
import com.github.houbb.junitperf.core.annotation.JunitPerfConfig;
import com.github.houbb.junitperf.core.report.impl.HtmlReporter;
import org.junit.jupiter.api.BeforeAll;
import java.util.*;
import java.util.stream.Collectors;
public class StreamObjectTest {
public static List<Order> orders;
@BeforeAll
public static void init() {
orders = Order.genOrders(10);
}
@JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class})
public void testSumOrderForLoop(){
Map<String, Double> map = new HashMap<>();
for(Order od : orders){
String userName = od.getUserName();
Double v;
if((v=map.get(userName)) != null){
map.put(userName, v+od.getPrice());
}else{
map.put(userName, od.getPrice());
}
}
}
@JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class})
public void testSumOrderStream(){
orders.stream().collect(
Collectors.groupingBy(Order::getUserName,
Collectors.summingDouble(Order::getPrice)));
}
@JunitPerfConfig(duration = 10000, warmUp = 1000, reporter = {HtmlReporter.class})
public void testSumOrderParallelStream(){
orders.parallelStream().collect(
Collectors.groupingBy(Order::getUserName,
Collectors.summingDouble(Order::getPrice)));
}
}
class Order{
private String userName;
private double price;
private long timestamp;
public Order(String userName, double price, long timestamp) {
this.userName = userName;
this.price = price;
this.timestamp = timestamp;
}
public String getUserName() {
return userName;
}
public double getPrice() {
return price;
}
public long getTimestamp() {
return timestamp;
}
public static List<Order> genOrders(int listLength){
ArrayList<Order> list = new ArrayList<>(listLength);
Random rand = new Random();
int users = listLength/200;// 200 orders per user
users = users==0 ? listLength : users;
ArrayList<String> userNames = new ArrayList<>(users);
for(int i=0; i<users; i++){
userNames.add(UUID.randomUUID().toString());
}
for(int i=0; i<listLength; i++){
double price = rand.nextInt(1000);
String userName = userNames.get(rand.nextInt(users));
list.add(new Order(userName, price, System.nanoTime()));
}
return list;
}
@Override
public String toString(){
return userName + "::" + price;
}
}
~~~
- 前言
- 1.lambda表达式会用了么
- 2.初识Stream-API
- 3.Stream的filter与谓语逻辑
- 4.Stream管道流的map操作
- 5.Stream的状态与并行操作
- 6.Stream性能差?不要人云亦云
- 7.像使用SQL一样排序集合
- 8.函数式接口Comparator
- 9.Stream查找与匹配元素
- 10.Stream集合元素归约
- 11.StreamAPI终端操作
- 12.java8如何排序Map
- Stream流逐行文件处理
- java8-forEach(持续发布中)
- 笔者其它作品推荐
- vue深入浅出系列
- 手摸手教你学Spring Boot2.0
- Spring Security-JWT-OAuth2一本通
- 实战前后端分离RBAC权限管理系统
- 实战SpringCloud微服务从青铜到王者