
# ClicKHouse基本语法
[TOC]
## 数据库操作
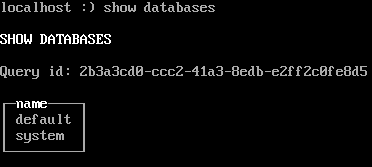
show databases ;
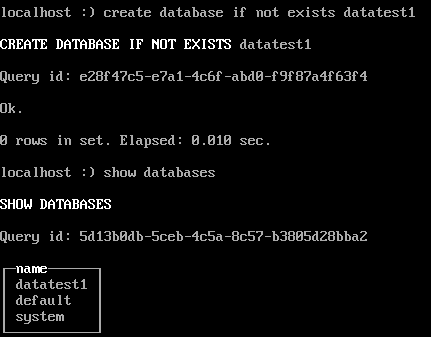
create database if not exists datatest1;
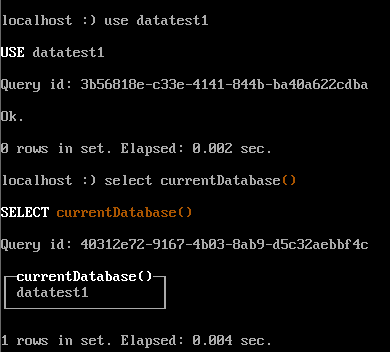
use datatest1;
select currentDatabase() ;
-- 删除库
drop database datatest1;
## DDL语句
- 建表
> <p style="color:red">目前只有MergeTree、Merge和Distributed这三类表引擎支持ALTER语法</p>,所以在进行alter操作的时候注意表的引擎
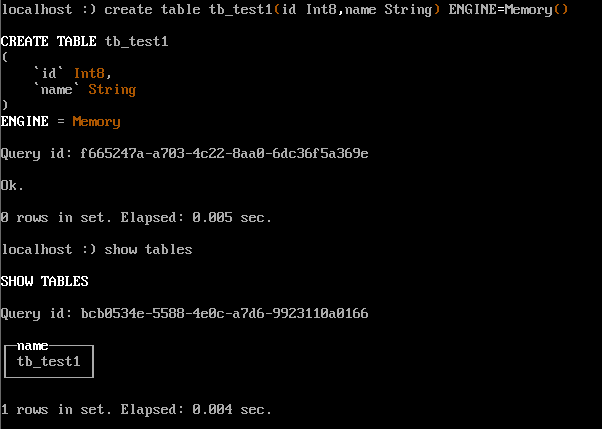
**ClickHouse中建表的时候一定要求指定表的引擎**
Memory 引擎以未压缩的形式将数据存储在 RAM 中,重新启动服务器时,表中的数据消失,表将变为空。一般用于测试。
```SQL
CREATE TABLE tb_test1 ( `id` Int8, `name` String ) ENGINE = Memory() ;
```
- 修改表结构
```
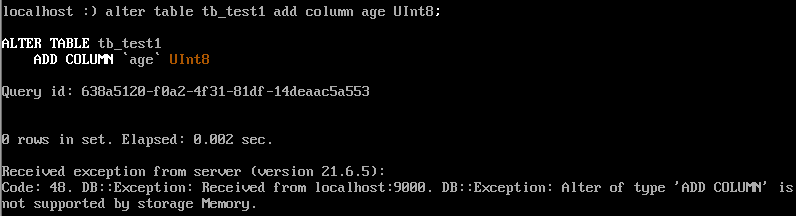
alter table tb_test1 add column age UInt8 ;
```
提示异常:
- 创建MergeTree引擎的表
> Clickhouse 中最强大的表引擎当属`MergeTree`(合并树)引擎及该系列(`*MergeTree`)中的其他引擎。
> MergeTree系列的引擎被设计用于插入极大量的数据到一张表当中。数据可以以数据片段的形式一个接着一个的快速写入,数据片段在后台按照一定的规则进行合并。相比在插入时不断修改(重写)已存储的数据,这种策略会高效很多。
先追加再合并
MergeTree引擎一定要指定主键,用于合并排序,order by默认指定主键
```
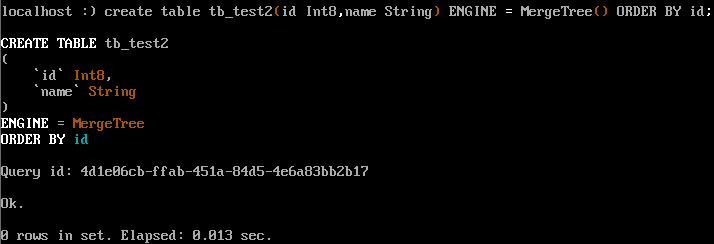
CREATE TABLE tb_test2 ( `id` Int8, `name` String ) ENGINE = MergeTree() ORDER BY id ;
```
- 添加字段
```
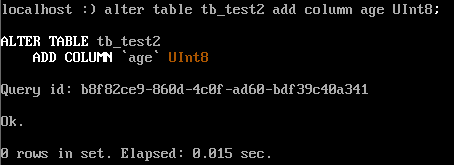
alter table tb_test1 add column age UInt8 ;
```
```
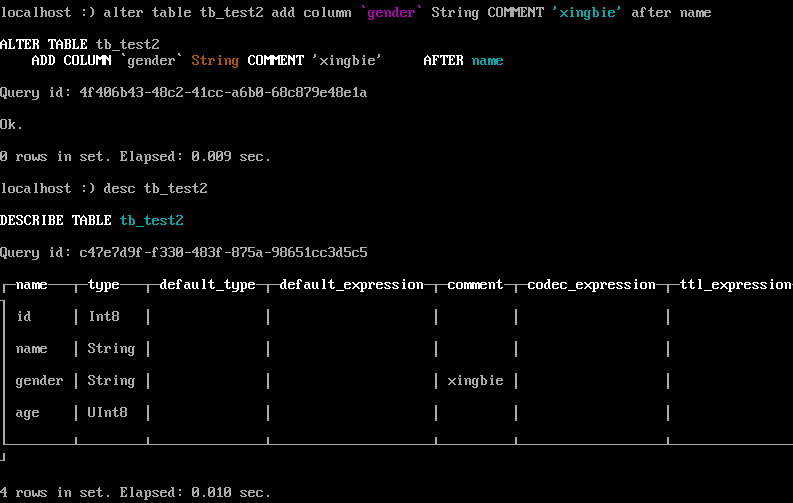
alter table tb_test2 add column gender String comment '性别' after name ;
```
- 删除字段
```
alter table tb_test2 drop column age ;
```
- 修改字段的数据类型
```
alter table tb_test2 modify column gender UInt8 default 0 ;
```
## DML语句
- 插入数据
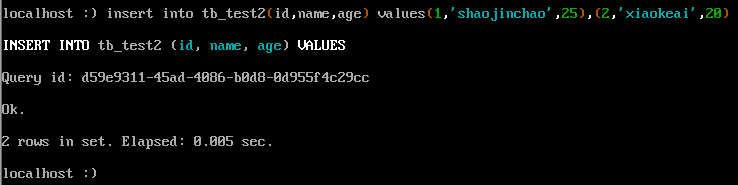
<p style="color:red">只有mergeTree引擎才能对表数据进行修改</p>
- 删除
```
alter table tb_test2 delete where id=2 ;
```
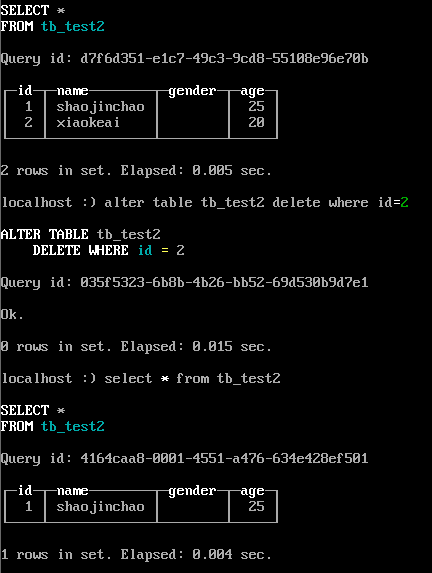
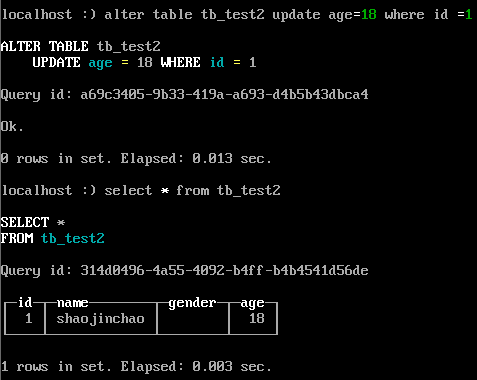
- 更新
alter table tb_test2 update age=18 where id=1
## 分区操作
<p style="color:red">目前只有MergeTree系列 的表引擎支持数据分区</p>
- 创建表
```
create table test_partition1( id String , ctime DateTime)engine=MergeTree() partition by toYYYYMM(ctime) order by (id) ;
```
- 插入数据
```
insert into test_partition1 values(1,now()) ,(2,'2021-06-11 10:12:11'),(3,'2021-07-20 10:12:11') ,(4,'2020-01-20 10:12:11') ;
```
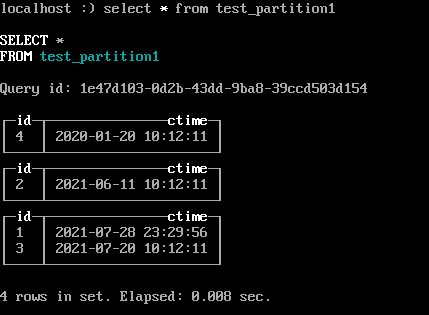
- 分区命名规则
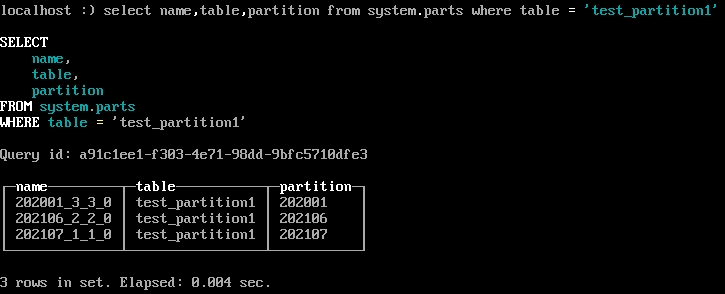
> 分区数据如果是数字就按数字命名分区文件夹,如果含字符串,则按Hash值来命名,可以根据内置system系统表查询partition的值
按年月分区
插入数据后在/var/lib/clickhouse/data/的数据库和表里可以看到多个文件夹
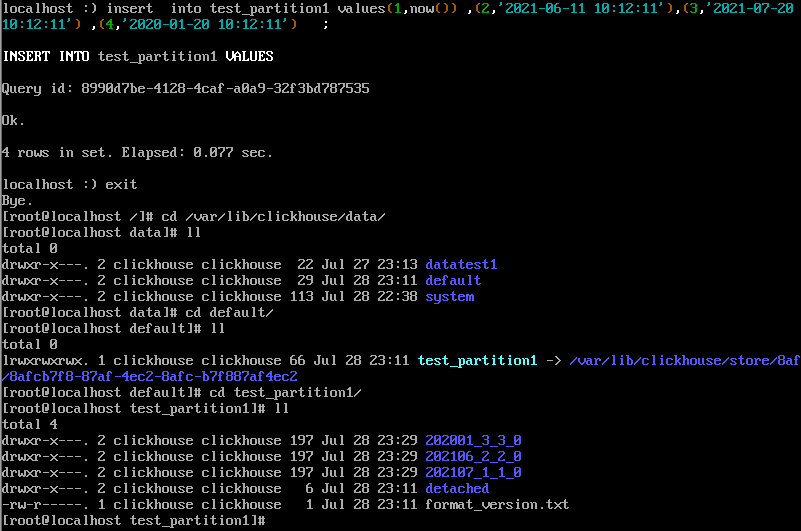
ClickHouse内置了许多system系统表,用于查询自身的状态信息。 其中parts系统表专门用于查询数据表的分区信息
- 删除分区
```
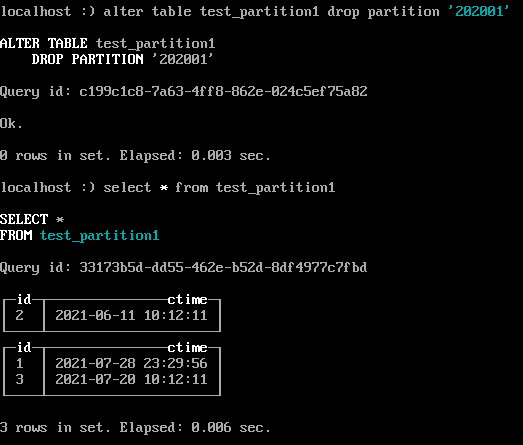
-- 删除一个分区的数据
alter table test_partition1 drop partition '202001' ;
```
- 复制分区
clickHouse支持将A表的分区数据复制到B表,这项特性可以用于快速数据写入、多表间数据同步和备份等场景,它的完整语法如下:
ALTER TABLE B REPLACE PARTITION partition_expr FROM A
不过需要注意的是,并不是任意数据表之间都能够相互复制,它们还需要满足两个前提 条件:
·两张表需要拥有相同的分区键
·它们的表结构完全相同。
```
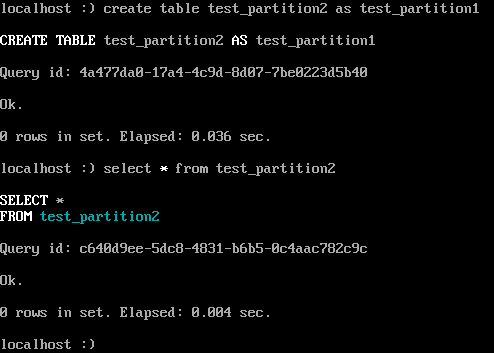
create table test_partition2 as test_partition1 ;
show create table test_partition2 ; -- 查看表2的建表语句
```
│ CREATE TABLE default.test_partition2
(
`id` String,
`ctime` DateTime
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(ctime)
ORDER BY id
SETTINGS index_granularity = 8192 │ -- 两张表的结构完全一致
-- 复制一张表的分区到另一张表中
```
alter table test_partition2 replace partition '202106' from test_partition1
```
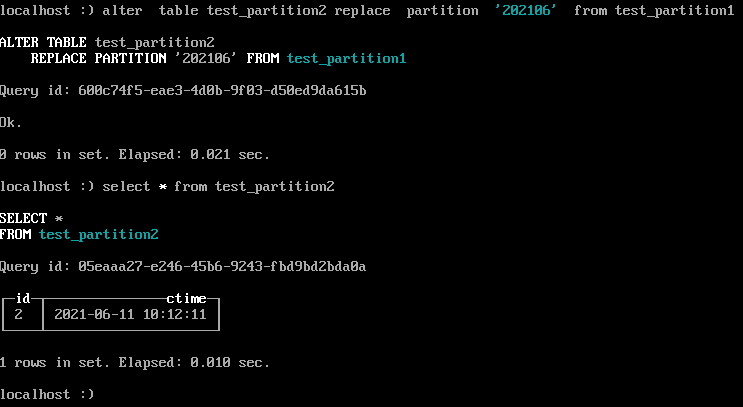
- 重置分区
如果数据表某一列的数据有误,需要将其重置为初始值,如果设置了默认值那么就是默认值数据,如果没有设置默认值,会给出系统默认的初始值,此时可以使用下面的语句实现:
```
alter table test_partition2 clear column name in partition '202107' ;
```
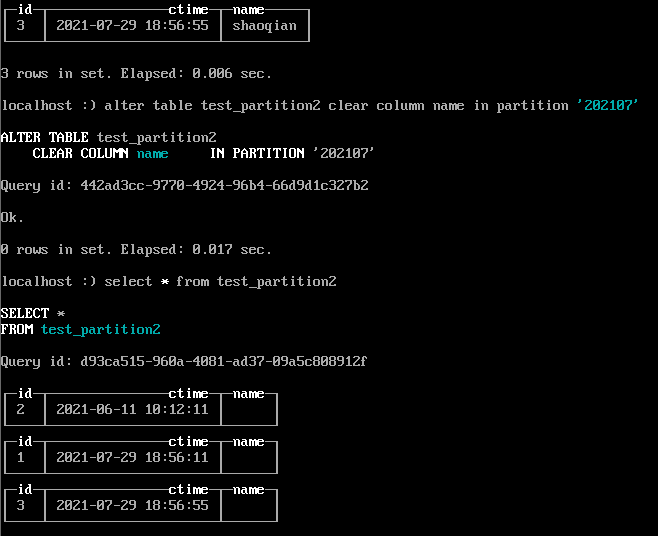
- 分区卸载和装载
分区被卸载后,它的物理数据并没有删除,而是被转移到了当前数据表目录的detached子目录下
```
-- 分区卸载
alter table test_partition2 detach partition '202106' ;
```
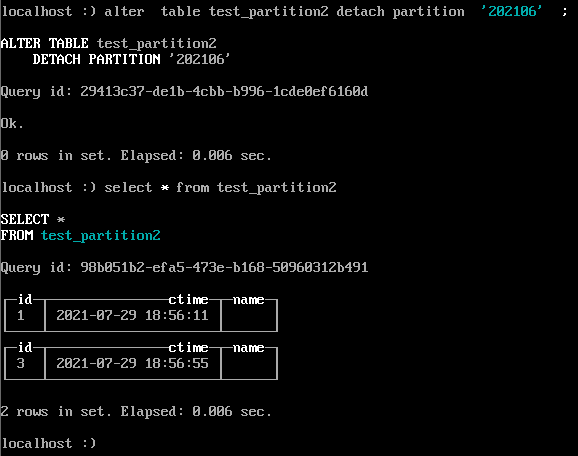
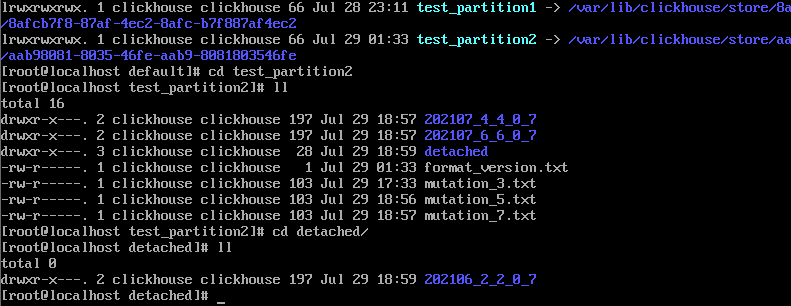
```
-- 装载分区
alter table ttest_partition2 attach partition '202106';
```
## 视图
> ClickHouse拥有普通和物化两种视图,其中物化视图拥有独立的存储,而普通视图只是一层简单的查询代理
- 普通视图
普通视图不会存储任何数据,它只是一层单纯的SELECT查询映射,起着简化查询、明晰语义的作用,对查询性能不会有任何增强。类似mysql。
- 物化视图
物化视图支持表引擎,数据保存形式由它的表引擎决定,创建物化视图的完整语法如下所示
```
create materialized view mv_log engine=Log populate as select * from log ;
```
1)加上populate修饰符会在创建视图的过程中,会连带将源表中已存在的数据一并导入。
2)不使用POPULATE修饰符,那么物化视图在创建之后是没有数据的。
3)物化视图只会同步在此之后被写入源表的数据。目前并不支持同步删除,如果在源表中删除了数据,物化视图的数据仍会保留。
- ClickHouse
- 第一节 ClickHouse入门
- 1.1ClickHouse概述
- 1.2ClickHouse单机安装
- 1.3ClickHouse配置
- 1.4ClickHouse数据库引擎
- 1.5ClickHouse集群部署
- 第二节 ClickHouse进阶
- 2.1ClicKHouse数据类型
- 2.2ClicKHouse基本语法
- 2.3ClickHouse引擎
- 2.4ClickHouse函数
- 2.5ClickHouse分布式表
- 2.6ClickHouse权限和密码加密
- 2.7ClickHouse数据导入和导出
- 第三节 ClicKHouse实战篇
- 3.1ClickHouse的JDBC连接
- 3.2ClickHouse用户行为分析
- 3.3ClickHouse实战
- 第四节 ClicKHouse常见问题
- 4.1ClickHouse常见问题汇总
- 第五节 ClickHouse其他
- 5.1ClickHouse可视化工具
- 5.2ClickHouse学习教程