
一.缓存雪崩,缓存穿透,缓存击穿
1.缓存穿透:
key对应的数据在数据源并不存在,每次针对此key的请求从缓存获取不到,请求都会到数据源,从而可能压垮数据源。比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库
解决方案(最粗暴的):
如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟
缺点:如果key数量巨大且分散无任何规律,就会浪费大量缓存空间,并且不能抗住瞬时流量冲击
2.缓存击穿(#热点key):
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮
解决方案:
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
3.缓存雪崩:
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,也会给后端系统(比如DB)带来很大压力
解决方案:
使用锁或队列、设置过期标志更新缓存、为key设置不同的缓存失效时间,还有一种被称为“二级缓存”的解决方法;
方案:设置过期标志更新缓存
做缓存标记,记录缓存数据是否过期;标记缓存时间30分钟,数据缓存设置为60分钟。这样,当缓存标记key过期后,实际缓存还能把旧数据返回给调用端,直到另外的线程在后台更新完成后,才会返回新缓存
方案: 双层缓存策略
C1为原始缓存,C2为拷贝缓存,C1失效时,可以访问C2,C1缓存失效时间设置为短期,C2设置为长期
4.总结

二.缓存与数据库双写不一致
(1)只读缓存( **`Cache Aside` ****模式)**
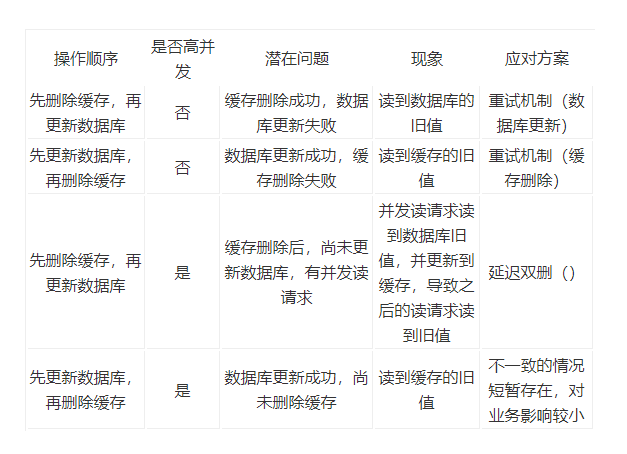
总结出, 当不存在并发的情况使用重试机制(消息队列使用),当存在高并发的情况,使用延迟双删除(在第一次删除后,睡眠一定时间后,再进行删除)
(2)读写缓存(Read/Write-Throug、Write Behind模式 )
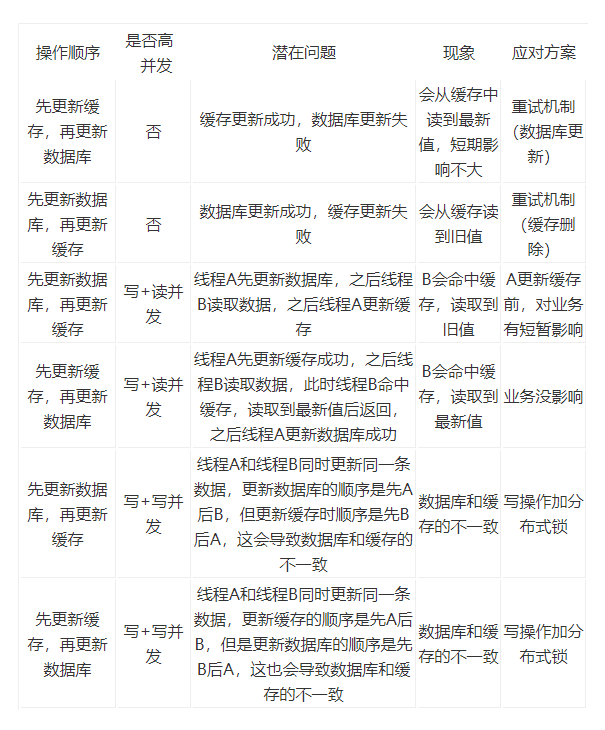
总结出,当不存在并发的情况使用重试机制(消息队列使用),当存在高并发的情况,使用分布锁
- linux
- lanmp
- lanmp
- apache
- Apache2.4.x与Apache2.2.x的一些区别
- 跨域请求 Apache 服务器配置
- apache服务器安装配置ssl数字证书,https访问
- put请求跨区
- apache允许跨域请求 & ajax 自定义header
- 自定义header
- 安装最新版openssl
- nginx
- 解决Nginx出现403 forbidden的方法
- nginx: [error] open() "/usr/local/var/run/nginx.pid" failed (2: No such file or directory)
- 如何用linux命令查看nginx是否在正常运行
- nginx反向代理
- nginx 编译安装
- nginx重定向
- 一个域名对应多个vue项目
- 关于http和https允许请求设置header问题
- nginx配置ssl证书
- 配置宝塔nginx支持tp5路由规则
- nginx获取自定义请求头header
- mysql
- 创建还量表
- 解决Navicat 出错:1130-host . is not allowed to connect to this MySql server,MySQL
- mysql慢查询
- explain
- 索引
- sphinx
- coreseek(sphinx)错误:WARNING: attribute 'id' not found - IGNORING原因及解决方法
- coreseek在windows安装问题和使用步骤
- coreseek常见错误
- coreseek php操作
- mysql5.6升级5.7.21
- sql操作
- mysql函数
- phpmyadmin上传文件大小限制
- mysql主从复制
- 单机主从配置
- 修改mysql端口后修改相应的phpmyadmin端口
- MERGE分表
- MySQL 5.7.22 多实例安装(二进制免编译安装模式)
- 解决phpmyadmin mysqli_real_connect(): (HY000/2002): No such file or directory错误
- Mysql服务器无法存emoji表情的解决方案
- /var/run/mysqld 目录每次重启后都需要手动去创建并赋权mysql用户才能起到mysql
- mysql排序
- mysql关键字冲突
- mysql备份
- mysql5.7密码修改
- 更改MySQL数据库目录位置
- mysql5.6安装
- 字符集与排序规则
- mysql 锁
- mysql事务性
- php
- centos7 升级 php 5.4 -> php5.6
- php扩展
- linux切换默认php版本(宝塔)
- vsftpd
- 关于vsftp出现Restarting vsftpd (via systemctl): Job for vsftpd.service failed because the control 的解决办法
- vdb
- fdisk
- parted
- 磁盘小知识
- CentOS7.x系统根目录分区扩容
- Linux 格式化分区 报错Could not stat --- No such file or directory 和 partprobe 命令
- 添加swap交换区
- root
- Centos创建和修改用户及密码命令
- linux 命令终端提示符显示-bash-4.2#解决方法
- firewall
- centOS7下安装GUI图形界面
- 在Linux主机上,安装上传下载工具包rz及sz
- ping: www.baidu.com: Name or service not known centos7
- linux中 you have newmail in /var/spool/mail/root
- CentOS7启动SSH服务报:Job for ssh.service failed because the control process exited with error code.......
- ifconfig,netstat 命令找不到解決办法
- CentOS7系统时间与真实时间相差8小时
- Centos7:利用crontab定时执行任务
- crontab命令
- /usr/bin/curl 执行外链
- speedtest-cli命令,网速测试
- yum 卸载命令
- 用户管理
- PATH环境变量
- rpm 命令
- 防火墙和网络的安装
- nohup
- vim命令
- 清理缓存命令
- 错误集
- tar解压包的时候出现错误 gzip: stdin: not in gzip format
- 在linux下创建自定义service服务
- 时钟同步
- 查找大文件
- redis
- yum安装
- redis主从复制
- php用法
- redis表的特性
- redis 锁
- redis事务
- redis主从配置+哨兵模式
- redis应用场景
- redis高并发集群下常见问题
- redis思维导图
- 脑图1
- 脑图2
- redis编码
- redis字符串编码
- hash编码
- list编码
- set编码
- zset编码
- 内存回收和内存共享
- redis小知识点
- ffmpeg
- yum安装ffmpeg
- ffmpeg-php类库安装及使用
- make安装
- WebRTC
- 房间服务器
- 信令服务器
- 打洞服务器
- PHP识别二维码(php-zbarcode)
- centos7.4安装Imagemagick
- 第二种方式
- linux小知识
- 查看日志命令
- linux CPU使用率过高或负载过高的处理
- swoole安装
- mq安装
- RabbitMQ安装
- php-amqplib使用--基本使用
- RabbitMQ使用技巧
- tp5
- problem
- thinkphp5的mkdir() Permission denied问题
- 5.5版本以上”No input file specified“问题解决
- 路由带参数的翻页,第二页无数据
- 报错A non well formed numeric value encountered(Thinkphp5时间戳自动转换问题)
- order排序没反应
- tp5分页--搜索
- tp5文件上传---宝塔
- 小知识
- return
- volist标签中使用eq标签 下拉列表选中selected
- TP5写入避免某字段重复的问题
- tp5 --url大小写
- tp5接收数组
- json存储与查询
- 接收参数为null
- php替换str_replace的使用方法,支持多个替换
- postman传数组参数
- Request 排除变量传参
- sql连表统计查询
- php循环
- 模型column方法
- 修改器与获取器
- mysql数据库group与order不能同时使用
- mysql三表查询
- json数据
- 获取数组第一个获第二个元素的键值
- mysql除以100计算
- mysql分组统计
- tp5.1 高级查询之 表里2字段比较大小
- whereOr()用法
- param数字参数,不能用==判断相等,需要用=来判断
- if判断
- tp5随机排序
- 短链接算法
- $_FILES["file"]二进制数据获取
- 跨域
- web.config
- iis: httpd相应标头
- thikphp模板中一维数组如何循环
- tp5 视频上传及自定义命名
- 搜索附近的人
- 小程序
- uploadFile:fail Error: unable to verify the first certificate
- 安卓手机打开小程序提示:request:fail ssl hand shake error
- tp5.1引入库文件
- composer
- tp5小知识
- TP5.1隐藏public和index.php
- tp5扩展
- 二维码
- phpexcel
- 谷歌验证码
- 谷歌验证码2
- mysql时间统计
- union合并查询并分页
- tp5底层框架学习
- php未知函数
- 类的知识点
- 三大设计模式
- 反射机制
- php常用内置类
- php小知识点
- 变量,函数名,参数前加&,什么意思
- PHP中 比较 0、false、null,'' "
- php小常识
- php缓存
- Trait特性
- php -- 取路径:getcwd()、DIR、FILE 的区别
- php关于类的常用概念
- php 类与对象全面了解
- php命名空间与引入
- php常见魔法常量
- php常见魔法函数
- PHP 超级全局变量
- tp5.1本身小知识
- 框架运行流程
- 框架教程总结
- 类的自动加载
- 配置文件
- ArrayAccess用法
- yaconf学习
- yaml学习
- config类重点
- php小知识2
- 多语言切换
- jwt(token)
- redis连接池
- 百度富文本
- 图片路径转换
- layui
- 复选框
- 获取视频第几帧作为封面图
- mysql查询
- FIND_IN_SET(str,strlist)
- PHP
- 函数取整
- array
- 日期
- header
- php获取一维,二维数组长度的方法
- php中数组和字符串的相互转换
- php对数组开头与末尾的元素进行插入与移除
- 队列
- PHP substr截取中文字符出现乱码的问题解疑
- foreach遍历数组并添加属性(下标)
- 数组排序
- PHP实现保留两位小数的三种方法
- 对象转数组
- php小知识
- 阻塞IO和非阻塞IO,异步与同步的区别
- 后台运行
- 超时
- php 高精度计算的问题
- move_uploaded_file
- PHP SplQueue 队列简介
- @,&&等php符号
- PHP命令行脚本接收传入参数的三种方式
- php执行linux命令
- 一些封装函数
- PHP获取文件大小
- PHP 生成随机字符串与唯一字符串
- PHP去除emoji表情
- ip
- php把时间计算成几分钟前,几小时前,几天前的函数
- https
- ssl证书
- 远程登入密码和端口修改
- apache配置https
- problems
- 响应状态status为canceled,解决办法
- PHP Restful PUT方法的参数提交及接收
- HTTP之预检,两种请求
- http增删改查理解
- js
- js数组与字符串的相互转换
- js移除Array中指定元素
- 使用sessionStorage、localStorage存储数组与对象
- 子页面调用父页面方法
- input文件上传
- 随机字符串
- 数组操作
- js 传递数组
- token接入验证
- 用文件来保存token
- 删除用户资料
- 微信function
- 接入验证及点击事件
- 基础token
- 获取用户资料
- curl
- 链接分享
- 网页授权登入
- 微信被动回复用户消息
- 生成微信二维码
- WxPay
- 单一文件,不能加额外参数
- tp5引用微信支付官方库文件
- 微信二维码支付
- 其他
- 手机端发送ajax请求,后台有可能会接收不到到请求(360浏览器和ie浏览器)
- 短信发送
- git
- postman无法正常返回结果Could not get any response
- web服务器配置
- 高并发方案
- nginx防盗链和限制请求速度
- 高并发概念与测试工具
- 定时秒杀方案
- web接口
- yzdd
- 接口1
- 接口2
- spx
- 接口说明
- 新闻表sbh_artnews字段说明
- 用户表sbh_homeuser
- 用户认证表sbh_usertrue
- txsh
- 接口_txsh_1
- chat消息格式
- 表字段
- txsh_第三方接口
- GatewayWorker
- 向对方发送消息,对方会掉线
- 负载均衡
- html
- html中引入调用另一个html的方法
- python
- linux安装--python3.6
- Centos7卸载Python2.7之后恢复yum
- pycharm汉化
- python错误集
- fatal error: Python.h: No such file or directory
- Python小知识
- python中两个重要的工具setuptools和pip的安装
- 基础知识点
- 学习笔记
- tornado基础流程
- 请求与响应
- 以太坊
- 以太坊账户管理
- 一些方法的更新弃用
- 小知识点
- web3.eth.accounts 和 web3.eth.personal 创建account的区别
- web3.py中sendTransaction和sendRawTransaction之间的区别
- 测试网和主网区别
- 以太坊gas、gaslimit、gasPrice、gasUsed详解
- web安全
- web渗透--全面介绍
- 大概介绍
- xss--介绍
- sql注入-介绍
- 文件上传下载-介绍
- 越权--介绍
- xxe--介绍
- 暴力破解
- xss漏洞安全编码系列详解
- 反射型
- DOM型
- 存储型
- 图片隐写
- sql注入详解
- 数据库和其他--介绍
- mysql爆破
- web安全--工具
- sqlmap
- 介绍与安装
- sqlmap攻击方式
- Sqlmap中的其他
- sqlmap--get攻击
- sqlmap--post攻击
- sqlmap--常用选项及命令
- sqlmap--详解
- sqlmap--查看
- web安全简单总结
- api功能扩展
- 阿里云短信
- 阿里云短信sdk新版用法
- 阿里云对象存储 OSS
- 七牛云上传
- qq邮箱发送短信验证码
- 通过ip获取归属地
- 支付插件
- zoujingli
- swoole
- swoole启动关闭方案
- swoole服务端主动推送消息
- 创建websocket--systemctl自定义启动服务
- 创建php脚本来启动关闭websocket服务
- swoole小知识
- 进程/线程结构图
- 区块链
- 区块链概念理解
- usdt小知识点1
- 区块链架构1.0、2.0与3.0梳理
- 理解usdt和代币,智能合约,基础货币
- 波场tron
- 账号创建
- 代币转账