
# 请求处理
* Apache Kafka 自定义了一组请求协议
* 所有请求都是通过 TCP 以 Socket 的方式通讯
Kafka Broker 处理请求的全流程
* 顺序处理请求
``` Java
while (true) {
Request request = accept(connection);
handle(request);
}
```
* 缺陷:吞吐太差
---
* 每个请求使用单独线程处理
``` Java
while (true) {
Request = request = accept(connection);
Thread thread = new Thread(() -> {
handle(request);});
thread.start();
}
```
* 优点:吞吐大
* 缺点:资源开销大
* 适合请求发送频率低的场景
---
* Kafka 使用 Reactor 模式
Reactor 模式
* Reactor 模式是事件驱动架构的一种实现方式
* 适合应用于处理多个客户端并发向服务器端发送请求的场景
* 参考:[http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf](http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf)
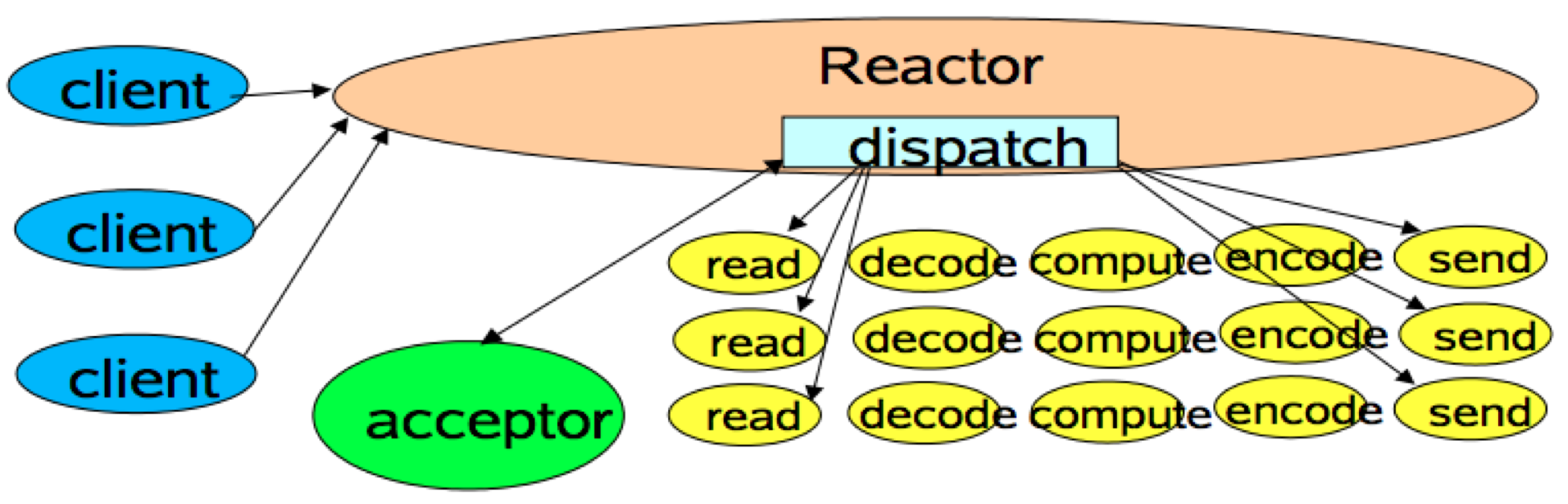
* 多个 Clients 发送请求到 Reactor
* Reactor 的请求分发线程 Dispatcher,i.e. Acceptor 将不同的请求下发到多个 worker 线程中
* Acceptor 只涉及分发,因此有很高的吞吐
* Worker 线程根据业务需求可以任意增减,动态调节系统负载能力
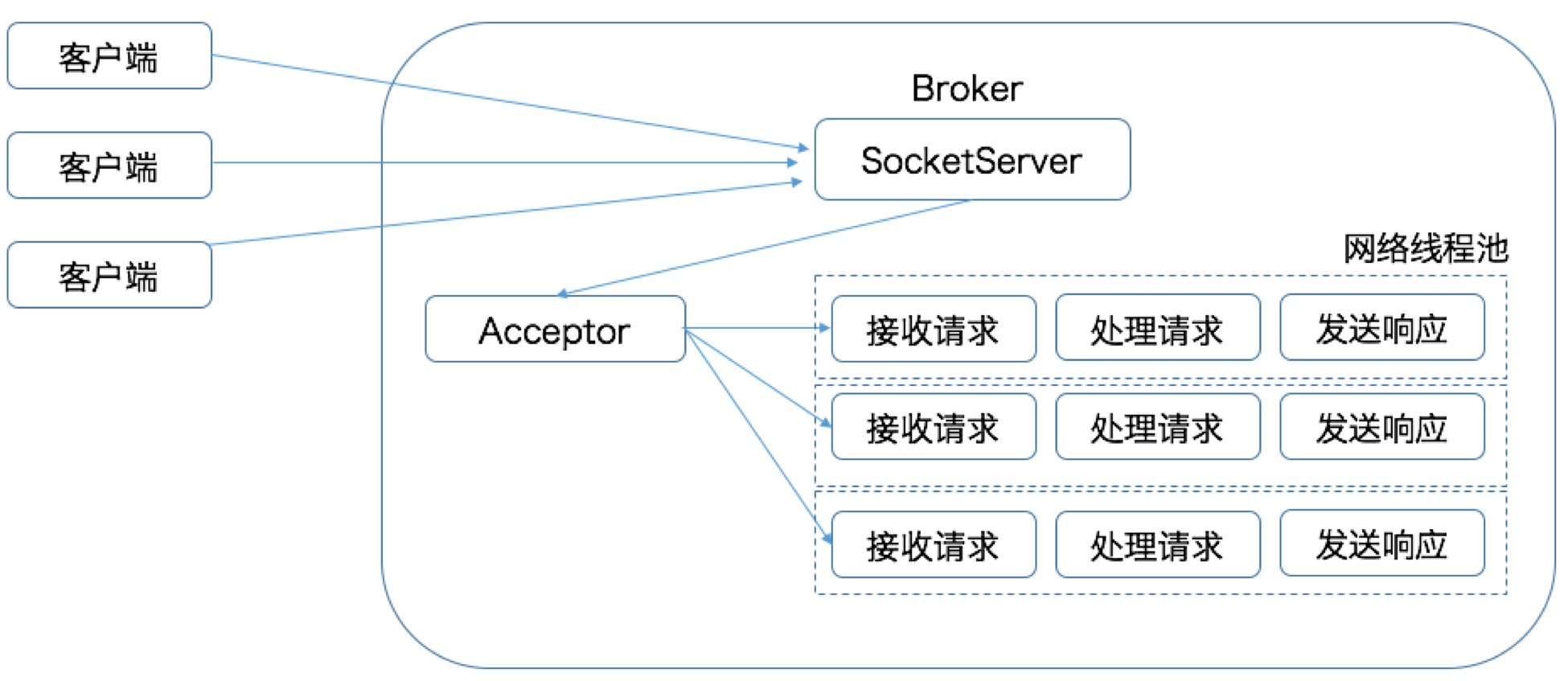
* Kafka Broker 端参数 `num.network.threads` 调整网络线程池的线程数,默认为 3
* Acceptor 线程通过轮询方式将入站请求公平的发送到所有网络线程中
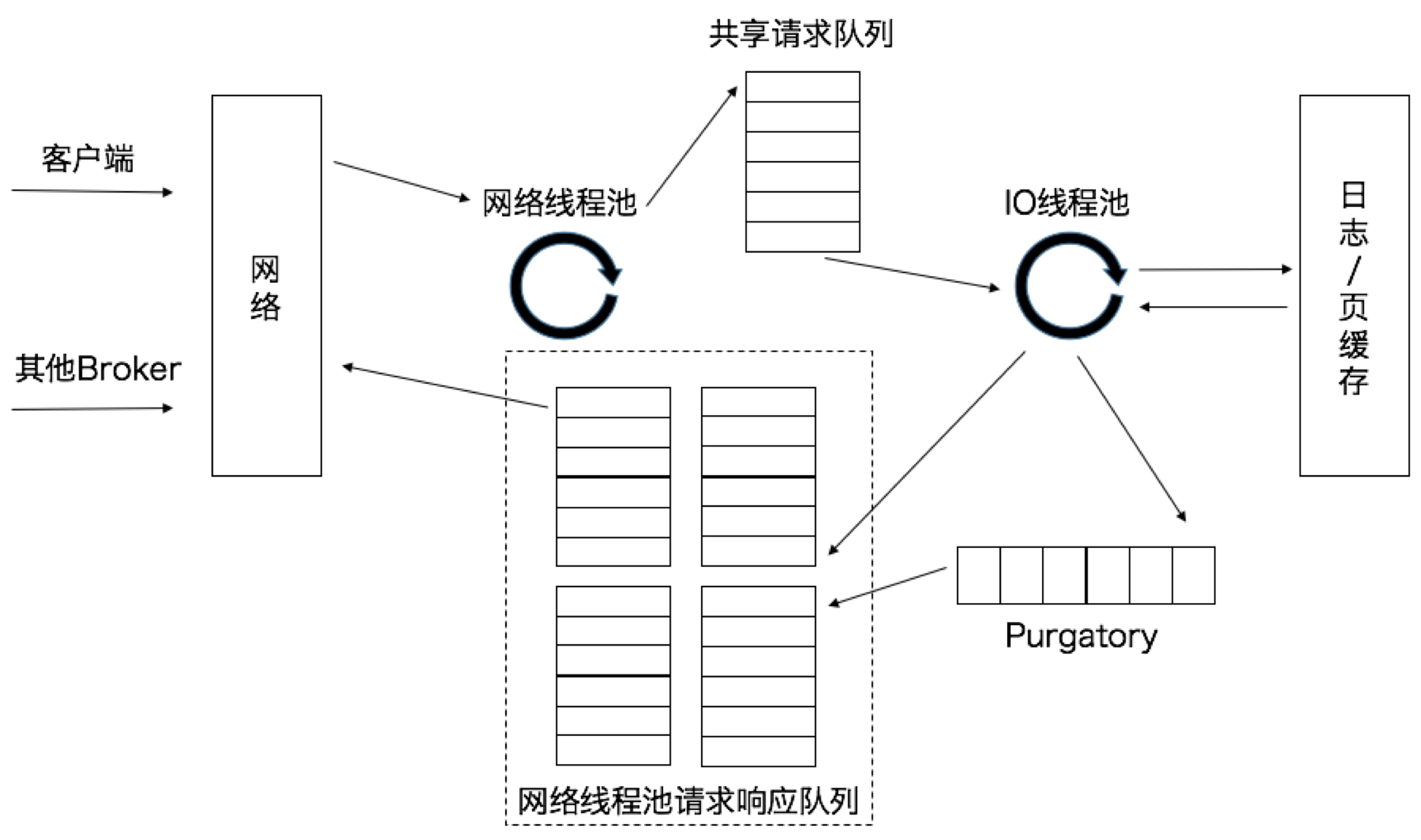
* 当网络线程拿到请求后,不是自己处理,而是放到一个共享请求队列中
* Broker 端 IO 线程池负责从该队列中取出请求,执行真正处理
* 如果是 Produce 请求,将消息写入到底层的磁盘日志中
* 如果是 Fetch 请求,则从磁盘或页缓存中读取消息
* IO 线程池中的线程是执行请求逻辑的真正线程
* Broker 端参数 `num.io.threads` 控制了该线程池中的线程数,默认值为 8
* IO 线程处理完后,将 response 发送到网络线程池的响应队列中
* 由对应的网络线程负责将 response 返回给 client
* 请求队列是所有网络线程共享,响应队列是专属的
Purgatory 组件
* 职责:缓存延时请求(Delayed Request)
* 延时请求:一时未能满足条件不能立刻处理的请求
* e.g. acks=all 的 Produce 请求 需要等待 ISR 中所有的副本都接收了消息才能返回,此时处理该请求的 IO 线程必须等其他 Broker 写入结果
请求分类
* 数据类请求:Produce、Fetch 这类请求
* 控制类请求:LeaderAndLsr、StopReplica
- 概览
- 入门
- 1. 消息引擎系统
- 2. Kafka 术语
- 3. 分布式流处理平台
- 4. Kafka “发行版”
- 5. Kafka 版本号
- 基本使用
- 6. 生产集群部署
- 7. 集群参数配置
- 客户端实践与原理
- 9. Consumer 分区机制
- 10. Consumer 压缩算法
- 11. 无消息丢失配置
- 12. 客户端高级功能
- 13. Producer 管理 TCP
- 14. 幂等生产者和事务生产者
- 15. 消费者组
- 16. 位移主题
- 17. 消费者组重平衡(TODO)
- 18. 位移提交
- 19. CommitFailedException
- 20. 多线程开发者实例
- 21. Consumer 管理 TCP
- 22. 消费者组消费进度监控
- Kafka 内核
- 23. 副本机制
- 24. 请求处理
- 25. Rebalance 全流程
- 26. Kafka 控制器
- 27. 高水位和 Leader Epoch
- 管理与监控
- 28. Topic 管理
- 29. Kafka 动态配置
- 30. 重设消费者组位移
- 31. 工具脚本
- 32. KafkaAdminClient
- 33. 认证机制
- 34. 云下授权
- 35. 跨集群备份 MirrorMaker
- 36. 监控 Kafka
- 37. Kafka 监控框架
- 38. 调优 Kafka
- 39. 实时日志流处理平台
- 流处理
- 40. Kafka Streams
- 41. Kafka Streams DSL
- 42. Kafka Streams 金融
- Q&A