> 本课是"Google ML速成课程"-"概念"的笔记。
> 旨在对ML的基本概念有个**快速了解**,第一遍学习时,理解不透彻没有关系,可以在以后的学习过程中经常回头。
> [课程链接](https://developers.google.cn/machine-learning/crash-course/ml-intro)
> [术语库](https://developers.google.cn/machine-learning/crash-course/glossary)
> 本课学习时长评估:12~24个小时。
> 针对速成课程,略过我的笔记,直接学习以上课程链接。
## 问题构建 (Framing)
监督式学习、非监督式学习
标签:Label
特征:Feature
样本:有标签样本(labeled example)、无标签样本(unlabeled example)
模型:Model,模型定义了特征与标签之间的关系
训练:Training,是指创建或学习模型
推断:Inference,是指将训练后的模型应用于无标签样本
回归:Regression,回归模型可预测连续值,比如房价、概率
分类:Classifier,分类模型可预测离散值,比如是否垃圾邮件、图像是狗、猫还是老鼠
## 线性回归(Linear Regression)
经验风险最小化:检查多个样本并尝试找出可最大限度地减少损失的模型,这一过程称为“经验风险最小化”。
损失:损失是对糟糕预测的惩罚。损失是一个数值,完全准确,损失为0。
训练模型的目标是从所有样本中找到一组平均损失“较小”的权重和变差。
平方损失:一种常见的损失函数,又称L2损失。
均方误差(MSE):指的是每个样本的平均平方损失。

## 降低损失(Reducing Loss)
迭代(Iterations)方法降低损失。通常,您可以不断迭代,直到总体损失不再变化或至少变化极其缓慢为止。这时候,我们可以说该模型已收敛。
通过计算整个数据集中 每个可能值的损失函数来找到收敛点这种方法效率太低。
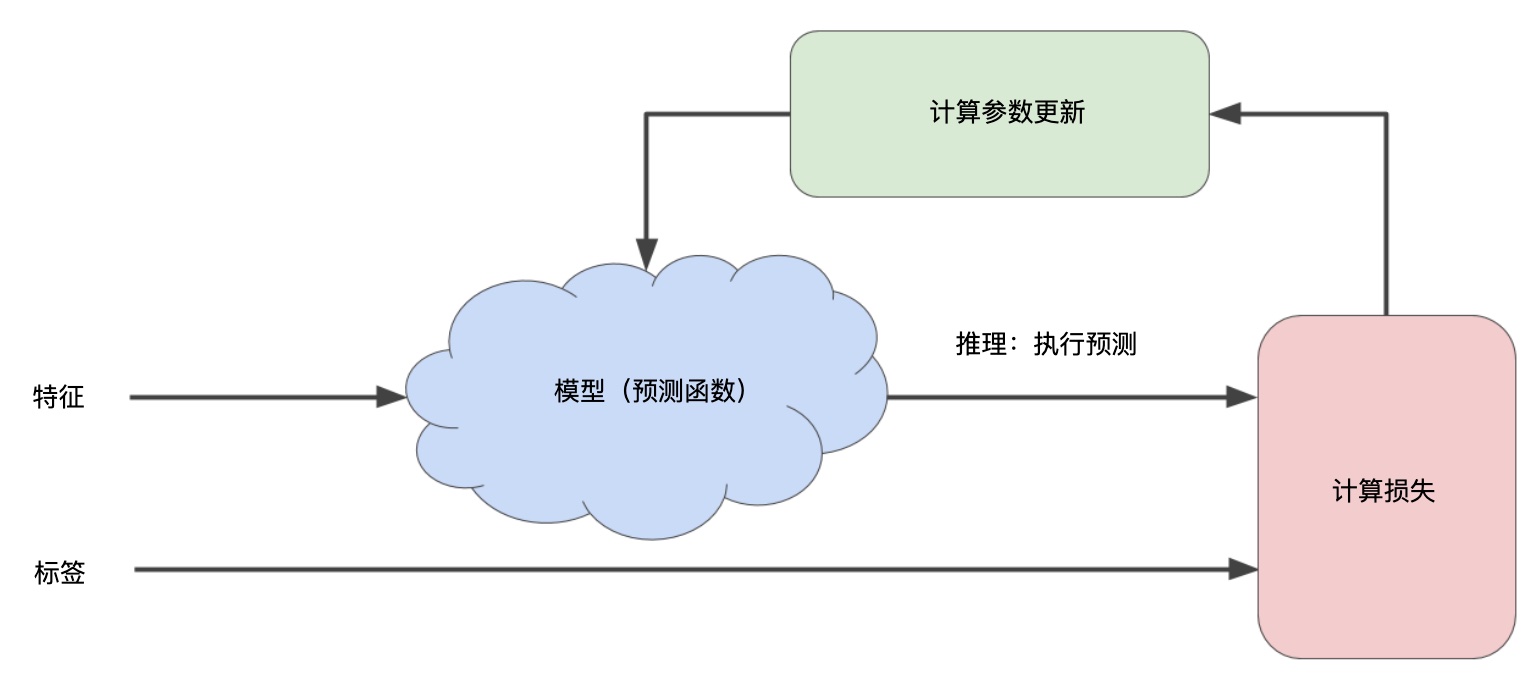
对于我们一直在研究的回归问题,损失函数是凸函数,可以用梯度下降法降低损失。梯度是偏导数的矢量。导数是函数的变化速度。
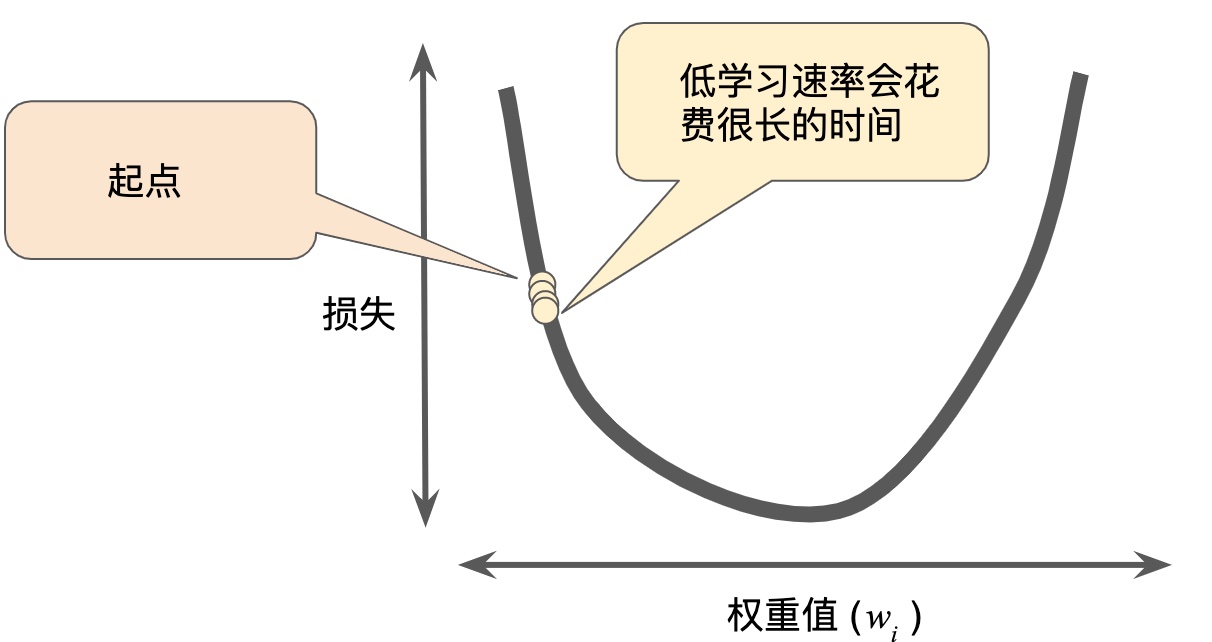
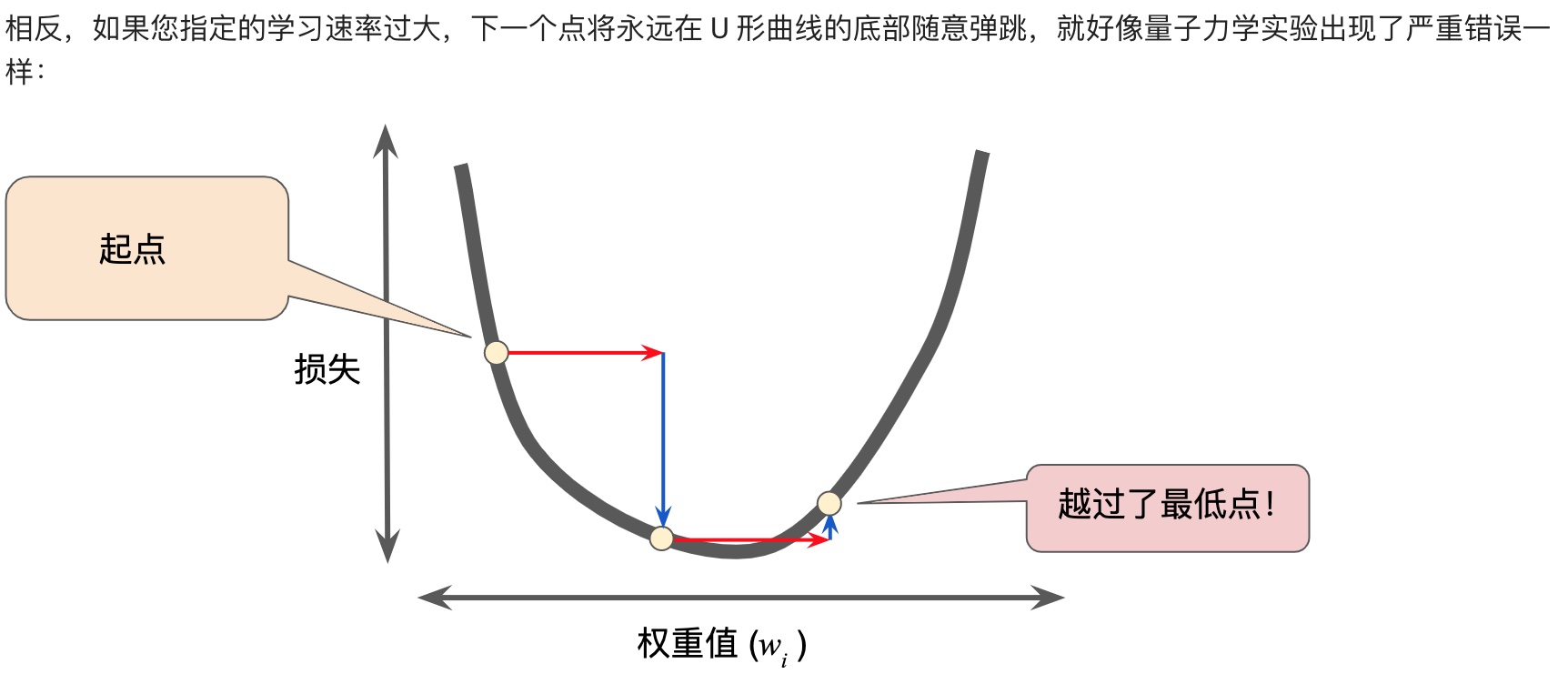
梯度下降法,用梯度乘以一个称为学习速率(有时也称为步长)的标量,以确定下一个点的位置。
超参数是编程人员在机器学习算法中用于调整的旋钮。步长就是超参数。步长选择太大太小都会有问题。
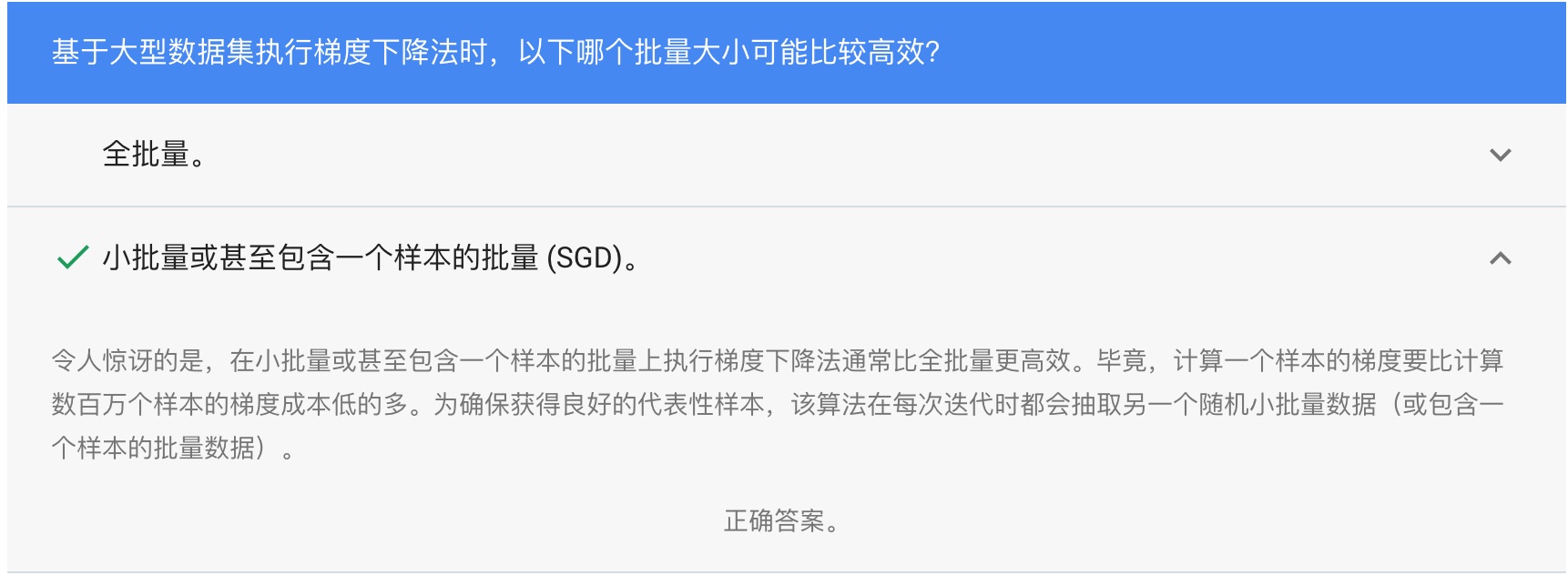
## 随机梯度下降(stochastic gradient descent)
****这块要理解一下,因为损失函数是凸函数,横坐标是权重,纵坐标是损失,而损失是在一个批量(可以是总数据集、小批量、单个样本)上,按照某种算法(比如就用均方误差:MSE)计算出来的。****
**所以,批量越大,计算越慢,一个批量就用一个样本,每次迭代最快。**
SGD、小批量SGD。

## 使用TF的基本步骤
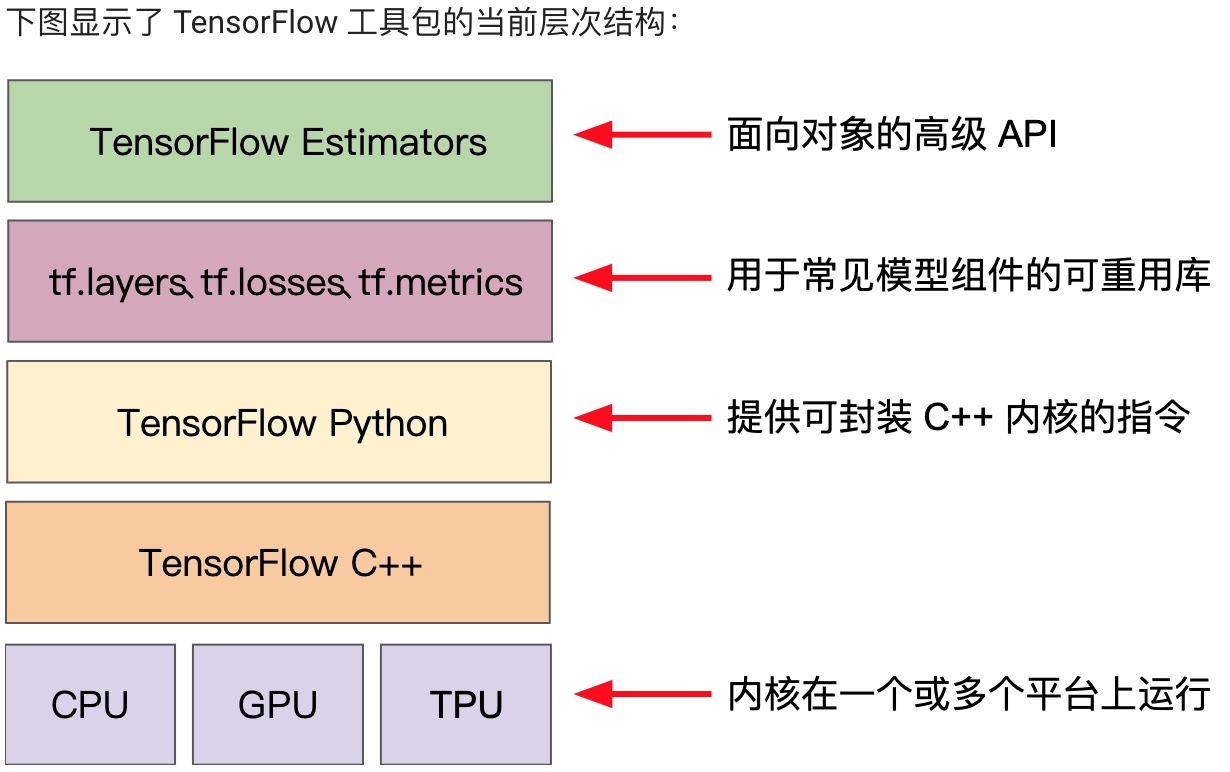
安装jupyter notebook,学习:intro\_to\_pandas、线性回归、合成特征以及输入离群值带来的影响,这3个练习。
关于jupyter的安装,可以按照google介绍的pip方式。
我是使用机器学习特训营介绍的anaconda方式:
1、下载安装anaconda;
2、source ~/.bash\_profile 或者重启,让anaconda增加的环境变量生效
3、conda install jupyter notebook
**第一个练习:Pandas**
Pandas是用于数据分析和建模的重要库,可以进行数据存取/加载/修改/reindex/绘图等,很多学习框架都支持将pandas数据结构作为输入。

**第二个练习:first\_steps\_with\_tensor\_flow**
演示一个用LinearRegressor构建模型,进行预测的完整例子。
完整代码包含:
* 定义并配置特征列
* 定义目标
* 配置LinearRegressor及其超参数
* 定义输入函数
* 训练模型
* 评估模型
然后练习调整模型超参数,以及尝试使用其他feature进行预测。
**第三个练习:synthetic\_features\_and\_outliers**
合成特征以及输入离群值带来的影响
## 泛化 (Generalization)
泛化是指模型很好地拟合以前未见过的新数据(从用于创建该模型的同一分布中抽取)的能力。
过拟合是由于模型的复杂程度超出所需程度而造成的。机器学习的基本冲突是适当拟合我们的数据,但也要尽可能简单地拟合数据。
**奥卡姆剃刀定律:**
机器学习模型越简单,良好的实证结果就越有可能不仅仅基于样本的特性。
现今,我们已将奥卡姆剃刀定律正式应用于统计学习理论和计算学习理论领域。
虽然理论分析在理想化假设下可提供正式保证,但在实践中却很难应用。机器学习速成课程则侧重于实证评估,以评判模型泛化到新数据的能力。
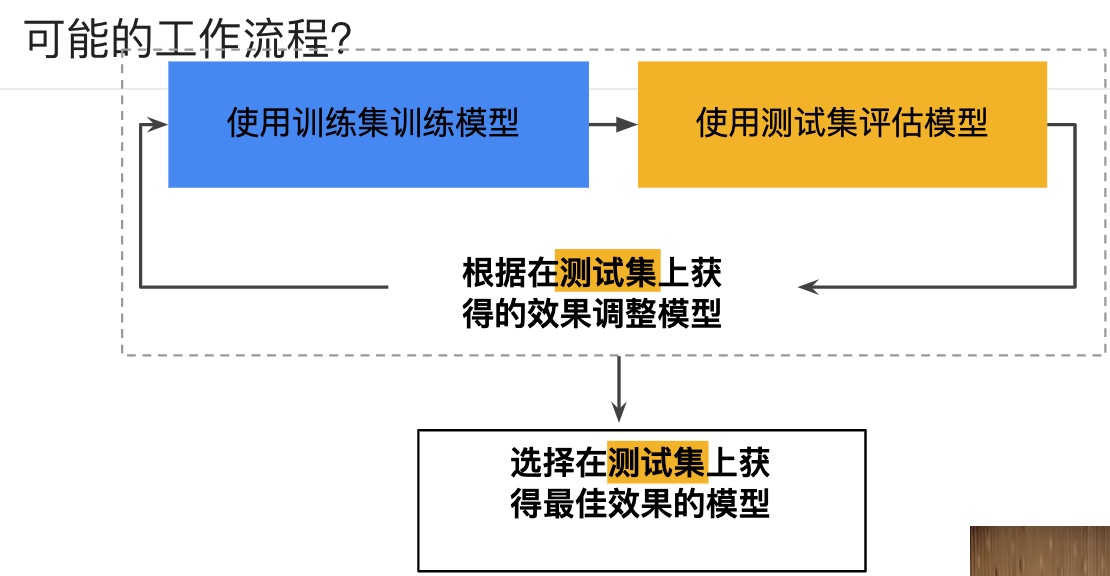
一种方法是将您的数据集分成两个子集:训练集、测试集。
一般来说,在测试集上表现是否良好是衡量能否在新数据上表现良好的有用指标,前提是:
1、测试集足够大。
2、您不会反复使用相同的测试集来作假。
## 训练集和测试集
练习:拆分训练集和测试集,调整学习速率,调整批次大小
## 验证(Validation)
多次重复执行训练流程可能导致我们不知不觉地拟合我们的特定测试集的特性。当进行多轮超参数调整时,仅使用两类数据可能不太够。
更好的方法,增加验证集:
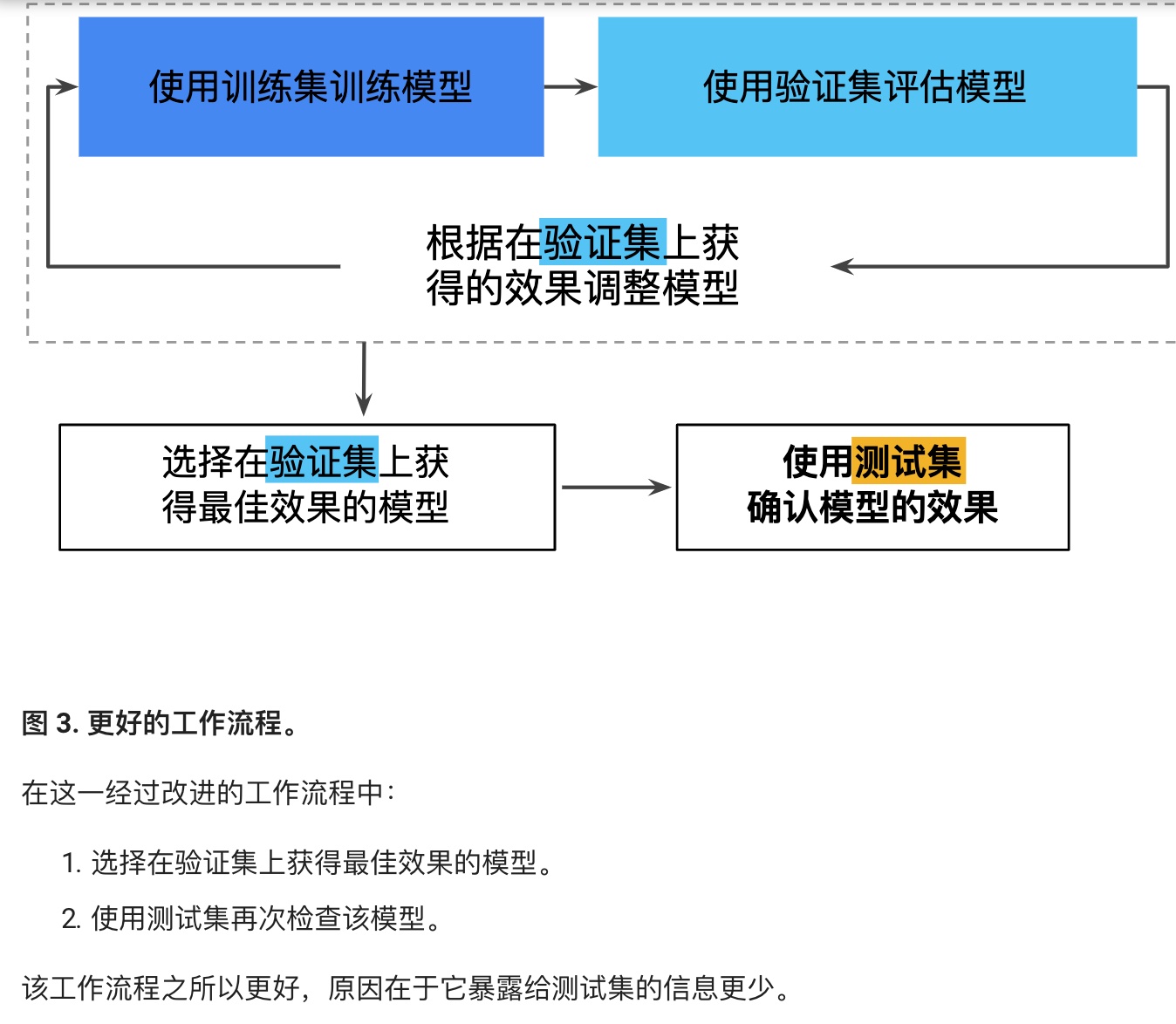
实际生产中,可能采用更多验证集,更多测试集。
课后练习:Validation.ipynb
## 表示 (Representation):特征工程
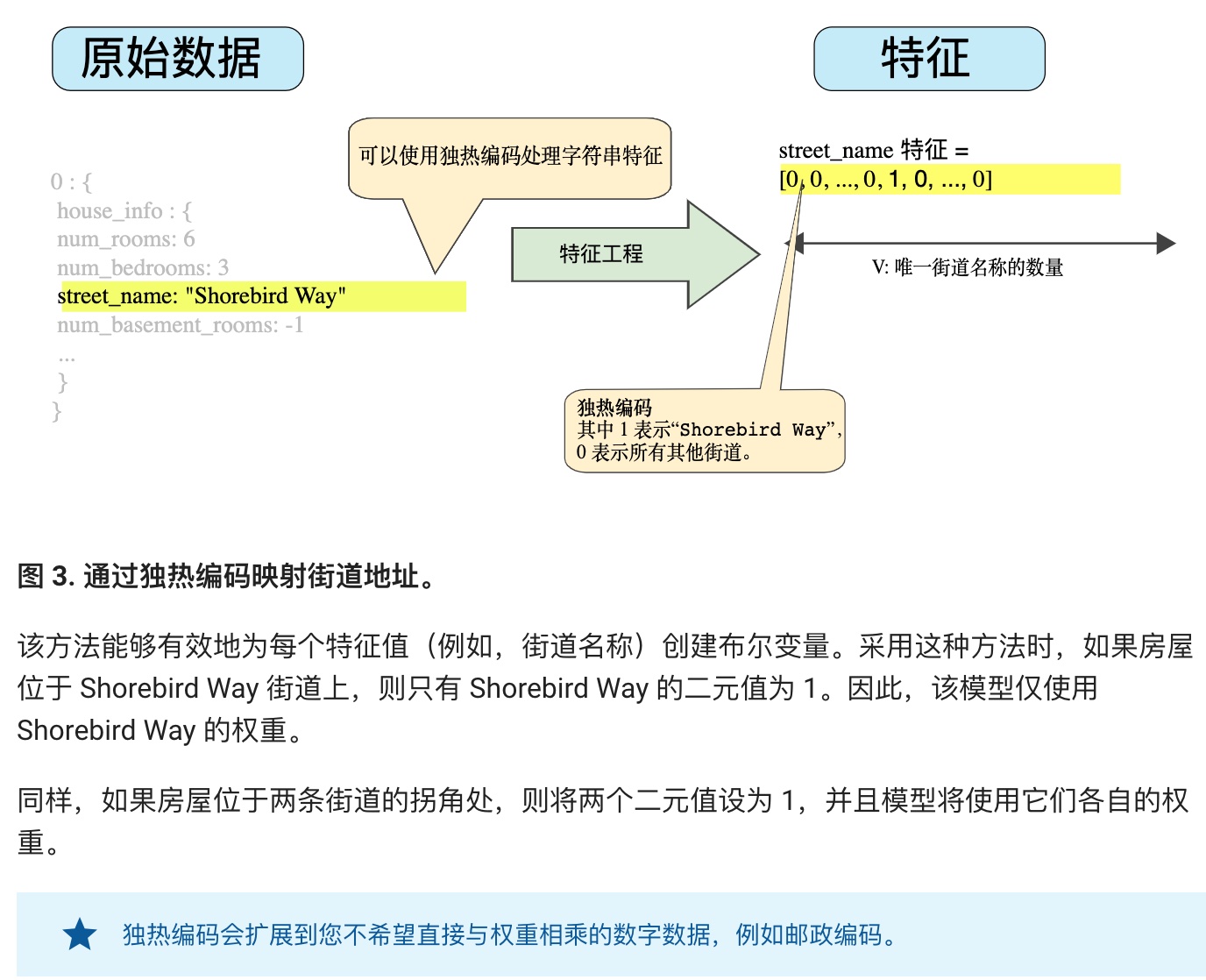
特征工程指的是将原始数据转换为特征矢量。进行特征工程预计需要大量时间。
许多机器学习模型都必须将特征表示为实数向量,因为特征值必须与模型权重相乘。
**字符型特征的处理:通过独热编码进行映射。**

**良好特征的特点:**
* 避免很少使用的离散特征值。至少出现5次以上,比如ID就不适合做特征,学习不到任何规律。
* 具有清晰明细的含义。user\_age:27 is ok. user\_age:32234 and user\_age:277 is not ok.
* 实际数据内不要掺入特殊值。比如一个特征具有0~1的浮点数。如果有默认值-1,则需要解决。
* 考虑上游的不稳定性。
**清理数据:**
作为一名机器学习工程师,您将花费大量的时间挑出坏样本并加工可以挽救的样本。
比如:缩放特征值、处理极端集群值、分箱、清查。


**处理极端集群值:**
* 一种办法是取对数
* 或者限制最大值,超过的都是最大值。
分箱:比如经纬度这种数字和房价没有线性关系,我们可以分箱称若干个分类。百分比分箱和分位数分箱。分位数分箱无需担心离群值。
清查:遗漏值、重复样本、不良标签、不良特征值。

## 特征组合 (Feature Crosses)
Synthetic feature or feature cross
**对非线性规律进行编码:**

**组合独热矢量:**



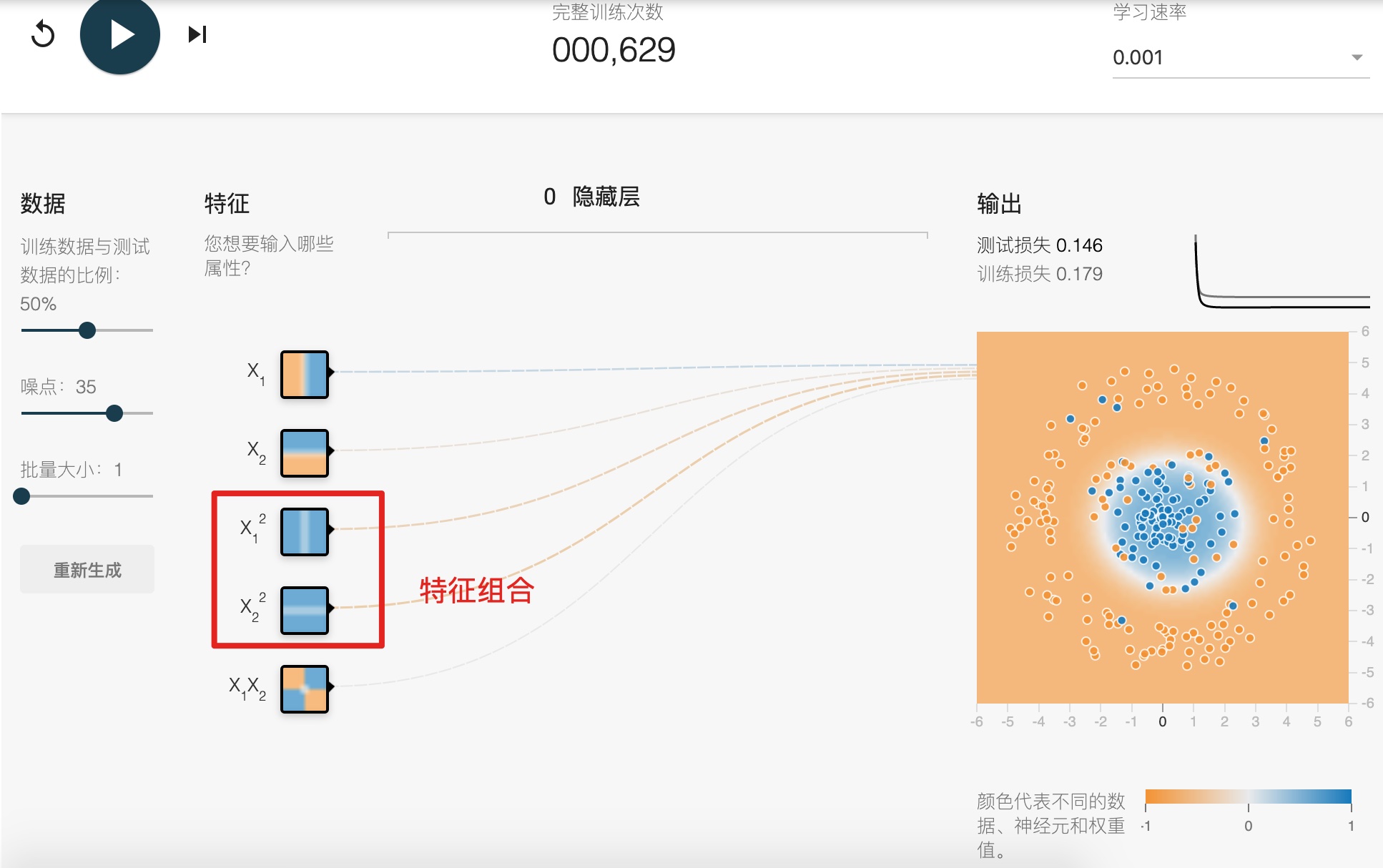

**一定要看这个代码演示:feature\_crosses.ipynb**
## 正则化:简单性(Regularization of simplicty)
**组合过度:**

**L2正则化:**

**Lambda:**

**我们可以了解到,训练模型的目标有二:拟合度高,复杂度小。**
## 逻辑回归(Logistic Regression)

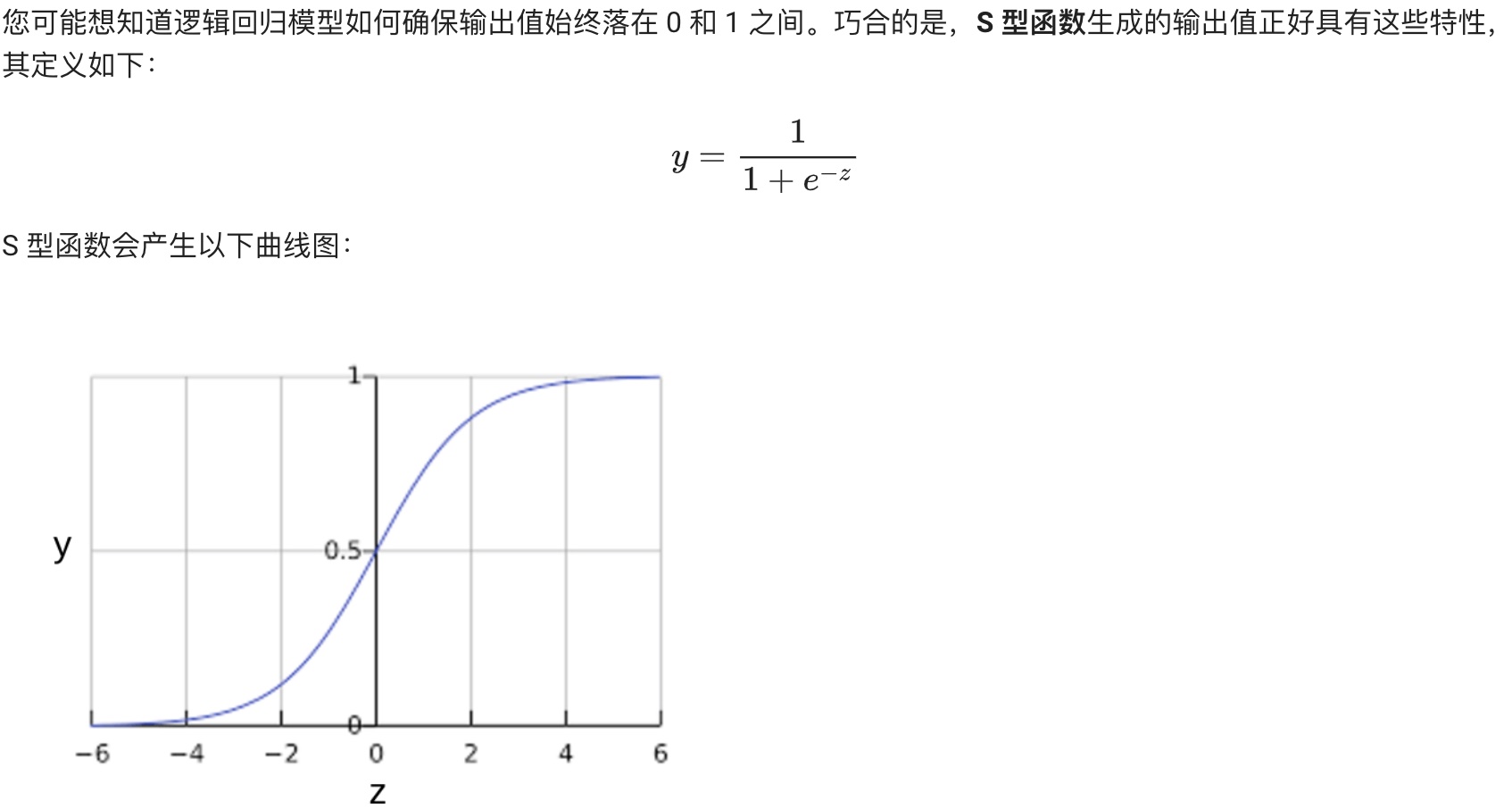
**逻辑回归的损失函数:对数损失:**

**逻辑回归中的正则化:**

**总结:**

## 分类(Classfication)
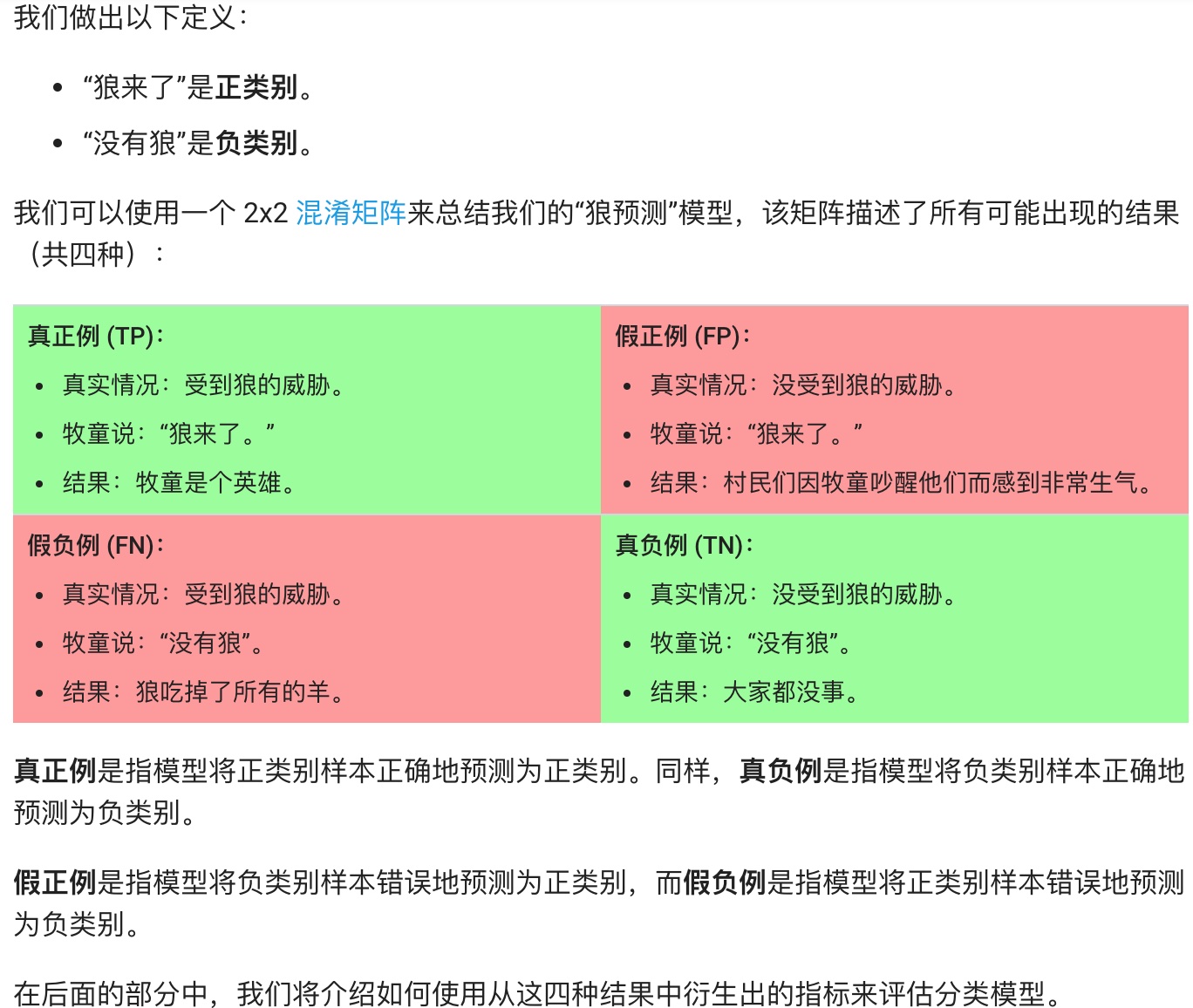
**准确率(Accuracy):**

当数据不平衡时呢,比如虽然准确率很高,但是9个恶性肿瘤只预测了一个。

**精确率(Precision):**

**召回率(Recall):**

**Precision&Recall总结:**

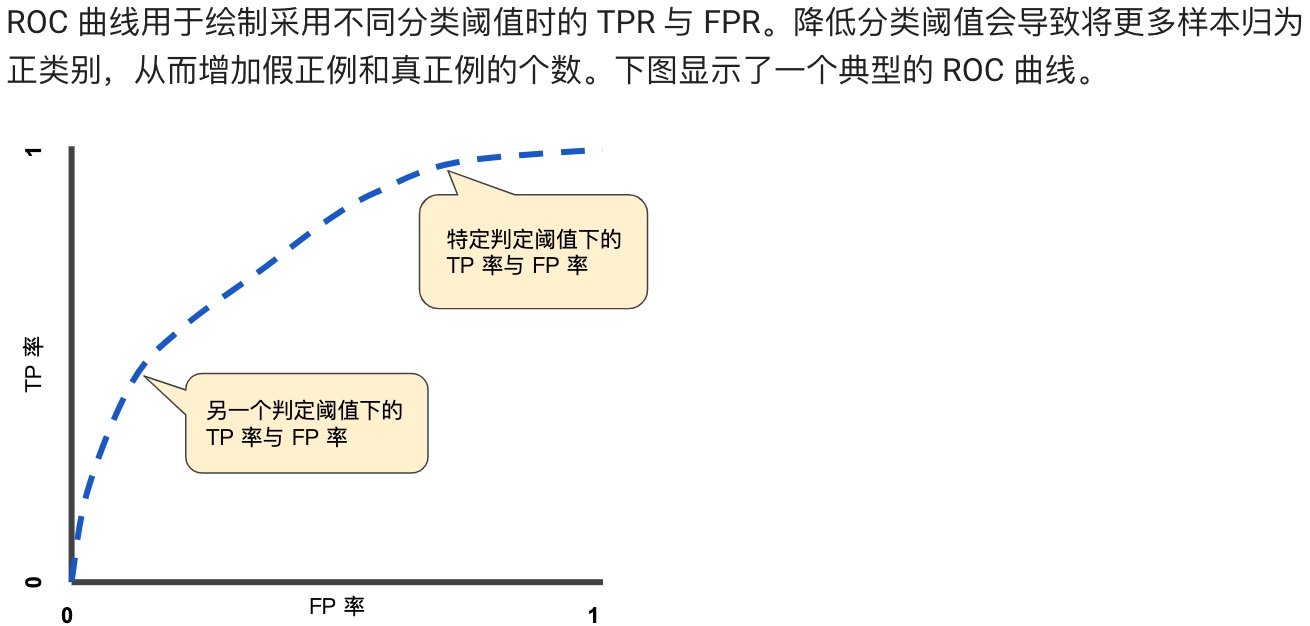
**ROC 曲线(接收者操作特征曲线)是一种显示分类模型在所有分类阈值下的效果的图表。**
**预测偏差:**

## 正则化:稀疏性(Regularization of sparsity)
临时跳过。。。
## 神经网络简介(Neural network)
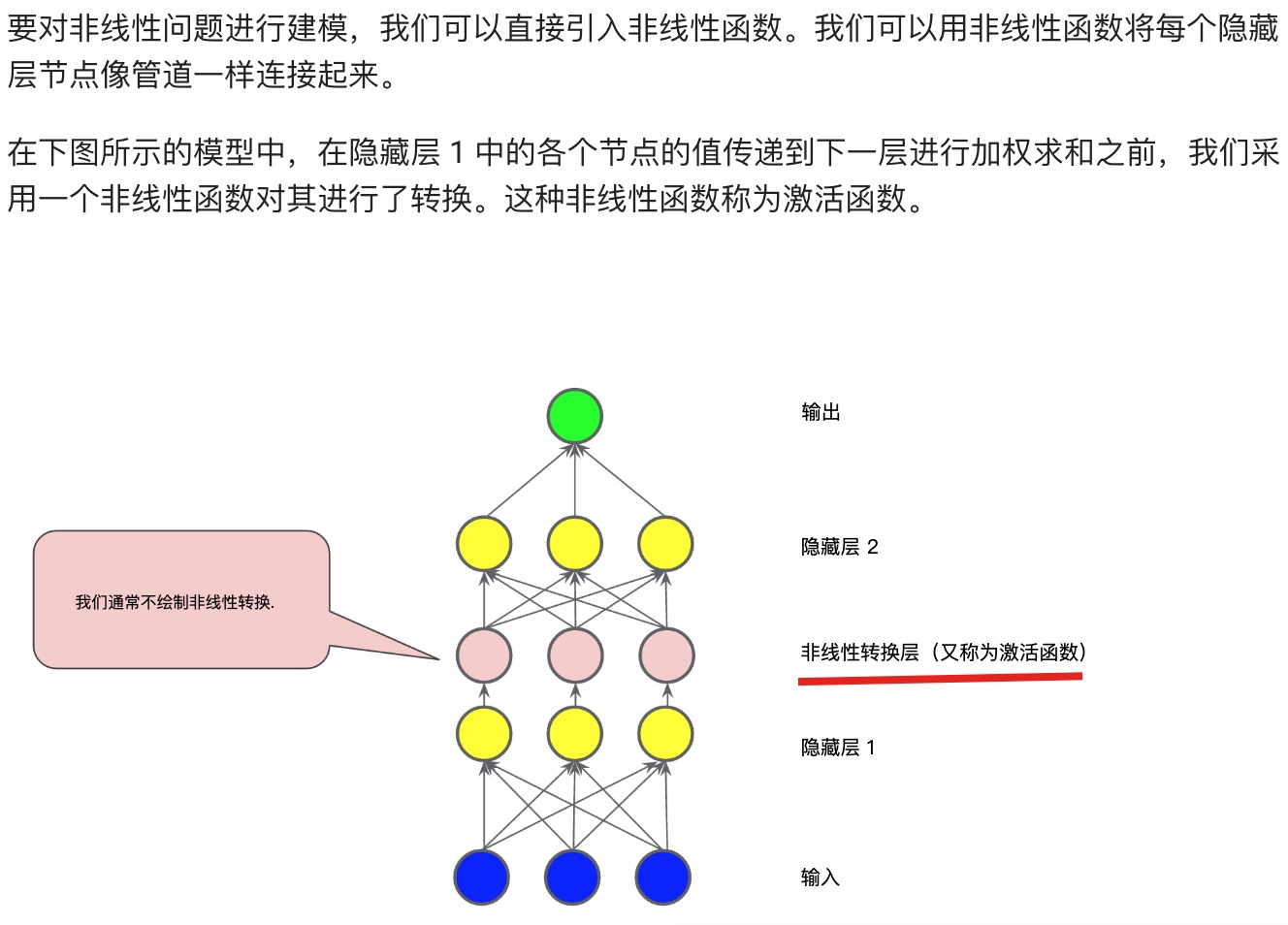
**常见的激活函数:S型函数、ReLU(修正线性单元)函数。**

## 训练神经网络(Training Neural Networks)
back propagation:反向传播。dropout:丢弃。

关于反向传播,有以下重要的事情需要了解:



## 多类别神经网络
临时跳过。。。
## 嵌套 (Embedding)
临时跳过。。。
