
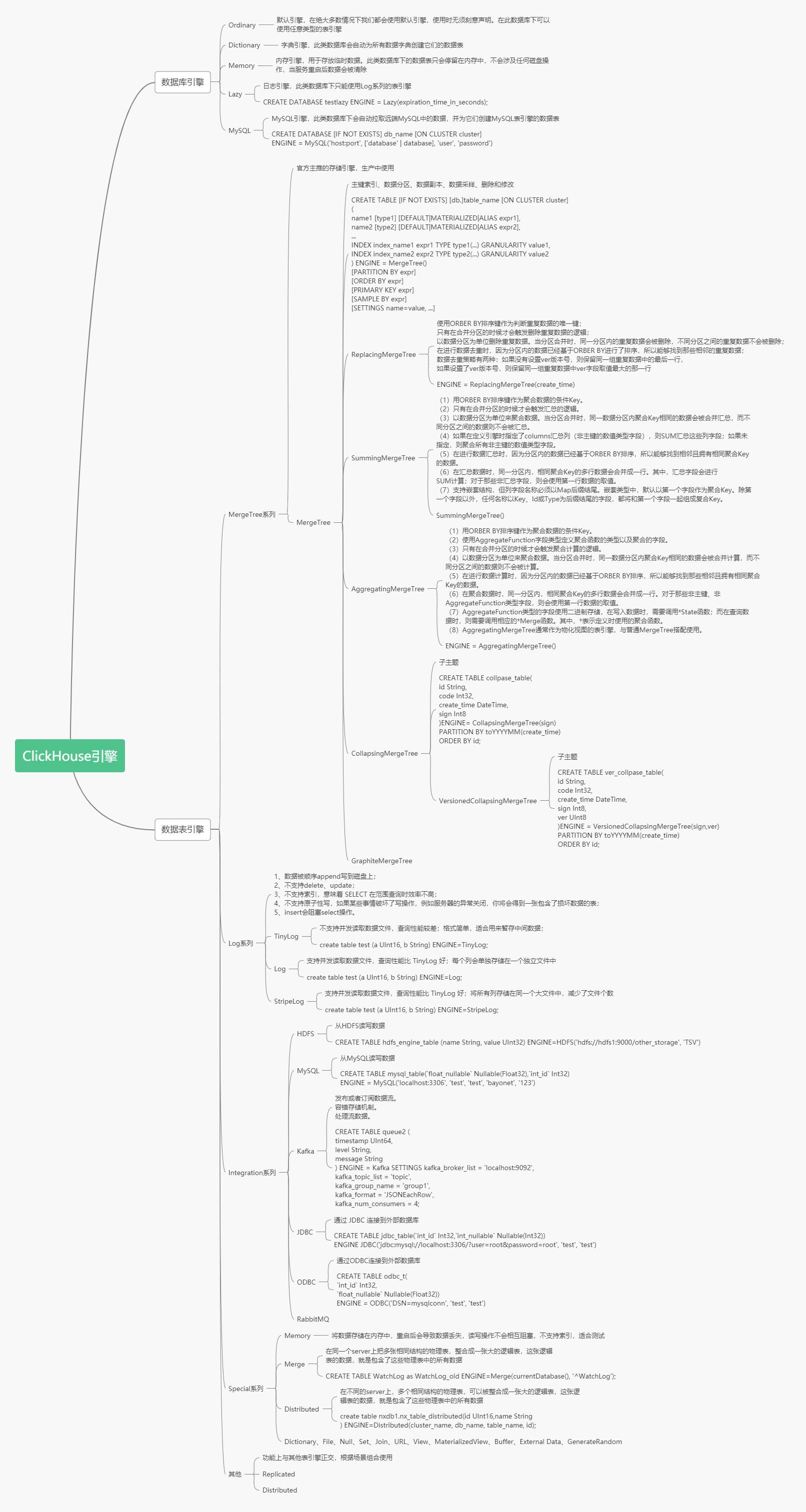
# ClickHouse引擎
数据库引擎默认是Ordinary,在这种数据库下面的表可以是任意类型引擎。
表引擎是ClickHouse设计实现中的一大特色 ,数据表拥有何种特性、数据以何种形式被存储以及如何被加载。ClickHouse拥有非常庞大的表引擎体系。
生产环境中常用的表引擎是MergeTree系列,也是官方主推的引擎。MergeTree是基础引擎,有主键索引、数据分区、数据副本、数据采样、删除和修改等功能,ReplacingMergeTree有了去重功能,SummingMergeTree有了汇总求和功能,AggregatingMergeTree有聚合功能,CollapsingMergeTree有折叠删除功能,VersionedCollapsingMergeTree有版本折叠功能,GraphiteMergeTree有压缩汇总功能。在这些的基础上还可以叠加Replicated和Distributed。
Integration系列用于集成外部的数据源,常用的有HADOOP,MySQL。
## 数据库引擎
## 表引擎
### Memory引擎
读写操作不会相互阻塞。不支持索引。查询是并行化的。在简单查询上达到最大速率(超过10 GB /秒),因为没有磁盘读取,不需要解压缩或反序列化数据。(值得注意的是,在许多情况下,与 MergeTree 引擎的性能几乎一样高)。重新启动服务器时,表中的数据消失,表将变为空。通常,使用此表引擎是不合理的。但是,它可用于测试。
### LOG引擎系列
#### Log系列表引擎的特点
#### 共性特点
* 数据存储在磁盘上
* 当写数据时,将数据追加到文件的末尾
* 不支持**并发读写**,当向表中写入数据时,针对这张表的查询会被阻塞,直至写入动作结束
* 不支持索引
* 不支持原子写:如果某些操作(异常的服务器关闭)中断了写操作,则可能会获得带有损坏数据的表
* 不支持**ALTER操作**(这些操作会修改表设置或数据,比如delete、update等等)
#### 区别
* **TinyLog**
TinyLog是Log系列引擎中功能简单、性能较低的引擎。它的存储结构由数据文件和元数据两部分组成。其中,**数据文件是按列独立存储的,也就是说每一个列字段都对应一个文件**。除此之外,TinyLog不支持并发数据读取。
* **StripLog**支持并发读取数据文件,当读取数据时,ClickHouse会使用多线程进行读取,每个线程处理一个单独的数据块。另外,**StripLog将所有列数据存储在同一个文件中**,减少了文件的使用数量。
* **Log**支持并发读取数据文件,当读取数据时,ClickHouse会使用多线程进行读取,每个线程处理一个单独的数据块。**Log引擎会将每个列数据单独存储在一个独立文件中**。\*\*\*\*
| 引擎 | 存储文件数 | 并行查询 | 效率 | mark文件 | 适用场景 |
| --- | --- | --- | --- | --- | --- |
| Log | 每列一个文件 | 支持 | 高 | 有 | 适用于临时数据,一次性写入、测试场景 |
| StripeLog | 所有列一个文件 | 支持 | 较高 | 有 | 在你需要写入许多小数据量(小于一百万行)的表的场景下使用这个引擎。 |
| TinyLog | 每列一个文件 | 不支持 | 低 | 无 | 适用于**一次写入,多次读取的场景**。对于处理小批数据的中间表可以使用该引擎。值得注意的是,使用大量的小表存储数据,性能会很低。 |
* * *
1)LOG引擎
日志与 TinyLog 的不同之处在于,标记的小文件与列文件存在一个文件夹里。这些标记在每个数据块上,并且包含偏移量,这些偏移量指示从哪里开始读取文件以便跳过指定的行数。这使得可以在多个线程中读取表数据。对于并发数据访问,可以同时执行读取操作,而写入操作则阻塞读取和其它写入。Log 引擎不支持索引。同样,如果写入表失败,则该表将被破坏,并且从该表读取将返回错误。
~~~
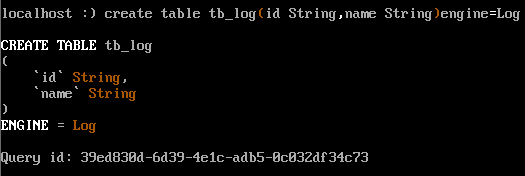
create table tb_log(id String,name String)engine=Log
~~~
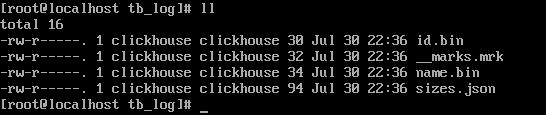
* 列.bin:数据文件,数据文件按列单独存储
* \_\_marks.mrk:数据标记,统一保存了数据在各个.bin文件中的位置信息。利用数据标记能够使用多个线程,以并行的方式读取。.bin内的压缩数据块,从而提升数据查询的性能。
* sizes.json:记录了.bin和\_\_marks.mrk大小的信息
每一次的INSERT操作,都会对应一个数据块
支持多线程处理
并发读写
* * *
2)TinyLog引擎
最简单的表引擎,用于将数据存储在磁盘上。每列都存储在单独的压缩文件中,写入时,数据将附加到文件末尾。该引擎没有并发控制。
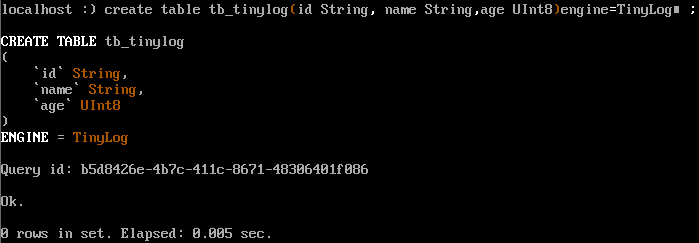
create table tb\_tinylog (
id String,
name String,
age UInt8
)engine=TinyLog;
插入数据,看存储的文件结构:
1、最简单的引擎
2、没有标记块
3、写入操作是追加写
4、数据以列字段文件存储
5、不允许同时读写
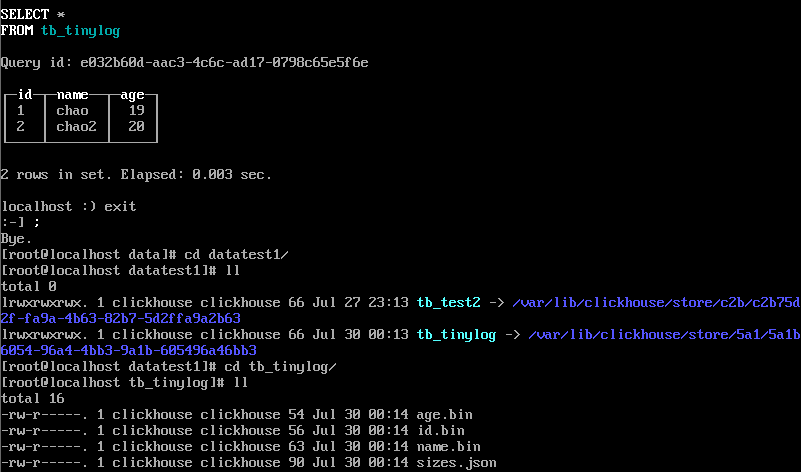
**如果操作写入失败,会损坏表结构,只能删除表,删除表需要删除data下的该表结构和metadata下的该表元数据**
* * *
3)StripeLog引擎
在你需要写入许多小数据量(小于一百万行)的表的场景下使用这个引擎。
~~~
create table test_stripelog( id UInt8 , name String , age UInt8)engine=StripeLog ;
~~~
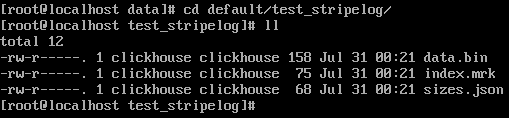
* data.bin:数据文件,所有的列字段使用同一个文件保存,它们的数据都会被写入data.bin。
* index.mrk:数据标记,保存了数据在data.bin文件中的位置信息(每个插入数据块对应列的offset),利用数据标记能够使用多个线程,以并行的方式读取data.bin内的压缩数据块,从而提升数据查询的性能。
* sizes.json:元数据文件,记录了data.bin和index.mrk大小的信息
每次的**INSERT**操作,ClickHouse会将**数据块**追加到表文件的末尾
### MergeTree引擎
在所有的表引擎中,最为核心的当属MergeTree系列表引擎,这些表引擎拥有最为强大的性能和最广泛的使用场合。对于非MergeTree系列的其他引擎而言,主要用于特殊用途,场景相对有限。而MergeTree系列表引擎是官方主推的存储引擎,支持几乎所有ClickHouse核心功能。
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来。
MergeTree作为家族系列最基础的表引擎,主要有以下特点:
* 存储的数据按照主键排序:允许创建稀疏索引,从而加快数据查询速度
* 支持分区,可以通过PRIMARY KEY语句指定分区字段。
* 支持数据副本
* 支持数据采样
* 在MergeTree中主键并不用于去重,而是用于索引,加快查询速度
* 创建表
~~~
create table tb_merge_tree(
uid UIn8,
name String,
birthday Date,
city String,
gender String
)engine =MergeTree()
primary key uid
order by (uid,birthday)
~~~
* 插入数据
~~~
insert into tb_merge_tree values(1,'南京',toDate(now()),'南京','男'),(1,'南京2',toDate('1996-7-25'),'南京','男')
insert into tb_merge_tree values(1,'南京3',toDate(now()),'南京','M'),(1,'南京4',toDate('1996-7-25'),'南京','M')
~~~

/var/lib/clickhouse/data/下数据文件
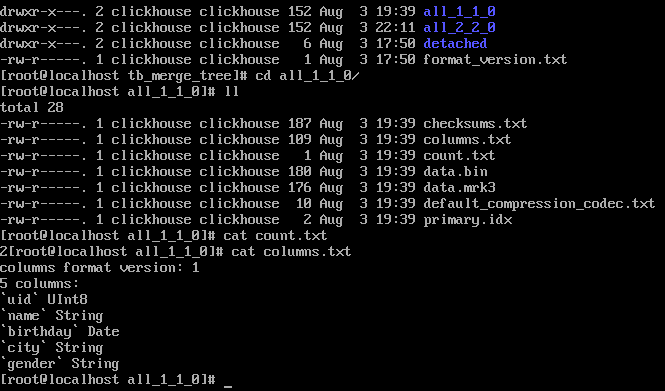
* 合并数据
~~~
optimize table tb_merge_tree final ;
~~~
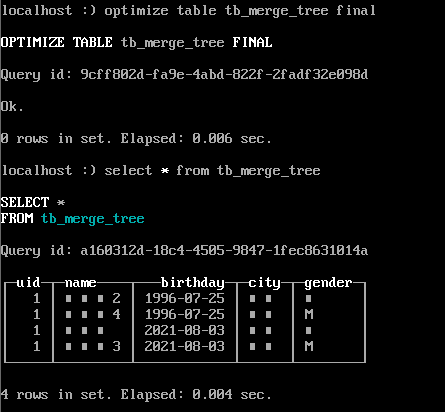
合并后/var/lib/clickhouse/data/下数据文件多出一个all\_1\_2\_1的文件夹,其中第一个数字代表最小版本,第二个数据代表最大的版本,第三个数字代表第几次合并。

### ReplacingMergeTree表引擎
上文提到**MergeTree**表引擎无法对相同主键的数据进行去重,ClickHouse提供了ReplacingMergeTree引擎,可以针对相同主键的数据进行去重,它能够在合并分区时删除重复的数据。值得注意的是,**ReplacingMergeTree**只是在一定程度上解决了数据重复问题,但是并不能完全保障数据不重复。
~~~
CREATETABLE emp_replacingmergetree (
emp_id UInt16 COMMENT'员工id',
nameStringCOMMENT'员工姓名',
work_place StringCOMMENT'工作地点',
age UInt8 COMMENT'员工年龄',
depart StringCOMMENT'部门',
salary Decimal32(2) COMMENT'工资'
)ENGINE=ReplacingMergeTree()
ORDERBY emp_id
PRIMARY KEY emp_id
PARTITIONBY work_place
;
-- 插入数据
INSERTINTO emp_replacingmergetree
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERTINTO emp_replacingmergetree
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
~~~
ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY
执行合并,相同主键的数据,保留最近插入的数据,旧的数据被清除
只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除
### SummingMergeTree表引擎
### Aggregatingmergetree表引擎
### CollapsingMergeTree表引擎
### VersionedCollapsingMergeTree表引擎
### GraphiteMergeTree表引擎
### 文件表引擎
数据源是以 Clickhouse 支持的一种输入格式(TabSeparated,Native等)存储数据的文件。
* 从 ClickHouse 导出数据到文件。
* 将数据从一种格式转换为另一种格式。
* 通过编辑磁盘上的文件来更新 ClickHouse 中的数据。
* TabSeparated格式
~~~
CREATE TABLE file_engine_table (name String, value UInt32) ENGINE=File(TabSeparated)
~~~
默认情况下,Clickhouse 会创建目录`/var/lib/clickhouse/data/default/file_engine_table`。
手动创建`/var/lib/clickhouse/data/default/file_engine_table/data.TabSeparated`文件,并且包含内容:
文件命名必须是data.TabSeparated
文件内容:
~~~
$ cat data.TabSeparated
one 1
two 2
~~~
* CSV格式
~~~
create table tb_file_demo2(uid UInt16,name String)engine=File(CSV)
~~~
在/var/lib/clickhouse/data/文件夹下创建data.CSV文件
~~~
vi data.CSV
11 aa
22 bb
~~~
* local语法
这种方式不会创建表,可以查询数据,并且表引擎只能是File
~~~
-- 0或stdin,1或stdout
cat user.CSV | clickhouse-local -q "create table tb_file3(id Int8,name String)engine=File(CSV,stdin)";
~~~

* client语法
~~~
可以指定任意表引擎
create table tb_client(id Uint8,name String)engine=TinyLog;
-- 导入数据
cat user.CSV | clickhouse-client -q "insert into tb_client FORMAT CSV"
-- 自定义分隔符--format_csv_delimiter,指定数据库-d
cat user.txt | clickhouse-client -q --format_csv_delimiter = '|' -d datatest1 'insert into tb_client FORMAT CSV'
~~~
表引擎参考文章:[https://my.oschina.net/maoxiang/blog/4617507](https://my.oschina.net/maoxiang/blog/4617507)
- ClickHouse
- 第一节 ClickHouse入门
- 1.1 ClickHouse概述
- 1.2 ClickHouse单机安装
- 1.3 ClickHouse配置
- 1.4 ClickHouse数据库引擎
- 1.5 ClickHouse集群部署
- 第二节 ClickHouse进阶
- 2.1 ClicKHouse数据类型
- 2.2 ClicKHouse基本语法
- 2.3 ClickHouse引擎
- 2.4 ClickHouse函数
- 2.5 ClickHouse分布式表
- 2.6 ClickHouse权限和密码加密
- 2.7 ClickHouse数据导入和导出
- 第三节 ClicKHouse实战篇
- 3.1 ClickHouse的JDBC连接
- 3.2 ClickHouse用户行为分析
- 3.3 ClickHouse实战
- 第四节 ClicKHouse常见问题
- 4.1 ClickHouse常见问题汇总
- 第五节 ClickHouse其他
- 5.1 ClickHouse可视化工具
- 5.2 ClickHouse学习教程