
## [126\. 单词接龙 II](https://leetcode-cn.com/problems/word-ladder-ii/)
>Hard
#### 思路
基于Hard必死原则,没有什么思路。罢了,阅读大佬文档获取思路。
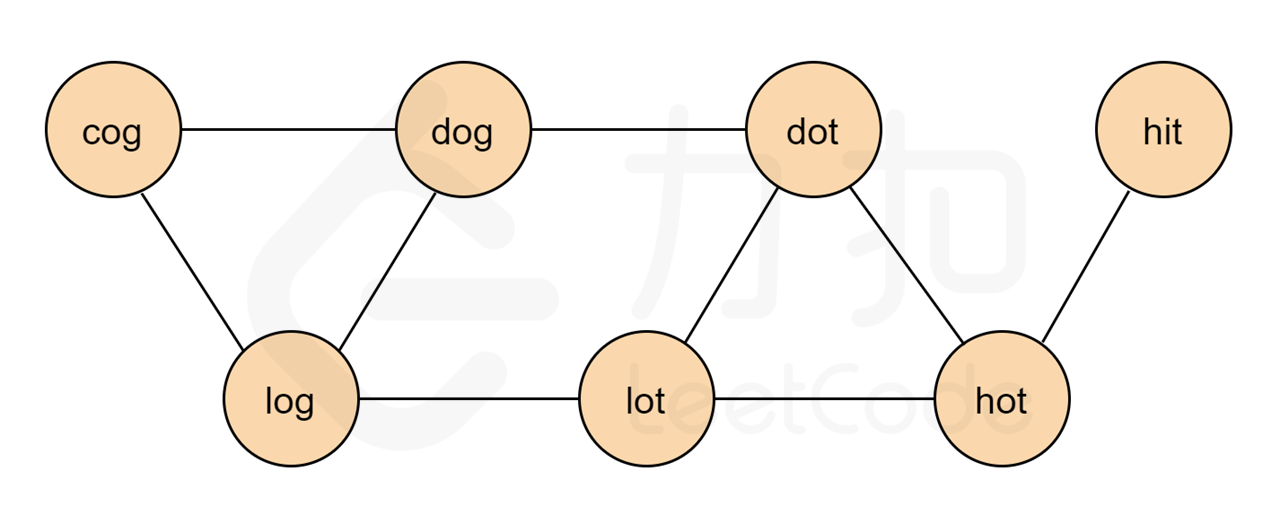
* 只有一个字母不同的单词,路组成相邻的节点
* 相邻的节点运动,就是每一步都变换一个字母
* beginWord 作为起点,endWord 作为终点
* 将beginWord 也加入到words中,作为无向图的一部分
* 假如endWord 不在途中最终无解
* 题目转换为从beginWord走到endWord的最短路径
如图:
**待解决的问题**:
1. 解决重复问题,`hit→hot→hit`避免产生这种情况,形成环不符合题意
2. 如何构造图,即如何找到一个单词的相邻节点
3. 如何记录路径,也就是说BFS结束之后,如何将对应的路径保存下来
> 问题1:使用一个`visited`数组来记录已经访问过的节点,在访问过程中,已经访问过的,不进行访问
> 问题2:遍历word的单词进行比较,不同字母数量超过1即为不相邻
> 问题3:我们可以在做BFS的过程中,不单单将当前节点推到队列中,也将父节点信息一起推到队列当中
**题目难点** 本题的难点在于怎么合理的构造图,两两建图复杂度太高,这边使用一个骚操作:使用通配符建表。相同通配符下的节点,都互相有边。(操作实在太骚,大佬脑洞真大)
尝试着写一下代码,TLE
#### 代码 (TLE)
python3
```
class Solution:
def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:
if endWord not in wordList:
return []
s = collections.defaultdict(list)
for w in wordList:
for i in range(len(w)):
s[w[:i] + '*' + w[i+1:]].append(w)
result = []
queue = []
queue.append([beginWord])
while len(queue) > 0:
cur_queue_size = len(queue)
found = False
for cur in range(cur_queue_size):
visited = set()
path = queue[0]
word = path[-1]
del queue[0]
for p in path:
visited.add(p)
for i in range(len(word)):
for c in s[word[:i] + '*' + word[i+1:]]:
if c not in visited:
if c == endWord:
found = True
result.append(path + [c])
queue.append(path + [c])
if found:
break
if not len(result):
return []
return result
```
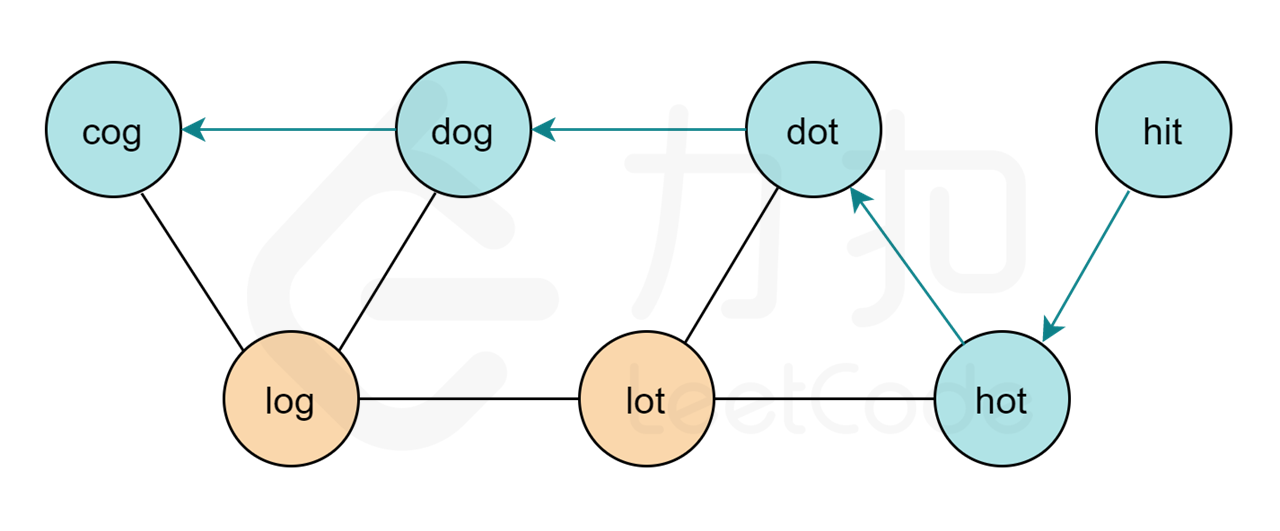
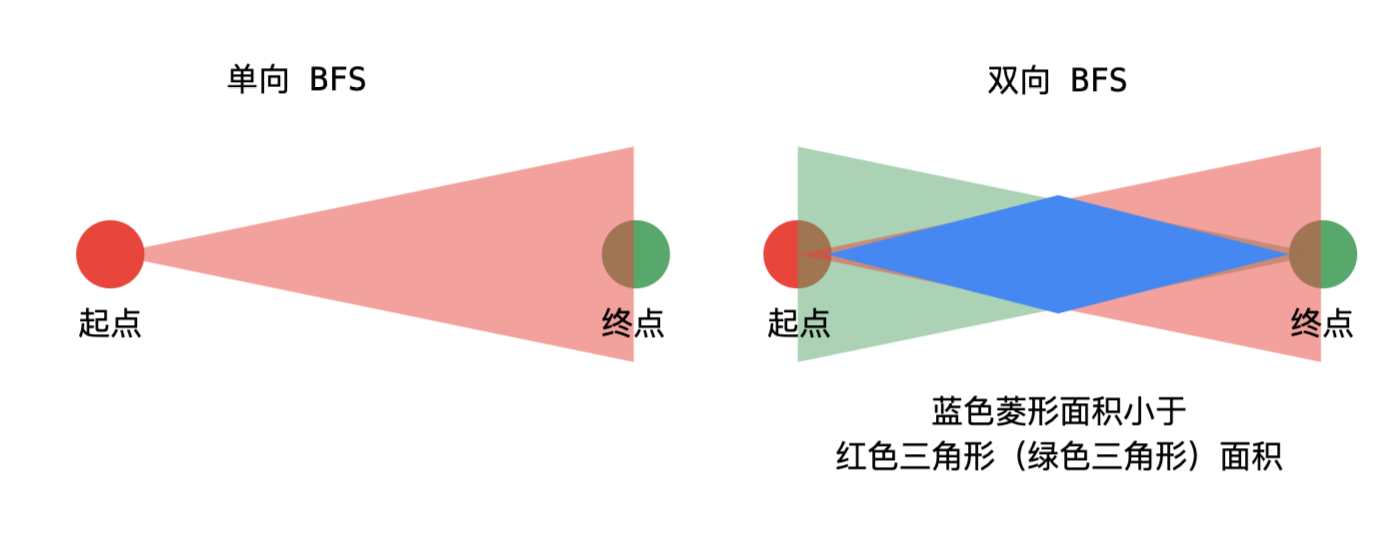
**改进代码** 再次拜读大佬解法,获取新思路:使用双向广度优先进行优化(可怕)
* 我们使用BFS遍历一个树时,深度越深,同级的元素越多。
* 对于本题,已经确定了两端,可以使用双向BFS进行优化
如下图:(图片来自leetcode大神 [liweiwei](https://leetcode-cn.com/u/liweiwei1419/))
拖着被虐的疲惫不堪的心灵和身体,尝试优化一下代码,AC!
被虐的够呛,代码参考了[Mcdull](https://leetcode-cn.com/u/mcdull0921/)大神的解题
#### 代码
python3
```
class Solution:
def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:
if endWord not in wordList:
return []
def makeMap(words):
s = collections.defaultdict(list)
for w in words:
for i in range(len(w)):
s[w[:i] + '*' + w[i+1:]].append(w)
return s
visited = set()
s = makeMap(wordList)
def neighborWords(word):
words = []
for i in range(len(word)):
for c in s[word[:i] + '*' + word[i+1:]]:
if c not in visited:
words.append(c)
return words
path = collections.defaultdict(set)
headqueue = set([beginWord]) # 头部开始的队列
tailqueue = set([endWord]) # 尾部开始的队列
forward = True
while headqueue and tailqueue:
if len(headqueue) > len(tailqueue):
headqueue,tailqueue = tailqueue,headqueue
forward = not forward
temp = set()
for word in headqueue:
visited.add(word)
for word in headqueue:
for w in neighborWords(word):
temp.add(w)
if forward:
path[w].add(word)
else:
path[word].add(w)
headqueue = temp
if headqueue & tailqueue: # 表示有相交
res = [[endWord]]
while res[0][0] != beginWord:
temp_res=[]
for curr in res:
for parent in path[curr[0]]:
temp_res.append([parent]+curr)
res = temp_res
return res
return []
```
- 目录
- excel-sheet-column-number
- divide-two-integers
- house-robber
- fraction-to-recurring-decimal
- profile
- kids-with-the-greatest-number-of-candies
- qiu-12n-lcof
- new-21-game
- product-of-array-except-self
- minimum-depth-of-binary-tree
- univalued-binary-tree
- shun-shi-zhen-da-yin-ju-zhen-lcof
- permutations
- satisfiability-of-equality-equations
- word-ladder-ii
- ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof
- palindrome-number
- network-delay-time
- daily-temperatures
- longest-common-prefix
- sum-of-mutated-array-closest-to-target
- 周赛专题
- make-two-arrays-equal-by-reversing-sub-arrays
- check-if-a-string-contains-all-binary-codes-of-size-k
- course-schedule-iv
- cherry-pickup-ii
- maximum-product-of-two-elements-in-an-array
- maximum-area-of-a-piece-of-cake-after-horizontal-and-vertical-cuts
- reorder-routes-to-make-all-paths-lead-to-the-city-zero
- probability-of-a-two-boxes-having-the-same-number-of-distinct-balls
- shuffle-the-array
- the-k-strongest-values-in-an-array
- design-browser-history
- paint-house-iii
- final-prices-with-a-special-discount-in-a-shop