
> 原文地址:http://imysql.com/2014/09/14/mysql-faq-why-innodb-table-using-autoinc-int-as-pk.shtml
我们先了解下InnoDB引擎表的一些关键特征:
* InnoDB引擎表是基于B+树的索引组织表(IOT);
* 每个表都需要有一个聚集索引(clustered index);
* 所有的行记录都存储在B+树的叶子节点(leaf pages of the tree);
* 基于聚集索引的增、删、改、查的效率相对是最高的;
* 如果我们定义了主键(PRIMARY KEY),那么InnoDB会选择其作为聚集索引;
* 如果没有显式定义主键,则InnoDB会选择第一个不包含有NULL值的唯一索引作为主键索引;
* 如果也没有这样的唯一索引,则InnoDB会选择内置6字节长的ROWID作为隐含的聚集索引(ROWID随着行记录的写入而主键递增,这个ROWID不像ORACLE的ROWID那样可引用,是隐含的)。
综上总结,如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的,也就是下面这几种情况的存取效率最高:
* 使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致;
* 该表不指定自增列做主键,同时也没有可以被选为主键的唯一索引(上面的条件),这时候InnoDB会选择内置的ROWID作为主键,写入顺序和ROWID增长顺序一致;
* 除此以外,如果一个InnoDB表又没有显示主键,又有可以被选择为主键的唯一索引,但该唯一索引可能不是递增关系时(例如字符串、UUID、多字段联合唯一索引的情况),该表的存取效率就会比较差。
实际情况是如何呢?经过简单[TPCC基准测试](http://imysql.com/2012/08/04/tpcc-for-mysql-manual.html "TPCC-MySQL使用手册"),修改为使用自增列作为主键与原始表结构分别进行TPCC测试,前者的TpmC结果比后者高9%倍,足见使用自增列做InnoDB表主键的明显好处,其他更多不同场景下使用自增列的性能提升可以自行对比测试下。
附图:
1、B+树典型结构
[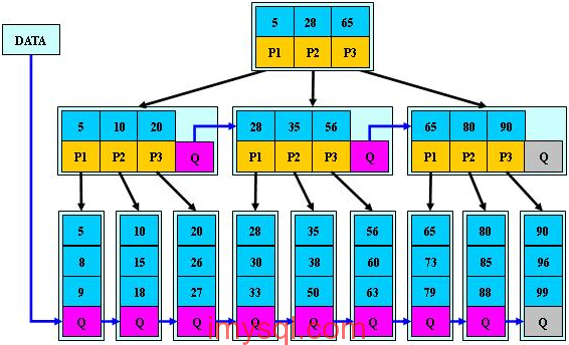](https://box.kancloud.cn/2015-07-29_55b87267866de.png)
2、InnoDB主键逻辑结构
[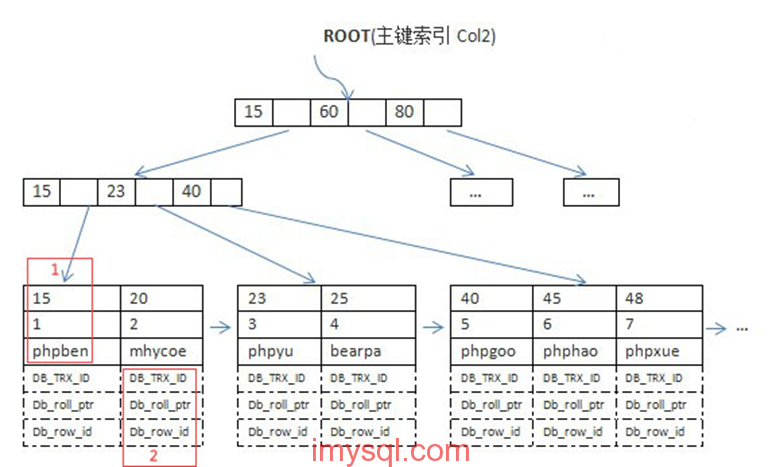](https://box.kancloud.cn/2015-07-29_55b872695d51e.png)
延伸阅读:
1、[TPCC-MySQL使用手册](http://imysql.com/2012/08/04/tpcc-for-mysql-manual.html "TPCC-MySQL使用手册")
2、[B+Tree index structures in InnoDB](http://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/ "B+Tree index structures in InnoDB")
3、[B+Tree Indexes and InnoDB – Percona](http://www.percona.com/files/presentations/percona-live/london-2011/PLUK2011-b-tree-indexes-and-innodb.pdf "B+Tree Indexes and InnoDB - percona")
4、[MySQL官方手册: Clustered and Secondary Indexes](https://dev.mysql.com/doc/refman/5.6/en/innodb-index-types.html "14.2.13.2 Clustered and Secondary Indexes")
- 前言
- 为什么InnoDB表要建议用自增列做主键
- 线上环境到底要不要开启query cache
- MySQL复制中slave延迟监控
- 如何安全地关闭MySQL实例
- 如何查看当前最新事务ID
- 从MyISAM转到InnoDB需要注意什么
- 5.6版本GTID复制异常处理一例
- 不同的binlog_format会导致哪些SQL不会被记录
- Spring框架中调用存储过程失败
- 如何将两个表名对调
- mysqldump加-w参数备份
- 使用mysqldump备份时为什么要加上 -q 参数
- 修改my.cnf配置不生效
- 什么情况下会用到临时表
- profiling中要关注哪些信息
- EXPLAIN结果中哪些信息要引起关注
- processlist中哪些状态要引起关注
- MySQL无法启动例一
- pt-table-checksum工具使用报错一例
- 为什么要关闭query cache,如何关闭
- MySQL联合索引是否支持不同排序规则
- SAVEPOINT语法错误一例
- 你所不知的table is full那些事
- 大数据量时如何部署MySQL Replication从库
- 内存溢出案例