# **掌握基础的知识**
**1.redis 默认有16个数据库**
**2.select命令**
```
如:select 3
127.0.0.1:6379> select 3
#切换数据库
OK
127.0.0.1:6379[3]> dbsize
#查看数据库大小
(integer) 0
```
**3.dbsize命令**
```
dbsize 查看当前数据库的文件大小
dbsize
127.0.0.1:6379> dbsize
(integer) 5
```
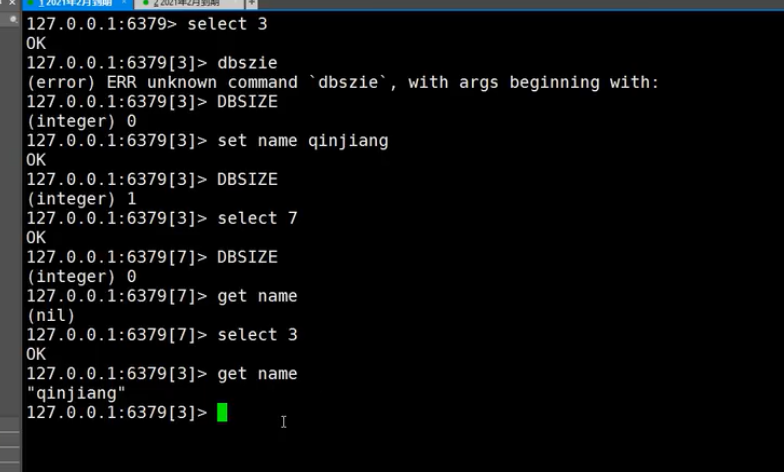
**4.不同数据库操作**
当然了不同的数据库存有不同的数据库,在当前数据库不能操作其他数据库的数据
**5.set命令**
```
set name wyoq
127.0.0.1:6379> set name wyoq
OK
```
**6.keys命令**
```php
指令:keys * 【*号代表所有】
操作:keys name
127.0.0.1:6379> keys *
1) "myset:__rand_int__"
2) "mylist"
3) "key:__rand_int__"
4) "counter:__rand_int__"
5) "name" key值
OK
```
**7.get命令**
```
指令 get key 【key键值】
操作如:get name
127.0.0.1:6379> get name
"wyoq" value值
```
**8.flushdb && flushall命令**
```
指令 flushdb 【清空当前库所以的key指令】
操作如:flushdb
127.0.0.1:6379> keys *
1) "myset:__rand_int__"
2) "mylist"
3) "key:__rand_int__"
4) "counter:__rand_int__"
5) "name"
127.0.0.1:6379> get name
"wyoq"
127.0.0.1:6379> flushdb 【清空操作】
OK
127.0.0.1:6379> get name
(nil)
获取不到了
127.0.0.1:6379> keys *
(empty list or set)
flushall清空所有的库
```
思考:为什么redis端口号是6379
6379在是手机按键上MERZ对应的号码,而MERZ取自意大利歌女[Alessia Merz](http://it.wikipedia.org/wiki/Alessia_Merz)的名字。MERZ长期以来被antirez及其朋友当作愚蠢的代名词。[Redis](http://blog.nosqlfan.com/tags/redis "查看 Redis 的全部文章")作者antirez同学在twitter上说将在下一篇博文中向大家解释为什么他选择[6379](http://blog.nosqlfan.com/tags/6379 "查看 6379 的全部文章")作为[默认](http://blog.nosqlfan.com/tags/%E9%BB%98%E8%AE%A4 "查看 默认 的全部文章")[端口](http://blog.nosqlfan.com/tags/%E7%AB%AF%E5%8F%A3 "查看 端口 的全部文章")号。而现在这篇博文出炉,在解释了Redis的LRU机制之后,向大家解释了采用6379作为默认端口的原因。
## **Redis是单线程的!**
因为redis非常快,官方表示,redis是基于内存操作,cpu不是redis的性能瓶颈,redis的瓶颈是根据机器的内存和网络带宽,既然可以使用单线程来实现,就使用了单线程。
## **Redis为什么是单线程还快**
1.误区:高性能的服务器一定多线程的?
2.误区二:多线程(cpu上下文切换)一定比单线程高!
3.CPU速度 > 内存 > 硬盘
核心:redis是将所有的数据全部放在了内存中,所以说使用单线程去操作就是最高的(多线程CPU会进行上下文切换:耗时的操作!!)。对于内存来说,如果没有上下文切换效率就是最高的!多次读写都是在一个CPU上的,所以在内存上就是最佳的方案。
