安装了ptcms4.2.8小说程序以后,很多小伙伴不知道怎么配置采集教程,今天来介绍一下具体的采集方法。
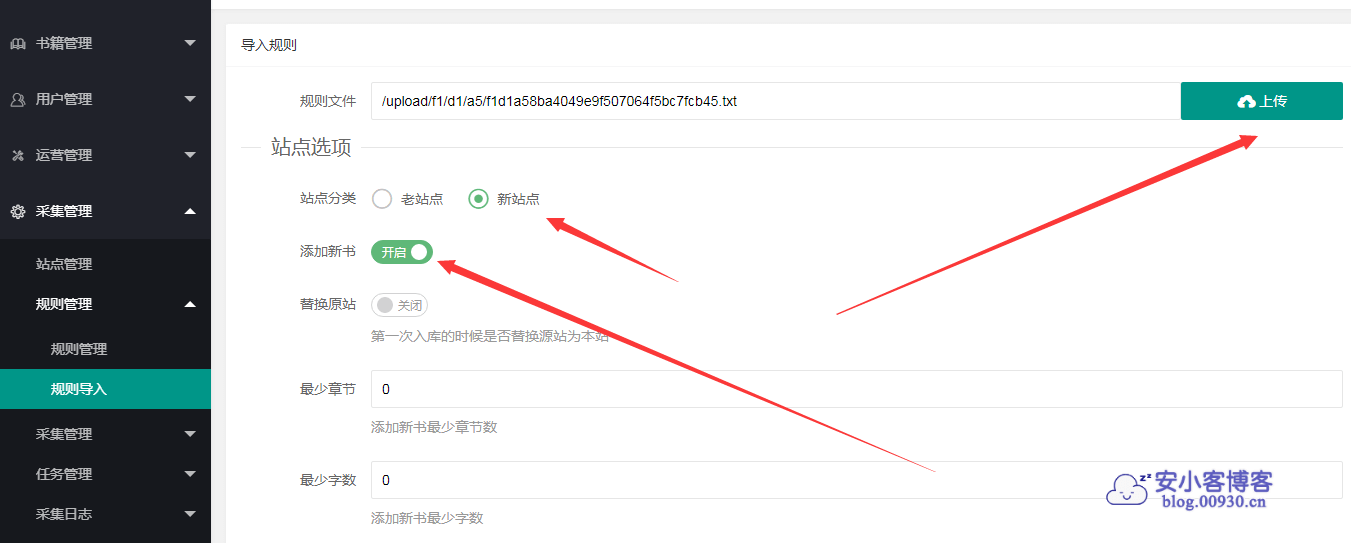
导入采集规则,选择新站点,添加新书打勾。其他默认(以后如果因为源站改动规则失效,可以找人写下那个失效站点的规则,然后导入,选择这个老站点,覆盖掉对应的站点和规则就行)
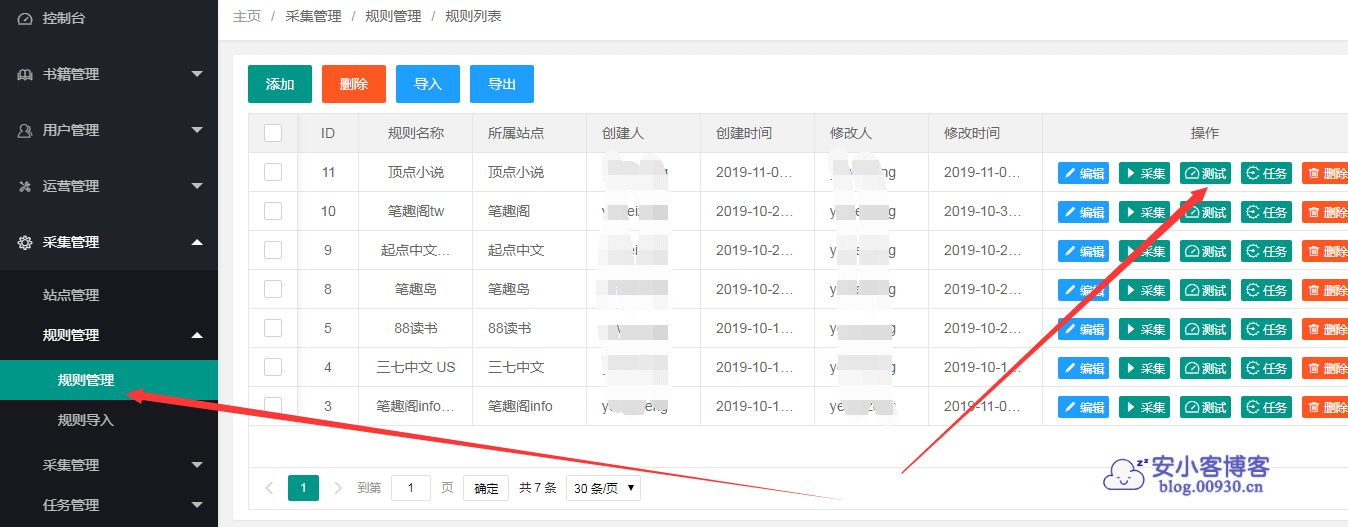
点击测试,先测试下规则能不能用,再加入后台任务计划。采集时间间隔默认是600,我嫌时间太长,设置成60。
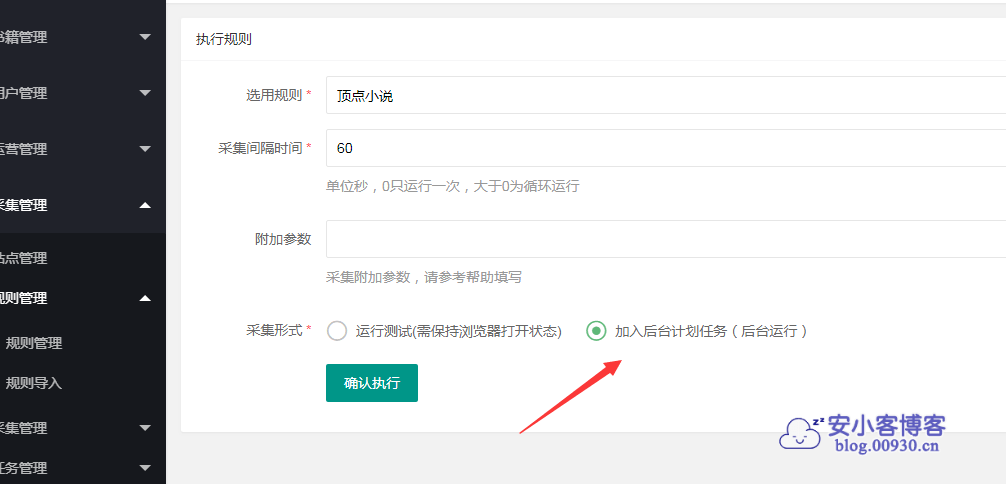
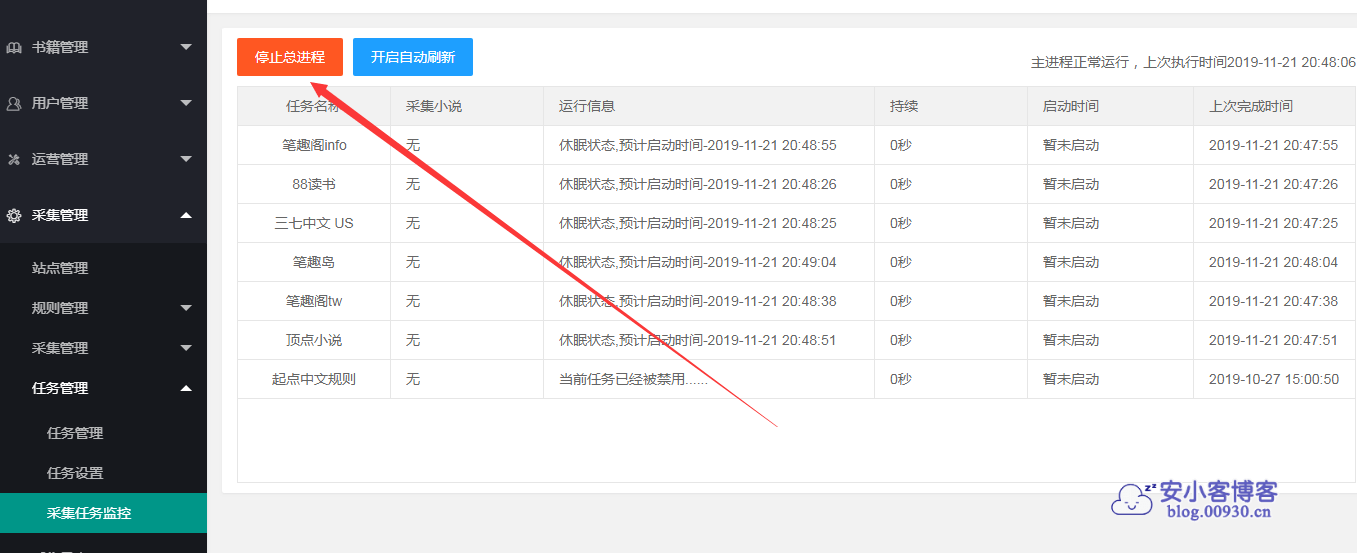
然后启动运行就行,我这里已经是开启的了,如果提示主线进程状态失败,时间也是1970,采集不了的,那说明你还没配置cron。直接看这篇第10步有说明。
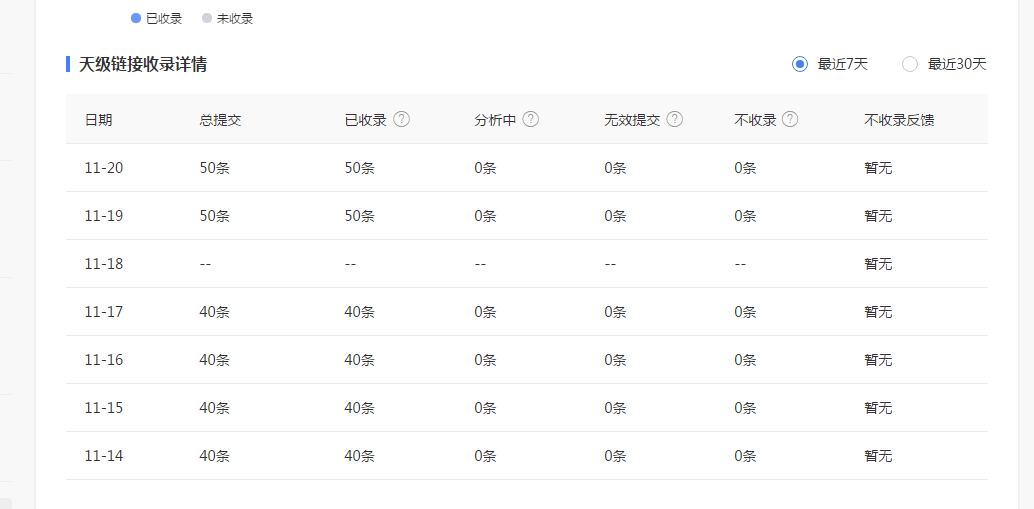
现在就能自动采集了,但是因为ptcms的特性,自动采集每天也就几百,有的人网站刚建好,小说太少,嫌慢,希望自己先主动采集多少本,后面再挂着自动采集,现在来说明下
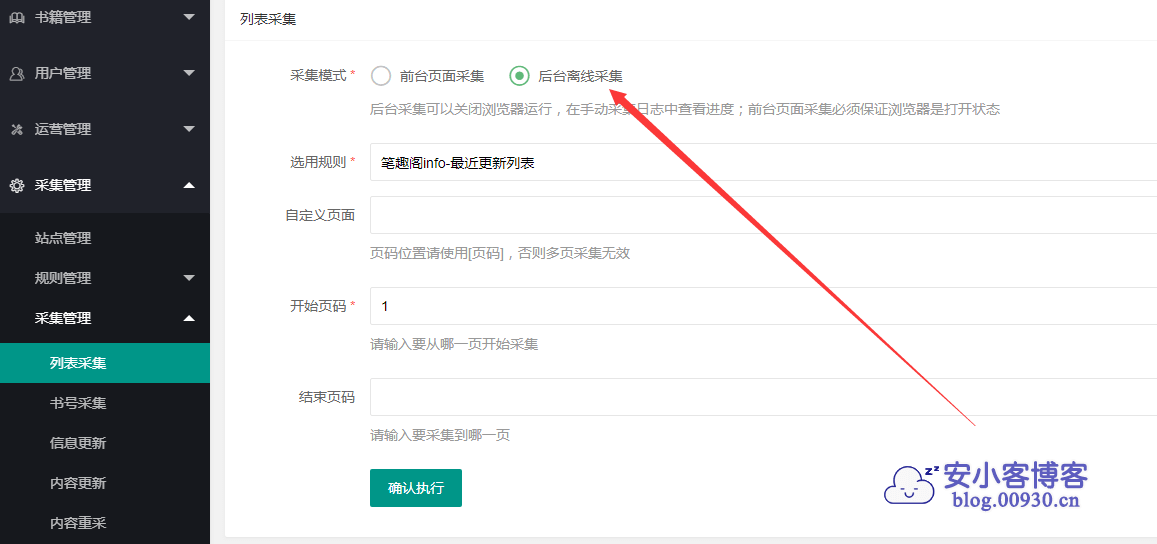
一般选用后台离线采集,选择规则,自定义页面,填入要采集的页面,比如说https://www.biquge.info/paihangbang\_postdate/1.html
这个页面,是第一页,第二页只是后面的1变成2。可以用\[page\]这个页码代码来代替比如说
https://www.biquge.info/paihangbang\_postdate/\[page\].html
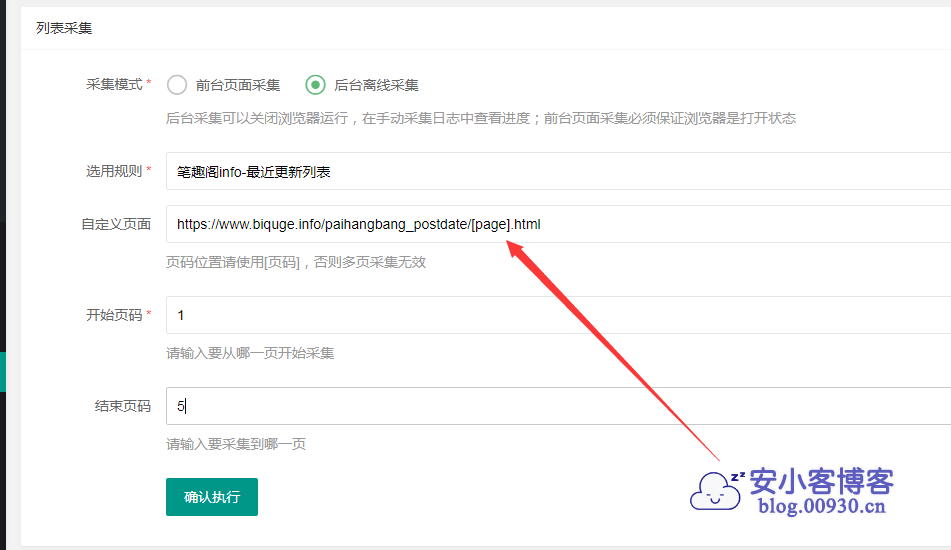
比如我要采集这个页面的1-5页,就可以如下图这样写。好了教程就到这里,我没用里面的书号采集,书号采集容易出现采集到废的小说或很多没封面的。
关于网站的基础配置教程可以参考这篇设置。
