## **数据库架构的演变**
在业务数据量比较少的时代,我们使用单机数据库就能满足业务使用,随着业务请求量越来越多,数据库中的数据量快速增加,这时单机数据库已经不能满足业务的性能要求,数据库主从复制架构随之应运而生。<p>
主从复制是将数据库写操作和读操作进行分离,使用多个只读实例(slaver replication)负责处理读请求,主实例(master)负责处理写请求,只读实例通过复制主实例的数据来保持与主实例的数据一致性。由于只读实例可以水平扩展,所以更多的读请求不成问题,随着云计算、大数据时代的到来,事情并没有完美的得以解决,当写请求越来越多,主实例的写请求变成主要的性能瓶颈。<p>
如何解决上述问题?如果仅仅通过增加一个主实例来分担写请求,写操作如何在两个主实例之间同步来保证数据一致性,如何避免双写,问题会变的更加复杂。这时就需要用到分库分表(sharding),逻辑上大致如下图所示:

Sharding-Proxy是一个分布式数据库中间件,彻底解决了数据库的扩展性问题,对应用透明地实现海量数据的高并发访问,实现了读写分离和分库分表。
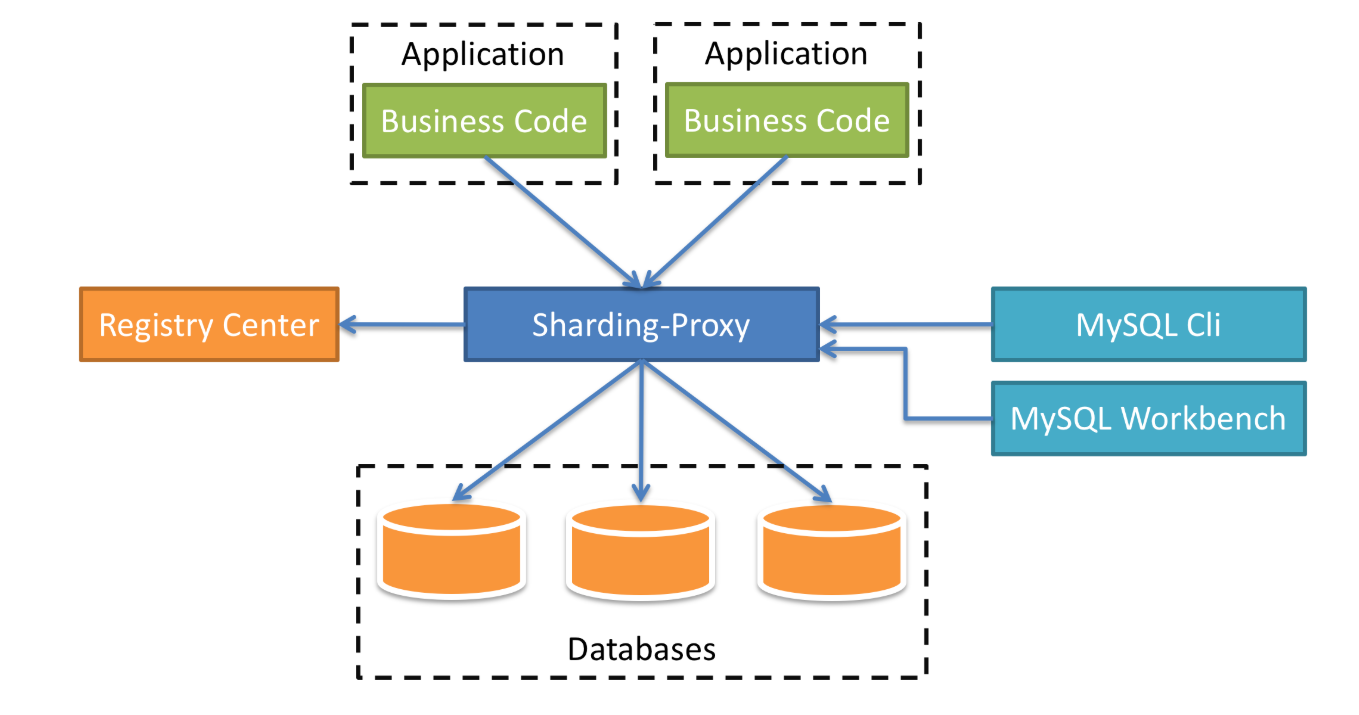
在架构图中,中间的蓝色方块就是我们的中间件Sharding-Proxy,下面连接的是数据库,我们可以配置每一个数据库的分片,还可以配置数据库的读写分离,影子库等等。上方则是我们的业务代码,他们统一连接Sharding-Proxy,就像直接连接数据库一样,而具体的数据插入哪一个数据库,则由Sharding-Proxy中的分片规则决定。再看看右侧,右侧是一些数据库的工具,比如:MySQL CLI,Navicat,SQLYog等。最后再来看看左侧,是一个注册中心,目前支持最好的是Zookeeper,在注册中心中,我们可以统一配置分片规则,读写数据源等,而且是实时生效的,在管理多个Sharding-Proxy时,非常的方便。
## **对比**
| | *Sharding-JDBC* | *Sharding-Proxy* | *Sharding-Sidecar* |
| --- | --- | --- | --- |
| 数据库 | 任意 | `MySQL/PostgreSQL` | MySQL/PostgreSQL |
| 连接消耗数 | 高 | `低` | 高 |
| 异构语言 | 仅Java | `任意` | 任意 |
| 性能 | 损耗低 | `损耗略高` | 损耗低 |
| 无中心化 | 是 | `否` | 是 |
| 静态入口 | 无 | `有` | 无 |
Sharding-Proxy的优势在于对异构语言的支持,以及为DBA提供可操作入口。
* 向应用程序完全透明,可直接当做MySQL/PostgreSQL使用。
* 适用于任何兼容MySQL/PostgreSQL协议的的客户端。
- 数据库架构的演变
- 安装Sharding-Proxy
- 数据分片之概念篇
- 数据分片之水平分库分表
- 数据分片之垂直分库分表(解决中文乱码问题)
- tp6 基于Sharding-Proxy的分库分表
- 全局分布式ID生成
- 范围分片-按年分库按月分表
- tp6 基于Sharding-Proxy的读写分离
- 基于docker搭建mysql8的GTID半同步复制
- 数据读写分离实战
- Hint 强制查询走主库
- 广播表
- 数据脱敏
- tp6 基于Sharding-Proxy的事务管理
- 本地事务
- 两阶段事务(XA强一致事务)
- 柔性事务-BASE
- logback 自定义日志级别及存储方案
- Sharding-Proxy 整合Nginx实现高可用
- Sharding-Proxy 集群扩容方案