# <a class="pcalibre pcalibre1" id="_Toc446405748">第2</a>周
### <a class="pcalibre pcalibre1" id="_Toc446405750">4.1 </a>多维特征
参考视频: 4 - 1 - Multiple Features (8 min).mkv
目前为止,我们探讨了单变量/特征的回归模型,现在我们对房价模型增加更多的特征,例如房间数楼层等,构成一个含有多个变量的模型,模型中的特征为(x1,x2,...,xn)。
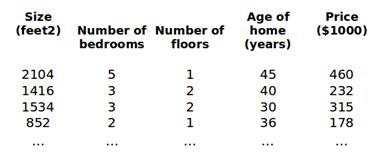
增添更多特征后,我们引入一系列新的注释:
n 代表特征的数量
x(i)代表第 i 个训练实例,是特征矩阵中的第i行,是一个向量(vector)。
比方说,上图的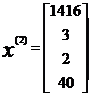,
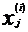代表特征矩阵中第 i 行的第 j 个特征,也就是第 i 个训练实例的第 j 个特征。
如上图的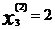,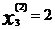
支持多变量的假设 h 表示为: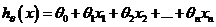
这个公式中有n+1个参数和n个变量,为了使得公式能够简化一些,引入x0=1,则公式转化为:
此时模型中的参数是一个n+1维的向量,任何一个训练实例也都是n+1维的向量,特征矩阵X的维度是 m\*(n+1)。因此公式可以简化为: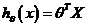,其中上标T代表矩阵转置。
- 第1周
- 一、引言(Introduction)
- 1.1 欢迎
- 1.2 机器学习是什么?
- 1.3 监督学习
- 1.4 无监督学习
- 二、单变量线性回归(Linear Regression with One Variable)
- 2.1模型表示
- 2.2 代价函数
- 2.3 代价函数的直观理解I
- 2.4 代价函数的直观理解II
- 2.5 梯度下降
- 2.6 梯度下降的直观理解
- 2.7 梯度下降的线性回归
- 2.8 接下来的内容
- 三、线性代数回顾(Linear Algebra Review)
- 3.1 矩阵和向量
- 3.2 加法和标量乘法
- 3.3 矩阵向量乘法
- 3.4 矩阵乘法
- 3.5 矩阵乘法的性质
- 3.6 逆、转置
- 第2周
- 四、多变量线性回归(Linear Regression with Multiple Variables)
- 4.1 多维特征
- 4.2 多变量梯度下降
- 4.3 梯度下降法实践1-特征缩放
- 4.4 梯度下降法实践2-学习率
- 4.5 特征和多项式回归
- 4.6 正规方程
- 4.7 正规方程及不可逆性(可选)
- 五、Octave教程(Octave Tutorial)
- 5.1 基本操作
- 5.2 移动数据
- 5.3 计算数据
- 5.5 控制语句:for,while,if语句
- 5.6 向量化
- 5.7 工作和提交的编程练习
- 第3周
- 六、逻辑回归(Logistic Regression)
- 6.1 分类问题
- 6.2 假说表示
- 6.3 判定边界
- 6.4 代价函数
- 6.5 简化的成本函数和梯度下降
- 6.6 高级优化
- 6.7 多类别分类:一对多
- 七、正则化(Regularization)
- 7.1 过拟合的问题
- 7.2 代价函数
- 7.3 正则化线性回归
- 7.4 正则化的逻辑回归模型
- 第4周
- 第八、神经网络:表述(Neural Networks: Representation)
- 8.1 非线性假设
- 8.2 神经元和大脑
- 8.3模型表示1
- 8.4 模型表示2
- 8.5特征和直观理解1
- 8.6 样本和直观理解II
- 8.7多类分类
- 第5周
- 九、神经网络的学习(Neural Networks: Learning)
- 9.1 代价函数
- 9.2 反向传播算法
- 9.3 反向传播算法的直观理解
- 9.4 实现注意:展开参数
- 9.5梯度检验
- 9.6 随机初始化
- 9.7 综合起来
- 9.8 自主驾驶
- 第6周
- 十、应用机器学习的建议(Advice for Applying Machine Learning)
- 10.1 决定下一步做什么
- 10.2 评估一个假设
- 10.3 模型选择和交叉验证集
- 10.4 诊断偏差和方差
- 10.5 归一化和偏差/方差
- 10.6 学习曲线
- 10.7 决定下一步做什么
- 十一、机器学习系统的设计(Machine Learning System Design)
- 11.1 首先要做什么
- 11.2 误差分析
- 11.3 类偏斜的误差度量
- 11.4 查全率和查准率之间的权衡
- 11.5 机器学习的数据
- 第7周
- 十二、支持向量机(Support Vector Machines)
- 12.1 优化目标
- 12.2 大边界的直观理解
- 12.3 数学背后的大边界分类(可选)
- 12.4 核函数1
- 12.5 核函数2
- 12.6 使用支持向量机
- 第8周
- 十三、聚类(Clustering)
- 13.1 无监督学习:简介
- 13.2 K-均值算法
- 13.3 优化目标
- 13.4 随机初始化
- 13.5 选择聚类数
- 十四、降维(Dimensionality Reduction)
- 14.1 动机一:数据压缩
- 14.2 动机二:数据可视化
- 14.3 主成分分析问题
- 14.4 主成分分析算法
- 14.5 选择主成分的数量
- 14.6 重建的压缩表示
- 14.7 主成分分析法的应用建议
- 第9周
- 十五、异常检测(Anomaly Detection)
- 15.1 问题的动机
- 15.2 高斯分布
- 15.3 算法
- 15.4 开发和评价一个异常检测系统
- 15.5 异常检测与监督学习对比
- 15.6 选择特征
- 15.7 多元高斯分布(可选)
- 15.8 使用多元高斯分布进行异常检测(可选)
- 十六、推荐系统(Recommender Systems)
- 16.1 问题形式化
- 16.2 基于内容的推荐系统
- 16.3 协同过滤
- 16.4 协同过滤算法
- 16.5 矢量化:低秩矩阵分解
- 16.6 推行工作上的细节:均值归一化
- 第10周
- 十七、大规模机器学习(Large Scale Machine Learning)
- 17.1 大型数据集的学习
- 17.2 随机梯度下降法
- 17.3 小批量梯度下降
- 17.4 随机梯度下降收敛
- 17.5 在线学习
- 17.6映射化简和数据并行
- 十八、应用实例:图片文字识别(Application Example: Photo OCR)
- 18.1 问题描述和流程图
- 18.2 滑动窗口
- 18.3 获取大量数据和人工数据
- 18.4 上限分析:哪部分管道的接下去做
- 十九、总结(Conclusion)
- 19.1 总结和致谢