# 课程大纲
本课程分如下几个阶段介绍网络爬虫知识:
- [入门篇](入门篇.md): 基本功,掌握基础Web知识
- [进阶篇](进阶篇.md): 武功招式,游走在PC浏览器和移动APP上的数据操作
- [高级篇](高级篇.md): 高级招式, “天下武功,唯快不破。”

---
Pyhon虫师的进阶之路
--
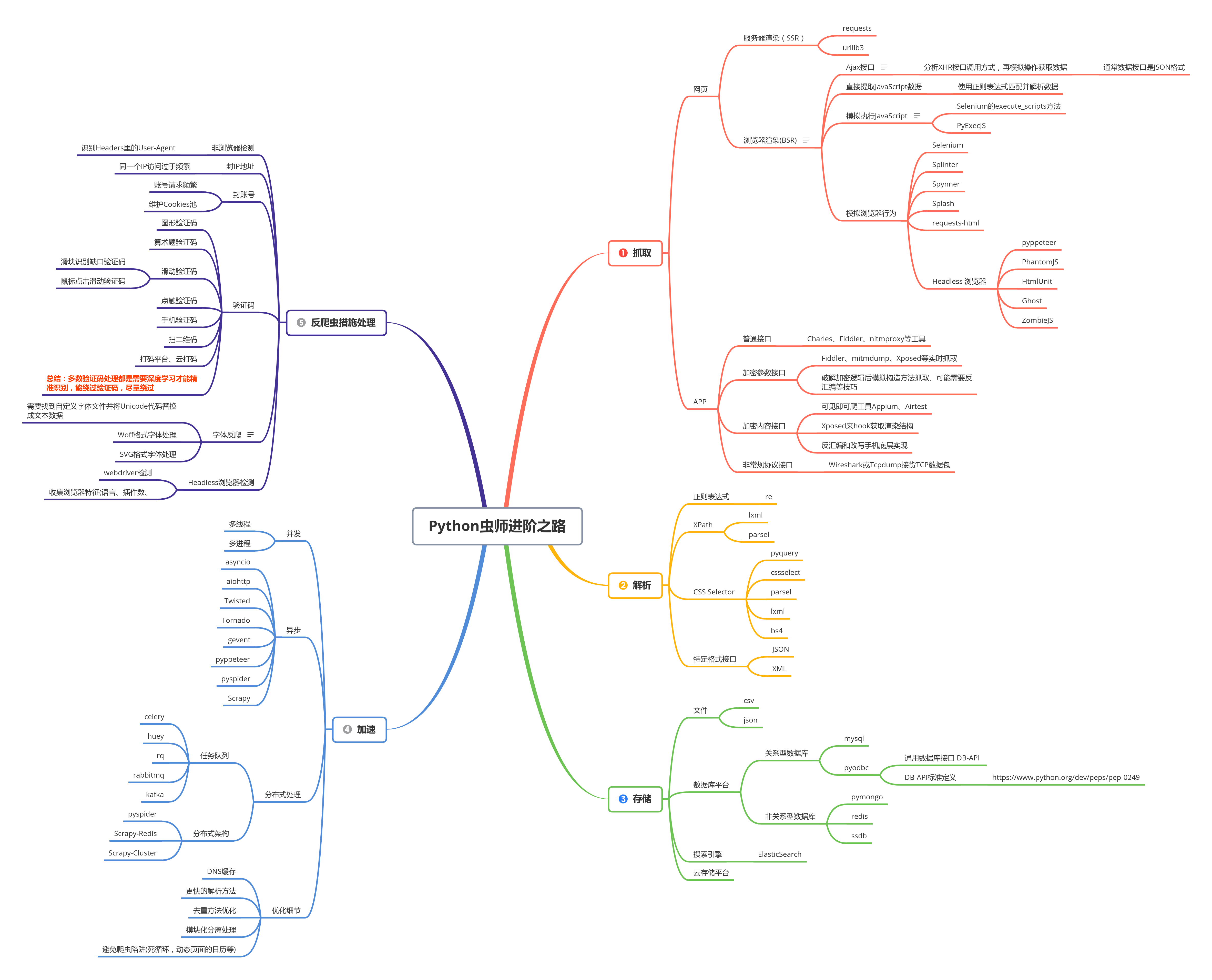
- 课程大纲
- 入门篇
- 爬虫是什么
- 为什么要学习爬虫
- 爬虫的基本原理
- TCP/IP协议族的基本知识
- HTTP协议基础知识
- HTML基础知识
- HTML_DOM基础知识
- urllib3库的基本使用
- requests库的基本使用
- Web页面数据解析处理方法
- re库正则表达式的基础使用
- CSS选择器参考手册
- XPath快速了解
- 实战练习:百度贴吧热议榜
- 进阶篇
- 服务端渲染(CSR)页面抓取方法
- 客户端渲染(CSR)页面抓取方法
- Selenium库的基本使用
- Selenium库的高级使用
- Selenium调用JavaScript方法
- Selenium库的远程WebDriver
- APP移动端数据抓取基础知识
- HTTP协议代理抓包分析方法
- Appium测试Android应用基础环境准备
- Appium爬虫编写实战学习
- Appium的元素相关的方法
- Appium的Device相关操作方法
- Appium的交互操作方法
- 代理池的使用与搭建
- Cookies池的搭建与用法
- 数据持久化-数据库的基础操作方法(mysql/redis/mongodb)
- 执行JS之execjs库使用
- 高级篇
- Scrapy的基本知识
- Scrapy的Spider详细介绍
- Scrapy的Selector选择器使用方法
- Scrapy的Item使用方法
- Scrapy的ItemPipeline使用方法
- Scrapy的Shell调试方法
- Scrapy的Proxy设置方法
- Scrapy的Referer填充策略
- Scrapy的服务端部署方法
- Scrapy的分布式爬虫部署方法
- Headless浏览器-pyppeteer基础知识
- Headless浏览器-pyppeteer常用的设置方法
- Headless浏览器-反爬应对办法
- 爬虫设置技巧-UserAgent设置
- 反爬策略之验证码处理方法
- 反爬识别码之点击文字图片的自动识别方法
- 反爬字体处理方法总结
- 防止反爬虫的设置技巧总结
- 实战篇
- AJAX接口-CSDN技术博客文章标题爬取
- AJAX接口-拉购网职位搜索爬虫
- 执行JS示例方法一之动漫图片地址获取方法
- JS执行方法示例二完整mangabz漫画爬虫示例
- 应用实践-SOCKS代理池爬虫
- 落霞小说爬虫自动制作epub电子书
- 一种简单的适用于分布式模式知乎用户信息爬虫实现示例
- 法律安全说明