**处理字符问题**

`db 'unlx'`相当于"db 75H,6EH,49H,S8H" , "u"、"n"、"1"、"X"的ASCI1别为75H、 6EH,49H, 58H;
`db 'оRK'`相当于"db 66H,6FH,S2H,4BH" , "f"、"0"、"R"、“K"的ASC1分别为66H、 6FH, 52H,4BH;
编译器会将字符转化为ASCII码
`mov al,'a'`在汇编中识别为`mov 61`
数据段为什么是从076A开始的?
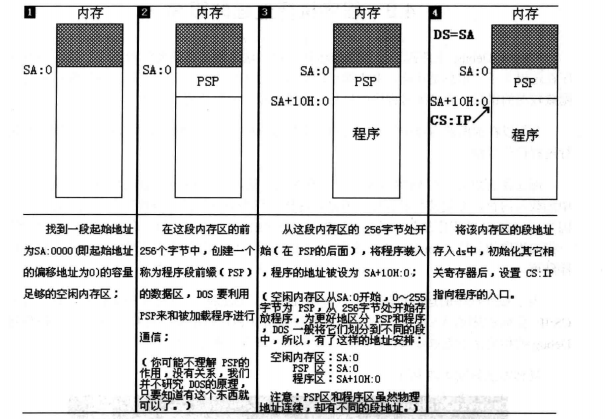
《汇编语言》(第二版)P104页,上面写着参考4.9节内容。原因大致如下: 设找到一段起始地址为 SA:0000 的容量足够的空闲内存区;在这段内存区的前256个字节中,创建一个称谓程序段前缀(PSP)的数据区,DOS要利用PSP来和被加载程序进行通信(不理解的话可以暂且记住);在这段内存区的256字节处开始(在PSP的后面),将程序装入,程序的地址被设为SA+10H:0(这里确实是256个字节即100H,256 = 16*16,所以会空出100H 的空间,也就是10:0H,“写法可能不对,暂且这么理解”);将这段内存区的段地址存入ds中,初始化其他相关的寄存器后,设置CSIP指向程序的入口
**大小写转换**

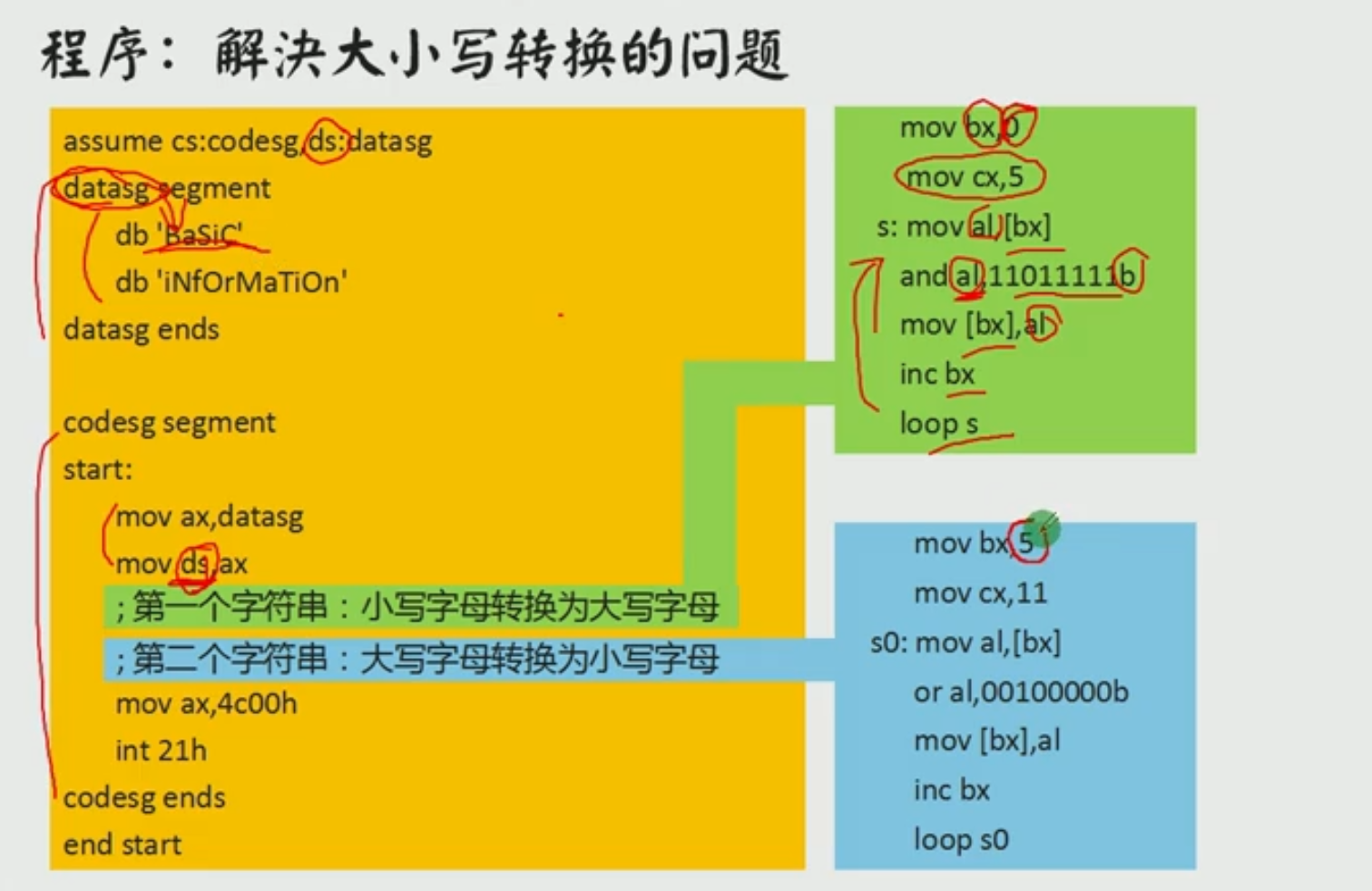
大写字母 = 小写字母 and 1101 1111 //其他位数保持不变,第6位从1变成0
小写字母 = 大写字母 or 0010 0000 //其他位数保持不变,第6位从0变成1
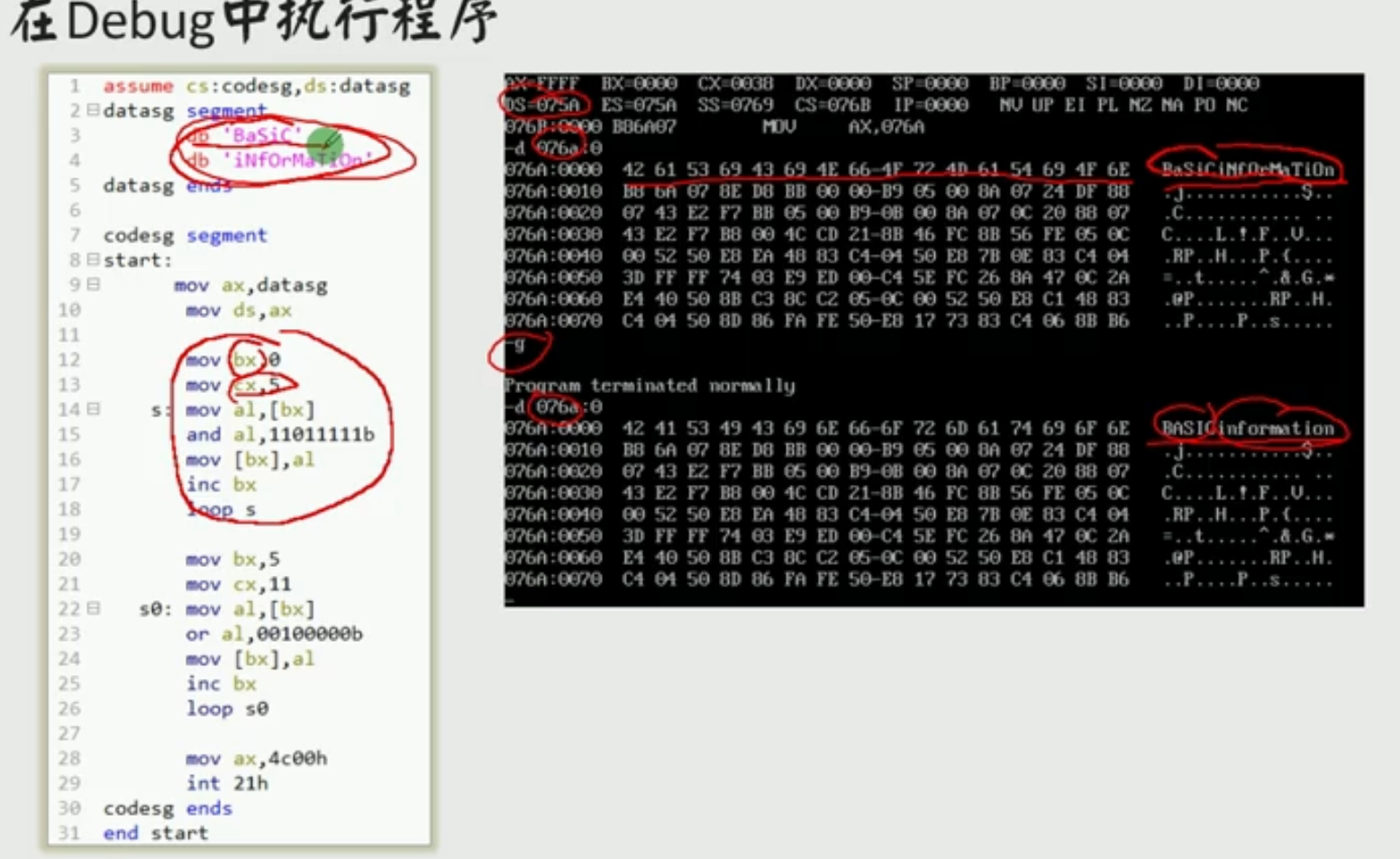
改进版查看[bx+idata]方式寻址章节
```
```
