# 介绍 Kudu
原文链接 : [http://kudu.apache.org/docs/index.html](http://kudu.apache.org/docs/index.html)
译文链接 : [http://cwiki.apachecn.org/pages/viewpage.action?pageId=10813605](http://cwiki.apachecn.org/pages/viewpage.action?pageId=10813605)
贡献者 : [那伊抹微笑](/display/~wangyangting),[ApacheCN](/display/~apachecn),[Apache中文网](/display/~apachechina)
**Kudu** 是一个针对 **Apache Hadoop** 平台而开发的列式存储管理器。**Kudu** 共享 **Hadoop** 生态系统应用的常见技术特性: 它在 **commodity hardware**(商品硬件)上运行,**horizontally** **scalable**(水平可扩展),并支持 **highly** **available**(高可用)性操作。
此外,**Kudu **还有更多优化的特点:
* **OLAP** 工作的快速处理。
* 与 **MapReduce**,**Spark** 和其他 **Hadoop** 生态系统组件集成。
* 与 **Apache Impala(incubating)**紧密集成,使其与 **Apache Parquet** 一起使用 **HDFS** 成为一个很好的可变的替代方案。
* 强大而灵活的一致性模型,允许您根据每个 **per-request**(请求选择)一致性要求,包括 **strict-serializable**(严格可序列化)一致性的选项。
* 针对同时运行顺序和随机工作负载的情况性能很好。
* 使用 **Cloudera Manager **轻松维护和管理。
* **High availability**(高可用性)。**Tablet server **和 **Master** 使用 [Raft Consensus Algorithm](http://kudu.apache.org/docs/#raft) 来保证节点的高可用,确保只要有一半以上的副本可用,该 **tablet **便可用于读写。例如,如果 **3** 个副本中有 **2 **个或 **5 **个副本中的 **3 **个可用,则该 **tablet **可用。即使在 **leader** **tablet **出现故障的情况下,读取功能也可以通过 **read-only**(只读的)**follower tablets** 来进行服务。
* 结构化数据模型。
通过结合这些所有的特性,**Kudu **的目标是支持应用家庭中那些难以在当前**Hadoop **存储技术中实现的应用。**Kudu** 常见的几个应用场景:
* 实时更新的应用。刚刚到达的数据就马上要被终端用户使用访问到。
* 时间序列相关的应用,需要同时支持:
* 根据海量历史数据查询。
* 必须非常快地返回关于单个实体的细粒度查询。
* 实时预测模型的应用,支持根据所有历史数据周期地更新模型。
* 有关这些和其他方案的更多信息,请参阅 [Example Use Cases](http://kudu.apache.org/docs/#kudu_use_cases)。
## Kudu-Impala 集成特性
**CREATE/ALTER/DROP TABLE**
**Impala** 支持使用 **Kudu** 作为持久层来 **creating**(创建),**altering**(修改)和 **dropping**(删除)表。这些表遵循与 **Impala **中其他表格相同的 I**nternal / external**(内部 / 外部)方法,允许灵活的数据采集和查询。
**INSERT**
数据可以使用与那些使用 **HDFS** 或 **HBase** 持久性的任何其他 **Impala** 表相同的语法插入 **Impala** 中的 **Kudu** 表。
**`UPDATE` / `DELETE`**
**Impala **支持 **`UPDATE `**和 **`DELETE `SQL** 命令逐行或批处理修改 **Kudu **表中的已有的数据。选择 **SQL **命令的语法与现有标准尽可能兼容。除了简单 **`DELETE` **或 **`UPDATE `**命令之外,还可以 **`FROM `**在子查询中指定带有子句的复杂连接。
**Flexible Partitioning(灵活分区)**
与 **Hive **中的表分区类似,**Kudu **允许您通过 **hash** 或范围动态预分割成预定义数量的 **tablets**,以便在集群中均匀分布写入和查询。您可以通过任意数量的 **primary** **key**(主键)列,任意数量的 **hashes **和可选的 **list of split rows** 来进行分区。参见[模式设计](http://kudu.apache.org/docs/schema_design.html)。
**Parallel Scan(并行扫描)**
为了在现代硬件上实现最高的性能,**Impala **使用的 **Kudu **客户端可以跨多个 **tablets **扫描。
**High-efficiency queries(高效查询)**
在可能的情况下,**Impala **将谓词评估下推到 **Kudu**,以便使谓词评估为尽可能接近数据。在许多任务中,查询性能与 **Parquet **相当。
有关使用 **Impala **查询存储在 **Kudu **中的数据的更多详细信息,请参阅 **Impala **文档。
## 概念和术语
**Columnar Data Store**(列式数据存储)
**Kudu** 是一个 _**columnar data store**(列式数据存储)_。列式数据存储在强类型列中。由于几个原因,通过适当的设计,**Kudu** 对 **analytical**(分析)或 **warehousing**(数据仓库)工作会非常出色。
**Read** **Efficiency**(高效读取)
对于分析查询,允许读取单个列或该列的一部分同时忽略其他列,这意味着您可以在磁盘上读取更少块来完成查询。与基于行的存储相比,即使只返回几列的值,仍需要读取整行数据。
**Data Compression**(数据压缩)
由于给定的列只包含一种类型的数据,基于模式的压缩比压缩混合数据类型(在基于行的解决方案中使用)时更有效几个数量级。结合从列读取数据的效率,压缩允许您在从磁盘读取更少的块时完成查询。请参阅 [数据压缩](http://kudu.apache.org/docs/schema_design.html#encoding)
**Table**(表)
一张 _**talbe** _是数据存储在 **Kudu** 的位置。表具有 **schema **和全局有序的 **primary** **key**(主键)。**table** 被分成称为 **tablets** 的 **segments**。
**Tablet**
一个 **tablet** 是一张 **table** 连续的 **segment**,与其它数据存储引擎或关系型数据库中的 _**partition**_(分区)相似。给定的 **tablet** 冗余到多个 **tablet** 服务器上,并且在任何给定的时间点,其中一个副本被认为是 **leader tablet**。任何副本都可以对读取进行服务,并且写入时需要在为 **tablet **服务的一组 **tablet server**之间达成一致性。
**Tablet** **Server**
一个 **tablet** **server** 存储 **tablet** 和为 **tablet **向 **client **提供服务。对于给定的 **tablet**,一个 **tablet server** 充当 leader,其他 **tablet server** 充当该 **tablet **的 **follower** 副本。只有 **leader** 服务写请求,然而 **leader** 或 **followers** 为每个服务提供读请求。**leader** 使用 [Raft Consensus Algorithm](http://kudu.apache.org/docs/#raft) 来进行选举 。一个 **tablet** **server** 可以服务多个 **tablets** ,并且一个 **tablet** 可以被多个 **tablet** **servers** 服务着。
**Master**
该 **master** 保持跟踪所有的 **tablets**,**tablet** **servers**,[Catalog Table](http://kudu.apache.org/docs/#catalog_table) 和其它与集群相关的 **metadata**。在给定的时间点,只能有一个起作用的 **master**(也就是 **leader**)。如果当前的 **leader** 消失,则选举出一个新的 **master**,使用 [Raft Consensus Algorithm](http://kudu.apache.org/docs/#raft) 来进行选举。
**master** 还协调客户端的 **metadata operations**(元数据操作)。例如,当创建新表时,客户端内部将请求发送给 **master**。** master **将新表的元数据写入** catalog table**,并协调在 **tablet server** 上创建 **tablet** 的过程。
所有 **master** 的数据都存储在一个 **tablet** 中,可以复制到所有其他候选的 **master**。
**tablet** **server** 以设定的间隔向 **master** 发出心跳(默认值为每秒一次)。
**Raft Consensus Algorithm**
**Kudu **使用 [Raft consensus algorithm](https://raft.github.io/) 作为确保常规 **tablet** 和 **master** 数据的容错性和一致性的手段。通过 **Raft**,**tablet** 的多个副本选举出_ **leader**_,它负责接受以及复制到_ **_follower _**_副本的写入。一旦写入的数据在大多数副本中持久化后,就会向客户确认。给定的一组 `N `副本(通常为 **3** 或 **5** 个)能够接受最多`**(N - 1)/2** `错误的副本的写入。
**Catalog Table(目录表)**
_ **catalog** **talbe **_是 **Kudu** 的 **metadata**(元数据中)的中心位置。它存储有关 **tables** 和 **tablets** 的信息。该 **catalog table**(目录表)可能不会被直接读取或写入。相反,它只能通过客户端 **API** 中公开的元数据操作访问。**catalog table** 存储两类元数据。
**Tables**
**table schemas**, **locations**, **and states**(表结构,位置 和状态)
**Tablets**
现有 **tablet** 的列表,每个 **tablet 的**副本所在哪些 **tablet server**,**tablet** 的当前状态以及开始和结束的 **keys**(键)。
**Logical Replication**(逻辑复制)
**Kudu** 复制操作,不是磁盘上的数据。这被称为 _**logical replication**(__逻辑复制)_,而不是 _**physical replication**(__物理复制)_。这有几个优点 :
* 虽然 **insert**(插入)和 **update**(更新)确实通过网络传输数据,**deletes**(删除)不需要移动任何数据。**delete**(删除)操作被发送到每个 **tablet** **server**,它在本地执行删除。
* 物理操作,如 **compaction**,不需要通过 **Kudu **的网络传输数据。这与使用 **HDFS **的存储系统不同,其中 **blocks** (块)需要通过网络传输以满足所需数量的副本。
* **tablet** 不需要在同一时间或相同的时间表上执行压缩,或者在物理存储层上保持同步。这会减少由于压缩或大量写入负载而导致所有 **tablet server** 同时遇到高延迟的机会。
## 架构概述
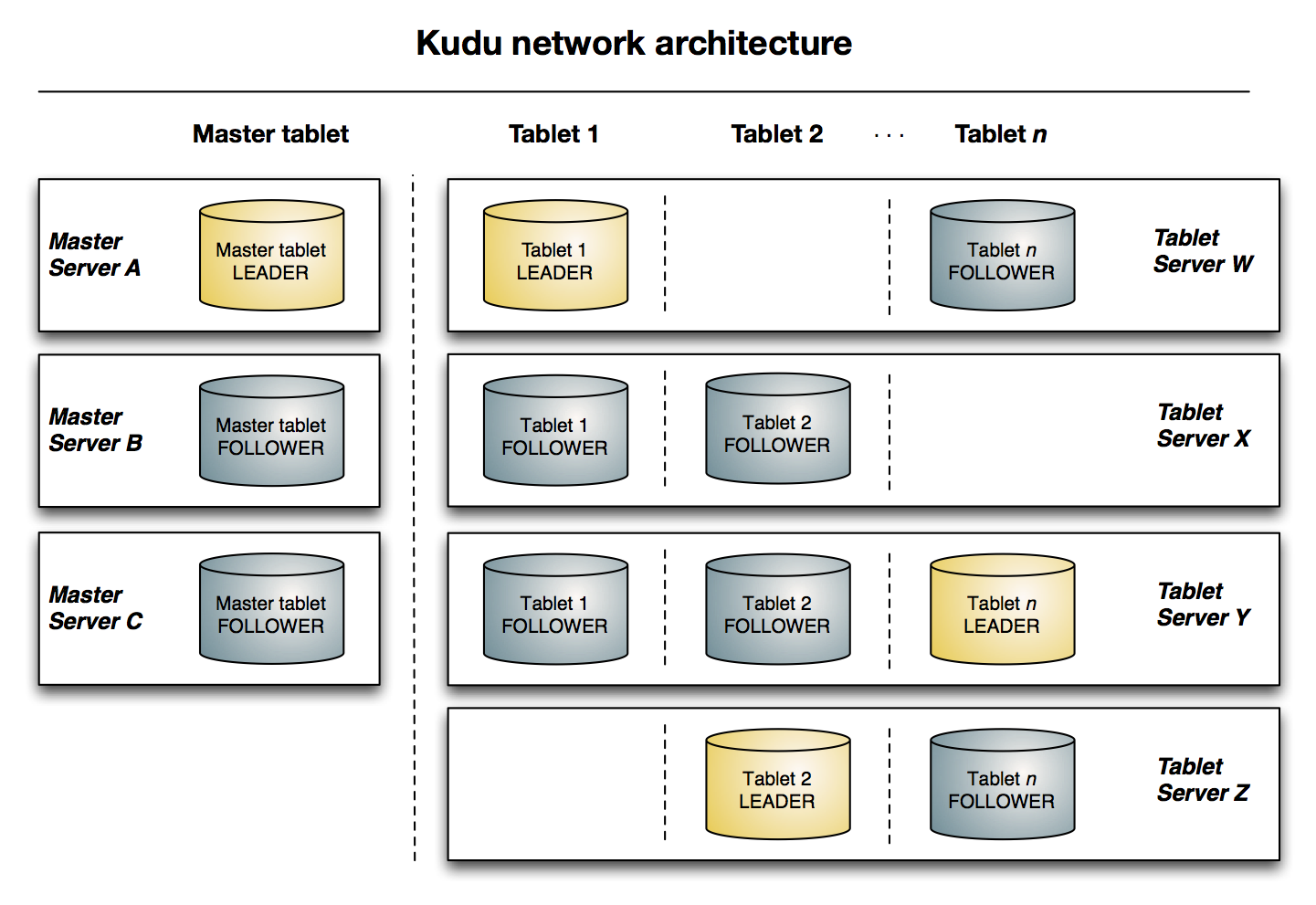
下图显示了一个具有三个 **master** 和多个 **tablet** **server** 的 **Kudu** 集群,每个服务器都支持多个 **tablet**。它说明了如何使用 **Raft** 共识来允许 **master** 和 **tablet** **server** 的 **leader** 和 f **ollow**。此外,**tablet server** 可以成为某些 **tablet** 的 **leader**,也可以是其他 **tablet** 的 **follower**。**leader** 以金色显示,而 **follower** 则显示为蓝色。
## 案例示例
**Streaming Input with Near Real Time Availability**(具有近实时可用性的流输入)
数据分析中的一个共同挑战就是新数据快速而不断地到达,同样的数据需要靠近实时的读取,扫描和更新。Kudu 通过高效的列式扫描提供了快速插入和更新的强大组合,从而在单个存储层上实现了实时分析用例。
**Time-series application with widely varying access patterns**(具有广泛变化的访问模式的时间序列应用)
**time-series**(时间序列)模式是根据其发生时间组织和键入数据点的模式。这可以用于随着时间的推移调查指标的性能,或者根据过去的数据尝试预测未来的行为。例如,时间序列的客户数据可以用于存储购买点击流历史并预测未来的购买,或由客户支持代表使用。虽然这些不同类型的分析正在发生,插入和更换也可能单独和批量地发生,并且立即可用于读取工作负载。**Kudu** 可以用 **scalable** (可扩展)和 **efficient** (高效的)方式同时处理所有这些访问模式。由于一些原因,**Kudu** 非常适合时间序列的工作负载。随着 **Kudu **对基于 **hash** 的分区的支持,结合其对复合 **row** **keys**(行键)的本地支持,将许多服务器上的表设置成很简单,而不会在使用范围分区时通常观察到“**hotspotting**(热点)”的风险。**Kudu** 的列式存储引擎在这种情况下也是有益的,因为许多时间序列工作负载只读取了几列,而不是整行。 过去,您可能需要使用多个数据存储来处理不同的数据访问模式。这种做法增加了应用程序和操作的复杂性,并重复了数据,使所需存储量增加了一倍(或更糟)。**Kudu** 可以本地和高效地处理所有这些访问模式,而无需将工作卸载到其他数据存储。
**Predictive** **Modeling**(预测建模) 数据科学家经常从大量数据中开发预测学习模型。模型和数据可能需要在学习发生时或随着建模情况的变化而经常更新或修改。此外,科学家可能想改变模型中的一个或多个因素,看看随着时间的推移会发生什么。在 **HDFS **中更新存储在文件中的大量数据是资源密集型的,因为每个文件需要被完全重写。在 **Kudu**,更新发生在近乎实时。科学家可以调整值,重新运行查询,并以秒或分钟而不是几小时或几天刷新图形。此外,批处理或增量算法可以随时在数据上运行,具有接近实时的结果。
**Combining Data In Kudu With Legacy Systems**(结合 **Kudu** 与遗留系统的数据)
公司从多个来源生成数据并将其存储在各种系统和格式中。例如,您的一些数据可能存储在 **Kudu**,一些在传统的 **RDBMS **中,一些在 **HDFS **中的文件中。您可以使用 **Impala **访问和查询所有这些源和格式,而无需更改旧版系统。
## 下一步
* [Kudu 入门指南](/pages/viewpage.action?pageId=10813610)
* [安装指南](/pages/viewpage.action?pageId=10813613)
