
# 理解 Storm Topology 的 Parallelism(并行度)
## 什么让 topology(拓扑)可以运行: worker 进程, executors(执行器)和 tasks(任务)
Storm 区分以下 3 个主要的实体, 它们在 Storm 集群中用于实际的运行 topology(拓扑):
1. Worker 进程
2. Executors(线程)
3. Tasks
这是一个简单的例子, 以说明他们之间的关系
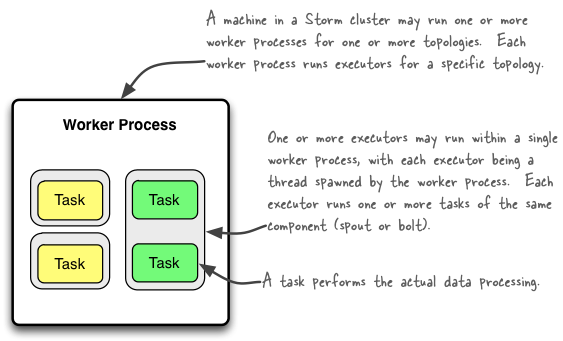
一个 _worker 进程_ 执行一个 topology(拓扑)的子集. 一个 worker 进程属于一个指定 topology(拓扑), 并且针对该 topology 的一个或多个组件(spouts 或 bolts)来说会运行一个或更多的 executors(执行器). 一个正在运行的 topology 由许多这样的进程组成, 它们运行在 Storm 集群的多个机器上.
一个 _executor(执行器)_ 是一个线程, 它是由 worker 进程产生的. 它可能针对相同的组件(spout 或 blot)运行一个或多个 tasks(任务).
一个 _task_ 执行实际的数据处理 - 在您代码中实现的每个 spout 或 bolt 在整个集群上都执行了许多的 taskk(任务). 组件的 task(任务)数量在 topology(拓扑)的整个生命周期中总是相同的, 但组件的 executors(线程)数量可能会随时间而变化. 这意味着以下条件成立: `#threads ≤ #tasks`. 默认情况下, 默认情况下,tasks(任务)数量与 executors(执行器)设置成一样, 例如. Storm 在每个线程上运行一个 task(任务).
## 配置 topology 的 parallelism(并行度)
请注意, 在 Storm 的术语中, "parallelism(并行度)" 特别用于描述所谓的 _parallelism hint_, 它表示组件的 executor(线程)的初始化数量. 在本文档中, 虽然我们在一般意义上使用术语 "parallelism(并行度)" 来描述如何配置的不仅只有 executor(执行器)的数量, 还可以配置 worker 进程的数量以及 Storm topology 的 tasks(任务)数量. We will specifically call out when "parallelism" is used in the normal, narrow definition of Storm.
以下部分概述了各种配置选项以及如何在代码中设置它们. 尽管设置这些选项有多种方法, 表中只列出了其中的一些选项. Storm 目前有以下 [配置设置的优先顺序](Configuration.html): `defaults.yaml` < `storm.yaml` < topology 级别指定的配置 < 内部 component(组件)指定的配置 < 外部 component(组件)指定的配置.
### worker 进程的数量
* 描述: 在集群的机器中有多少个 worker 进程来 _针对 topology_ 以创建它.
* 配置选项: [TOPOLOGY_WORKERS](javadocs/org/apache/storm/Config.html#TOPOLOGY_WORKERS)
* 如何在代码中设置(示例):
* [Config#setNumWorkers](javadocs/org/apache/storm/Config.html)
### executors (线程)的数量
* 描述: _每个 component(组件)_ 产生多少个 executors(执行器).
* 配置选项: None (传递 `parallelism_hint` 参数到 `setSpout` 或 `setBolt`)
* 如何在代码中设置(示例):
* [TopologyBuilder#setSpout()](javadocs/org/apache/storm/topology/TopologyBuilder.html)
* [TopologyBuilder#setBolt()](javadocs/org/apache/storm/topology/TopologyBuilder.html)
* 参数现在指定了 bolt 的 executors(执行器)的初始化数量(不是 tasks).
### tasks(任务)的数量
* 描述: _per component_ 有多少个 tasks(任务)来创建他们.
* 配置选项: [TOPOLOGY_TASKS](javadocs/org/apache/storm/Config.html#TOPOLOGY_TASKS)
* 如何在代码中设置(示例):
* [ComponentConfigurationDeclarer#setNumTasks()](javadocs/org/apache/storm/topology/ComponentConfigurationDeclarer.html)
以下是在练习中显示这些设置的示例代码片段:
```
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
```
在上面的代码中,我们配置 了Storm 来运行 Bolt "GreenBolt", 其初始数量为两个 executor(执行器)和四个相关联的 tasks(任务). Storm 的每个 executor(线程)将会运行两个 tasks(任务). 如果您不显示的配置 tasks 的数量, Storm 将使用每个 executor 一个 task 的默认配置来运行它们.
## 运行 topology 的示例
下图显示了简单的 topology(拓扑)是如何运行的. 该 topology 由 3 个 components(组件)构成: 一个名为 `BlueSpout` 的 spout 和两个名为 `GreenBolt` 和 `YellowBolt` 的 bolts. 该组件链接, 使得 `BlueSpout` 将其输出发送到 `GreenBolt`, 它们将自己的输出发送到 `YellowBolt`.
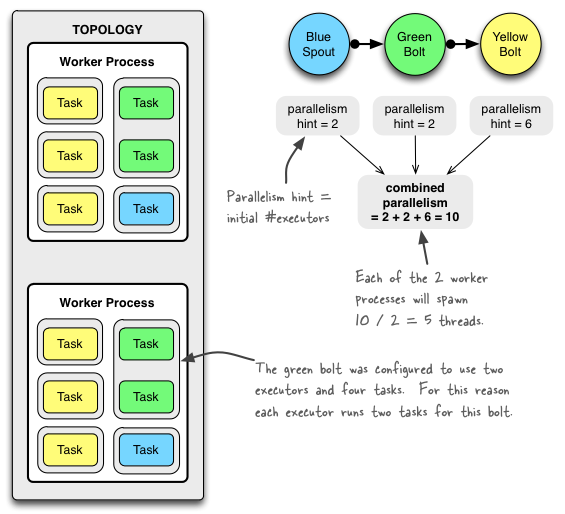
该 `GreenBolt` 按照上面的代码片段进行配置, 而 `BlueSpout` 和 `YellowBolt` 只设置了 parallelism hint(执行器数量). 以下是相关代码:
```
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2); // set parallelism hint to 2
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology(
"mytopology",
conf,
topologyBuilder.createTopology()
);
```
当然, Storm 还提供了额外的配置设置来控制 topology(拓扑)的并行度, 包括:
* [TOPOLOGY_MAX_TASK_PARALLELISM](javadocs/org/apache/storm/Config.html#TOPOLOGY_MAX_TASK_PARALLELISM): 此设置针对单个组件生成的 executor(执行器)的数量设置上限. 通常在测试期间使用它来限制在本地模式下运行 topology(拓扑)时产生的线程数. 您可以通过 [Config#setMaxTaskParallelism()](javadocs/org/apache/storm/Config.html#setMaxTaskParallelism(int)) 来设置此选项.
## 如何改变正在运行中的 topology 的并行度
Storm 的一个很好的特性是可以增加或减少 worker 进程 和/或 executor(执行器)的数量, 而无需重新启动集群或 topology(拓扑). 这样做的行为称之为 rebalancing(重新平衡).
您有两个选项来 rebalance(重新平衡)一个 topology(拓扑):
1. 使用 Storm web UI 来 rebalance(重新平衡)指定的 topology.
2. 使用 CLI 工具 storm rebalance, 如下所示.
以下是一个使用 CLI 工具的示例:
```
## 重新配置 topology "mytopology" 以使用 5 个 worker 进程,
## 该 spout "blue-spout" 要使用 3 个 executors(执行器)并且
## 该 bolt "yellow-bolt" 要使用 10 executors(执行器).
$ storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10
```
## 参考文献
* [概念](Concepts.html)
* [配置](Configuration.html)
* [在生产集群上运行 topologies(拓扑)](Running-topologies-on-a-production-cluster.html)]
* [Local mode(本地模式)](Local-mode.html)
* [教程](Tutorial.html)
* [Storm API 文档](javadocs/), most notably the class `Config`
- Storm 基础
- 概念
- Scheduler(调度器)
- Configuration
- Guaranteeing Message Processing
- 守护进程容错
- 命令行客户端
- Storm UI REST API
- 理解 Storm Topology 的 Parallelism(并行度)
- FAQ
- Layers on Top of Storm
- Storm Trident
- Trident 教程
- Trident API 综述
- Trident State
- Trident Spouts
- Trident RAS API
- Storm SQL
- Storm SQL 集成
- Storm SQL 示例
- Storm SQL 语言参考
- Storm SQL 内部实现
- Flux
- Storm 安装和部署
- 设置Storm集群
- 本地模式
- 疑难解答
- 在生产集群上运行 Topology
- Maven
- 安全地运行 Apache Storm
- CGroup Enforcement
- Pacemaker
- 资源感知调度器 (Resource Aware Scheduler)
- 用于分析 Storm 的各种内部行为的 Metrics
- Windows 用户指南
- Storm 中级
- 序列化
- 常见 Topology 模式
- Clojure DSL
- 使用没有jvm的语言编辑storm
- Distributed RPC
- Transactional Topologies
- Hooks
- Storm Metrics
- Storm 状态管理
- Windowing Support in Core Storm
- Joining Streams in Storm Core
- Storm Distributed Cache API
- Storm 调试
- 动态日志级别设置
- Storm Logs
- 动态员工分析
- 拓扑事件检查器
- Storm 与外部系统, 以及其它库的集成
- Storm Kafka Integration
- Storm Kafka 集成(0.10.x+)
- Storm HBase Integration
- Storm HDFS Integration
- Storm Hive 集成
- Storm Solr 集成
- Storm Cassandra 集成
- Storm JDBC 集成
- Storm JMS 集成
- Storm Redis 集成
- Azue Event Hubs 集成
- Storm Elasticsearch 集成
- Storm MQTT(Message Queuing Telemetry Transport, 消息队列遥测传输) 集成
- Storm MongoDB 集成
- Storm OpenTSDB 集成
- Storm Kinesis 集成
- Storm Druid 集成
- Storm and Kestrel
- Container, Resource Management System Integration
- Storm 高级
- 针对 Storm 定义一个不是 JVM 的 DSL
- 多语言协议
- Storm 内部实现
- 翻译进度