
> ### 跳跃表
* 跳跃表的优点是维持结构平衡的成本比较低,完全依靠随机。二叉查找树在多次插入删除后,需要`rebalance`来重新调整结构平衡。
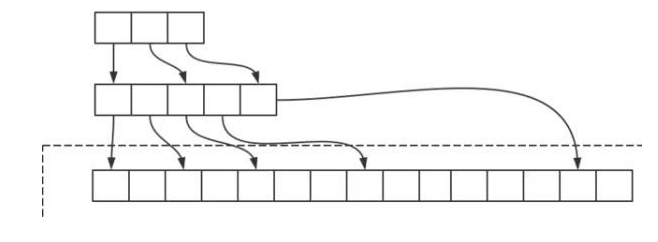
> ### 操作节点
* 新节点和各层索引节点逐一比较,确定原链表的插入位置。O(logN)
* 把索引插入到原链表。O(1)
* 利用抛硬币的随机方式,决定新节点是否提升为上一级索引。结果为“正”则提升并继续抛硬币,结果为“负”则停止。O(logN)
* 总体上,跳跃表插入操作的时间复杂度是O(logN),而这种数据结构所占空间是2N,既空间复杂度是 O(N)。
* 删除节点,自上而下,查找第一次出现节点的索引,并逐层找到每一层对应的节点。O(logN)。跳跃表删除操作的时间复杂度是O(logN)。
<br/>
<br/>
***
参考:
[漫画算法:什么是跳跃表?](http://blog.jobbole.com/111731/)
[Redis为什么用跳表而不用平衡树?](https://redisbook.readthedocs.io/en/latest/internal-datastruct/skiplist.html)
- asD
- Java
- Java基础
- Java编译器
- 反射
- collection
- IO
- JDK
- HashMap
- ConcurrentHashMap
- LinkedHashMap
- TreeMap
- 阻塞队列
- java语法
- String.format()
- JVM
- JVM内存、对象、类
- JVM GC
- JVM监控
- 多线程
- 基础概念
- volatile
- synchronized
- wait_notify
- join
- lock
- ThreadLocal
- AQS
- 线程池
- Spring
- IOC
- 特性介绍
- getBean()
- creatBean()
- createBeanInstance()
- populateBean()
- AOP
- 基本概念
- Spring处理请求的过程
- 注解
- 微服务
- 服务注册与发现
- etcd
- zk
- 大数据
- Java_spark
- 基础知识
- Thrift
- hdfs
- 计算机网络
- OSI七层模型
- HTTP
- SSL
- 数据库
- Redis
- mysql
- mybatis
- sql
- 容器
- docker
- k8s
- nginx
- tomcat
- 数据结构/算法
- 排序算法
- 快排
- 插入排序
- 归并排序
- 堆排序
- 计算时间复杂度
- leetcode
- LRU缓存
- B/B+ 树
- 跳跃表
- 设计模式
- 单例模式
- 装饰者模式
- 工厂模式
- 运维
- git
- 前端
- thymeleaf
- 其他
- 代码规范
- work_project
- Interview