# 【学习人工智能】线型回归和sigmoid回归(附实战)
程序猿
**深度学习篇:线型回归和sigmoid回归**
**本篇难度系数:2星**
本来想给这篇文章写个难度1星,但联想到本人较为弱势的数学,姑且还是给个2星吧。sigmoid回归是logistic回归的一种,而logistic regression和线型回归也是近亲,本质都是一个东西。那么说回归回归,回归是个啥?
其实很好理解,通俗意义上讲,线型回归就是让你找一条直线把两种(或多种)类型的标签分为两类(或多种),**而sigmoid回归就是让你找一条直线,把经过sigmoid化后的输入数据与模型的乘积分成两类。**
有同学立刻问,什么是sigmoid,为什么要用sigmoid。
这个问题要从sigmoid是什么开始说起。
sigmoid函数并不难,就是这么个东西。
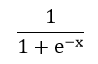
**注意,x可以是数,可以是向量,sigmoid一个向量的意思,就是分别对期中的每一个元素做sigmoid。**那么为什么要搞这么个东西。因为这个东西长这样。
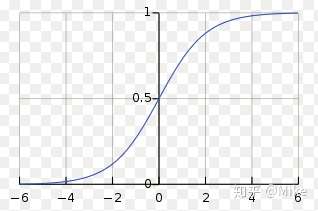
比如你的x>8,那么,那么sigmoid可以基本上把它归为1类,但是如果你的函数是y=x,这个label也就是y可就是8了,这是很不方便的。有同学又说,为什么不搞个符号函数,
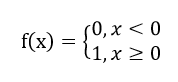
这是好问题,答案是,很难求导。又有人问,为什么要求导?我们不用急,接着往下看。
sigmoid回归问题最重要的几个公式:
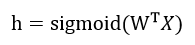
这个好理解,就是一个简单的矩阵相乘公式。这个h是在算概率呢。
那么出现 label = 1的标签的时候,其概率为h,出现 label = 0 的标签的时候,其概率为 1-h,即:
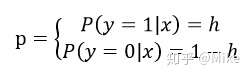
因此我们可以得到综合概率函数:
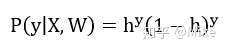
由这个综合概率函数,我们可以得到似然函数
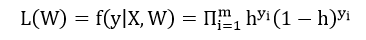
这个东西简单,这个东西不就是你把所有的样本给乘起来,我们默认这些样本是独立同分布的。共有m个样本。
下面搞了个对数,为的是化简的时候能把累加乘 (\\Pi) 改成累加加 (\\sum)
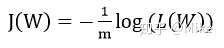
然后对这个东西去求导,原谅我实在不想一步一步地去求导了,我直接贴别人的公式了。
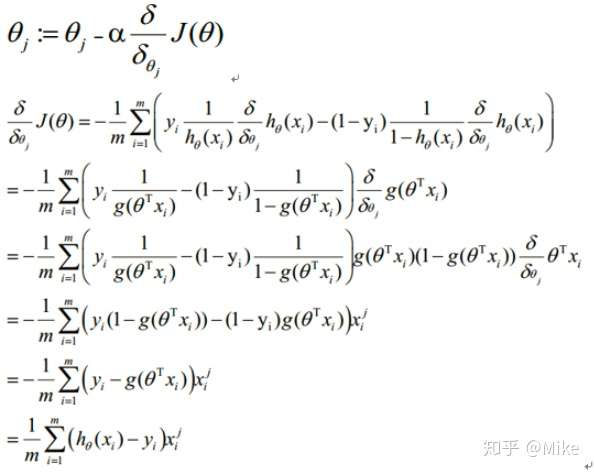
请注意,上面的theta就是我自己公式里面的W,这是一个东西。**这里应该有一个问题,那就是我们为什么要对 J 去求导,我们可以基本上认为,J就代表那个似然函数,我们当然希望我们的模型可以尽最大的可能性去往 J 上去贴,换句话说,我们希望我们的模型尽可能的准,也就是求最大值,而导数可以帮我们逐步地找到这个最大值。**
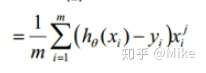
这个公式是元素的形式,对我们来说还是太复杂了,我们把它转化一下。
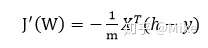
于是,更新公式为:
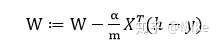
**对于编程来说,我们需要这个就够了。**
**(1)one hot**
首先我们写一个 make one hot 函数:
~~~text
def make_one_hot(data1, out):
return (np.arange(out)==data1[:,None]).astype(np.integer)
~~~
这个函数有什么用?比如说你的输入是 y = \[1,0,1\].T
他会给你转变成:
~~~text
[[0 1]
[1 0]
[0 1]]
~~~
没看出规律我们再来一个:
y = \[1,2,4,0\].T
他会给你转变成:
\[\[0 1 0 0 0\]
\[0 0 1 0 0\]
\[0 0 0 0 1\]
\[1 0 0 0 0\]\]
这回应该看出规律了吧。
**(2) sigmoid**
~~~python3
def sigmoid( x):
return 1.0/(1+np.exp(-x))
~~~
没什么可说的。
**(3) logistic regression**
~~~python3
def logisticRegression(x, y):
m,n = np.shape(x)
alpha = 0.001
maxCycles = 5000
w = np.ones((n,2))
for k in range(maxCycles):
h = sigmoid(x.dot(w))
error = (h - y)
w = w - alpha * x.transpose().dot(error)
return w
~~~
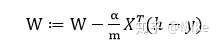
**请注意这句话(数学公式)在代码中哪一个位置出现**。编程是容易的,因为我们仅仅使用数学推导的结论就可以了。注意:m是常数,我们直接用\\alpha 去替代 \\alpha/m, 这是没有问题的。
**(4)准确率检测**
~~~text
def acc(xs,ys,w):
p = sigmoid(xs.dot(w))
p = np.argmax(p,1)
s = 0
for i in range(len(p)):
if p[i] == np.argmax(ys[i]):
s += 1
return s/len(p)
~~~
也没什么可以说的,就是比对吻合的样本除以总数的百分比。
总结一下,其实logistic regression最核心的东西就是对**极大似然**和**梯度下降**的这两个东西的运用。**而极大似然的本质就是根据样本也就是x的分布规律虚拟出一个模型出来**。(这个模型是现实中不存在的,但是人们认为这个模型存在所以使得样本符合某种规律),然后我们又通过 **梯度下降** 的方法不断地微调我们的模型 W 能够使得似然概率尽可能的大,而且似然函数我是存在一个极大值点的,也就是我们输出的logit能尽可能的吻合真正的label。当梯度下降过程收敛的时候,我们的模型达到了最优的情况,从而达到有效分类的目的,这就是逻辑回归的本质。
**另外:那些注重学术探讨的人,懂得就事论事的人是朋友,是会受到欢迎的人;那些自己什么有价值的东西都说不出来,在一旁指点江山的人是渣滓,是会被社会淘汰的**
