
# 查看
```
语句 说明
SHOW DATABASES; 查看展示所有数据库
SHOW TABLES; 查看展示数据库中数据表
SHOW STATUS; 查看服务器状态信息
SHOW STATUS \G; 查看服务器状态信息,并整理
SHOW TABLES STATUS \G; 查看数据表状态信息,并整理
SHOW CREATE DATABASE 库名; 查看创建的数据库
SHOW CREATE TABLE 表名; 查看创建表的语句
SHOW ENGINES; 查看引擎
SHOW VARIABLES LIKE 'deafult_storage_engine'; 查看默认存储引擎
SHOW VARIABLES LIKE 'deafult%'; 查看以'default'为开头的变量
SHOW GRANTS; 查看授权用户(所有用户或特定用户)的安全权限
```
# 创建
```
语句 说明
CREATE DATABASE 库名; 创建数据库
CREATE DATABASE 库名 CHARSET = 'utf8'; 创建库,设置编码为utf8类型
CREATE DATABASE IF NOT EXISTS 库名; 如果库名不存在,则创建
CREATE TABLE 表名(列名1 数据类型 约束条件 注释,列名2 数据类型 约束条件 注释.....); 创建表
CREATE TABLE IF NOT EXISTS 库名(列名1 数据类型 约束 注释,列名2 数据类型 约束 注释....,PRIMARY KEY(列名n))ENGINE = InnoDB DEFAULT CHARSET = 'utf8';
创建表,如果不存在,将表主键设置为列名n,存储引擎为InnoDB(为默认存储引擎),默认编码设置为'UTF8'
```
```
注释: 1.如果你不想字段为NULL,可以设置字段属性为NOT NULL,在操作数据库时如果输入该字段的数据为NULL,就会报错
2.AUTO_INCREMENT 定义列为自增属性,一般用于主键,数值会自动+1,自增时随着前一位列的数值而言
3.PRIMARY KEY 关键字用于定义列为主键,可以直接跟在列后面设置,也可以在数据表末尾说明。也可以使用多列来定义主键,列间用逗号分隔
4.ENGINE 设置存储引擎,CHARSET 设置编码
```
# 插入
```
语句 说明
INSERT INTO 表名(列名1,列名2,列名3...) VALUES(value1,value2,value3...); 数据表中插入单条数据
INSERT INTO 表名(列名1,列名2,列名3...) VALUES(valueA1,valueA2,valueA3...),(valueB1,valueB2,valueB3...); 数据表中插入多条数据
注释: 如果列中约束有NULL或者默认值的,在插入数据中表后面的列可以不跟列名,后面values中同样也不跟值,在输出后,该列会自动显示NULL或者默认值
```
# 查询
**注:** MySQL数据库中查询数据通用为SELECT语法
> * 查询语句中可以使用一个或者多个表,表之间使用','分隔,并使用WHERE语句来设定查询条件
> * SELECT命令可以读取一条或者多条记录
> * 使用'\*'来替代其他字段,SELECT语句会返回表中所有列数据
> * 使用'WHERE'语句来包含任何条件
> * 使用'LIMIT'属性来设定返回的记录数
| 语句 | 说明 |
| --- | --- |
| SELECT \* FROM 表名; | 查询表中所有信息 |
| SELECT 列1,列2,列3... FROM 表名; | 查询表中列1,列2,列3...等字段的信息 |
| SELECT \* FROM 表名 WHERE 条件; | 查询数据表中该条件语句下所有信息 |
| SELECT \* FROM 表名 WHERE 列 LIKE 'X%'; | 查询列中以'X'开头的所有数据信息 |
| SELECT \* FROM 表名 WHERE 列 BETWEEN 'M' AND 'N'; | 查询数据表中列在条件M和N之间的所有数据信息 |
| SELECT \* FROM 表名 WHERE 列 in (M,N); | 查询数据表中列在固定条件M个N中的所有数据 |
| SELECT DISTINCT 列 FROM 表名; | 查询去重值(比如查看都有多大的年龄,年龄中都有同样的20岁,去重后只会显示一个20岁的) |
| SELECT \* FROM 表名 WHERE 列1 >//</= 值2; | 查看数据表中范围条件数据 |
| SELECT \* FROM 表名 WHERE 列 = 值1 OR 列 = 值2; | 查询数据表中条件不同值的数据 |
| SELECT \* FROM 表名 ORDER BY 列; | 查询数据表中值通过列排序结果 |
| SELECT \* FROM 表名 ORDER BY 列 DESC; | 查询表下排序结果降序 |
| SELECT \* FROM 表名 LIMIT M; | 查询表下数据范围,前M行字段数据 |
| SELECT \* FROM 表名 LIMIT M,N; | 查询从M行开始下的N行数据 |
| SELECT name as zzz FROM 表名; | 别名查询表下数据 |
**注:** 上述'\*'均可由数据表中列替换,若要查找几项列的信息,则列之间用','隔开;如:SELECT 列1,列2,列3...FROM 表 WHERE 条件;
## 修改
**注:** MySQL数据表中修改或更新数据,通常使用UPDATE语句
> * 可以同时更新一个或多个字段
> * 可以在WHERE条件中指定任何条件列的修改
> * 可以在一个单独表中同时更新数据
> * 可以更新数据表中所有数据
| 语句 | 说明 |
| --- | --- |
| UPDATE 表名 SET 列名1 = 值1; | 将表中所有信息的列1都进行修改 |
| UPDATE 表名 SET 列1 = 新值1,列2 = 新值2... WHERE 条件 | 将表中特定条件的列信息修改;修改特定的列内容,WHERE后面跟条件语句,后跟条件语句和查询语句句式一样 |
| UPDATE 表名 SET 列 =REPLACE(lie,'old\_sting','new\_string') WHERE 条件; | 将条件语句下列中特定字符串改为其他字符串 |
| ALTER TABLE 表名 MODIFY 列名 新数据类型 新约束 新注释; | 修改列数据类型,约束 |
# 添加
| 语句 | 说明 |
| --- | --- |
| ALTER TABLE 表名 ADD 列名 数据类型 约束 注释; | 添加列 |
| ALTER TABLE 表名 ADD COLUMN 列名 数据类型 约束 注释; | 新增列 |
| ALTER TABLE 表名 ADD 新增列名 数据类型 约束 注释 AFTER 列名N; | 新增列在列N之后 |
ALTER TABLE 表名 ADD 列名 数据类型 约束 注释 FIRST;将列添加到表首
# 重命名
| 语句 | 说明 |
| --- | --- |
| REMARE TABLE 原表名 TO 新表名; | 重命名表 |
| ALTER TABLE 原表名 REMARE 新表名; | 重命名表 |
| ALTER TABLE 原表名 REMARE TO 新表名; | 重命名表 |
| ALTER TABLE 表名 CHANGE 原列名 新列名 数据类型 约束条件 注释; | 重命名列,并对列做修改 |
# 删除
删除表时要注意,执行完删除后,数据都会消失
| 语句 | 说明 |
| --- | --- |
| DROP DATABASE 库名; | 删除数据库 |
| DROP DATABASE IF EXISTS 库名; | 如果数据库存在则删除 |
| DROP TABLE 表名; | 删除数据表全部数据和表结构,立刻释放磁盘空间,不管时默认存储引擎InnoDB还是MyISAM |
| TRUNCATE TABLE 表名; | 清楚表中数据,但保留表结构 |
| ALTER TABLE 表名 DROP 列名; | 删除表中指定某列 |
| ALTER TABLE 表名 DROP CULUMN 列; | 删除指定列 |
| DELETE FROM 表名 WHERE 条件; | 删除表中指定该条件的信息(where条件和查询条件句式一样) |
> * **注:** 当不用该表时,用DROP
> * 当要保留表结构,但要清除表中所有记录时,用TRUNCATE
> * 要删除部分记录时,用DELETE
# 其他
| 语句 | 说明 |
| --- | --- |
| DESC 表名; | 展示表结构 |
| PRIMARY KEY(列) | 将列设置为主键,可以在创建表开头使用,也可以在末尾使用 |
| AUTO\_INCREMENT | 递增,一般用于主键,数值+1,以上一个数值为基础 |
## 退出
| 语句 | 说明 |
| --- | --- |
| EXIT/QUIT/\\q | 退出数据库 |
# 数据库操作
## 创建数据库:
~~~
>CREATE DATABASE db_name; //db_name为数据库名
>CREATE DATABASE IF NOT EXISTS db_name default character set utf8 COLLATE utf8_general_ci; //条件创建数据库
mysqladmin -u root -p create RUNOOB
~~~
## 删除数据库:
~~~
>DROP DATABASE db_name;
>DROP DATABASE IF EXISTS db_name;
mysqladmin -u root -p drop RUNOOB
~~~
## 查看数据库:
~~~
>SHOW DATABASES;
~~~
## 选择数据库:
~~~
>USE db_name;
~~~
## 修改数据库
~~~
>ALTER DATABASE my_db CHARACTER SET latin1; //修改数据库字符编码
~~~
# 表的操作:
## 1、创建表:
(1).使用SQL语句创建
~~~
>CREATE TABLE IF NOT EXISTS tb_name(
fid INT(11) NOT NULL DEFAULT '0', //fid INT类型显示11位,非空,默认值为0
......................................
PRIMARY KEY(id) //主键
)ENGINE=InnoDB DEFAULT CHARSET=utf8 //设置表的存储引擎和默认编码(防止数据库中文乱码),一般常用InnoDB和MyISAM;InnoDB可靠,支持事务;MyISAM高效不支持全文检索.
~~~
(2).根据现有的表来创建并插入指定条件的数据
~~~
>CREATE TABLE tb_name2 SELECT * FROM tb_name;
~~~
或者部分复制:
~~~
>CREATE TABLE tb_name2 SELECT id,name FROM tb_name;
~~~
(3).创建临时表:
~~~
>CREATE TEMPORARY TABLE tb_name(这里和创建普通表一样);
~~~
## 2、查看表
(1).查看数据库中可用的表
~~~
>SHOW TABLES;
~~~
(2).查看表结构:
~~~
>DESC tb_name;
也可以使用:
>SHOW COLUMNS in/from tb_name;
~~~
## 3、删除表:
~~~
>DROP [ TEMPORARY ] TABLE [ IF EXISTS ] tb_name[ ,tb_name2.......];
~~~
实例:
~~~
>DROP TABLE IF EXISTS tb_name; //存在则删除,不存在不操作
~~~
## 4、更改表:
~~~
>ALTER TABLE tb_name ADD[CHANGE,RENAME,DROP] [after 插入位置]...要更改的内容...
~~~
实例:
~~~
>ALTER TABLE tb_name ADD COLUMN address varchar(80) NOT NULL AFTER `column_name`;
>ALTER TABLE tb_name DROP COLUMN address;
>ALTER TABLE tb_name CHANGE scoer score SMALLINT(4) NOT NULL; //更改列名称或列字
>ALTER TABLE name_old RENAME name_new;
~~~
段类型(注:这里字段类型与表字段类型不一致会修改表字段类型)5、增加删除主键
~~~
>ALTER TABLE tb_name ADD primary key (id);
>ALTER TABLE tb_name DROP primary key;
~~~
## 三、数据增删查改
1、插入数据
~~~
>INSERT INTO tb_name(id,name,score)VALUES(NULL,'张三',140),(NULL,'张四',178),(NULL,'张五',134); //插入多条数据直接在后边加上逗号,主键id是自增的列,可以不用写。
>INSERT INTO tb_name(name,score) SELECT name,score FROM tb_name2;
~~~
2、更新数据
~~~
>UPDATE tb_name SET score=89,age=11 WHERE id=2; //修改多列使用”,”隔开
>UPDATE tablename SET columnName=NewValue [ WHERE condition ]
~~~
3、删除数据
~~~
>DELETE FROM tb_name WHERE id=3;
>DELETE FROM tb_name; //不带条件,则删除整张表数据
~~~
4、查询与条件控制(1).WHERE语句:
where的作用:在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数。
~~~
>SELECT * FROM tb_name WHERE id=3;
~~~
(2).HAVING语句:
having的作用:是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having条件过滤出特定的组,也可以使用多个分组标准进行分组。
~~~
>SELECT * FROM tb_name GROUP BY age HAVING count(*)>2 //按年龄分组,并筛选出同一年龄人数大于2的组数据
~~~
(3).相关条件控制符:=、>、、IN(1,2,3......)、BETWEEN a AND b、NOT、LIMITAND、ORLike()用法中
%:匹配任意个字符 \_:匹配一个字符(可以是汉字)IS NULL空值检测
~~~
>SELECT * FROM student WHERE fid >= 3 AND fid <= 5;
>SELECT * FROM student WHERE fid IN (2, 4, 5);
>SELECT * FROM student WHERE fid BETWEEN 2 AND 4;
>SELECT * FROM student WHERE fid = 3 OR fid = 4;
>SELECT * FROM student WHERE fname LIKE '%三' //查找fname内容含有三的数据
~~~
5.功能函数
(a).DISTINCT:数据去重,返回指定字段内容不重复的记录
~~~
>SELECT DISTINCT `age` FROM student; //返回学生年龄分布
~~~
(b).LIMIT:指定返回前几条或者中间某几行数据
\>SELECT \* FROM TABLE LIMIT \[OFFSET,\] ROWS | ROWS OFFSET OFFSETLIMIT可以用于强制SELECT返回指定的记录数。接受一个或两个数字参数,参数必须是一个整数常量。如果给定两个参数,第一个参数指定返回记录行的偏移量,第二个参数指定返回记录行的最大数目。初始记录行偏移量是0(而不是1):为了与PostgreSQL兼容,MySQL也支持句法:LIMIT #OFFSET #。
~~~
> SELECT * FROM student LIMIT 5,10; //检索记录行6-15 ,注意:10为偏移量
> SELECT * FROM student LIMIT 95,-1; //检索记录行 96-last.
//如果只给定一个参数,它表示返回最大的记录行数目:
> SELECT * FROM student LIMIT 5; //检索前 5 个记录行,也就是说,LIMIT n等价于 LIMIT 0,n。
~~~
如果你想得到最后几条数据可以多加个ORDER BY id DESC
(c).as别名
~~~
>SELECT fname AS "名字" FROM student;
>SELECT AVG(fchinese) AS "语文平均分" FROM score;
~~~
6、GROUP BY分组查询
所谓的分组就是将指定符合条件的数据划分到一个组,最终得到一个分组汇总表(1).条件使用Having;(2).排序使用ORDER BY : ORDER BY DESC|ASC=>按数据的降序/升序排列
~~~
>SELECT COUNT(*) FROM student GROUP BY `age` HAVING COUNT(*) > 2;
>SELECT fname,COUNT(age) AS "人数" FROM student GROUP BY fname;
~~~
7、联合查询用于把来自两个或多个表的行结合起来
(1).使用JOIN
JOIN 子句基于这些表之间的共同字段,把来自两个或多个表的行结合起来。
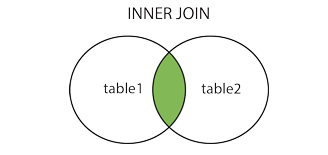
**INNER JOIN**
在表中存在至少一个匹配时返回行。
~~~
>SELECT student.fname,score.fchinese,score.english,score.fmatch FROM student INNER JOIN score ON student.fid = score.fid;
以上SQL等价于:
>SELECT a.fname,a.age,b.fchinese,b.english,b.fmatch FROM student a INNER JOIN score b WHERE a.fid = b.fid;
>SELECT a.fname,a.age,b.fchinese,b.english,b.fmatch FROM student a,score b WHERE a.fid = b.fid;
~~~
LEFT JOIN
从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为NULL。

~~~
>SELECT student.fname,score.fchinese,score.english,score.fmatch FROM student LEFT JOIN score ON student.fid = score.fid;
~~~
RIGHT JOIN
从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为NULL。

~~~
>SELECT student.fname,score.fchinese,score.english,score.fmatch FROM student RIGHT JOIN score ON student.fid = score.fid;
~~~
(2)、使用UNION
UNION
UNION用于合并两个或多个SELECT语句的结果集,并消去表中任何重复行。UNION内部的SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。同时,每条SELECT 语句中的列的顺序必须相同.
~~~
>SELECT * FROM student UNION SELECT * FROM score;
>SELECT * FROM student UNION SELECT * FROM infoext; //报ERROR,列数量不一致
~~~
UNION ALL
当ALL随UNION 一起使用时(即UNION ALL),不消除重复行
~~~
>SELECT * FROM student UNION ALL SELECT * FROM score;
~~~
8、MySQL的一些函数
(1)、字符串链接——CONCAT()
~~~
>SELECT CONCAT(fname, "==>", address) FROM student;
~~~
(2)、数学函数:AVG、SUM、MAX、MIN、COUNT;(3)、文本处理函数:TRIM、LOCATE、UPPER、LOWER、SUBSTRING(4)、运算符:+、-、\*、\\(5)、时间函数:DATE()、CURTIME()、DAY()、YEAR()、NOW().....
~~~
>UPDATE shop SET `fupdatetime` = NOW(); //更新shop表fupdatetime字段时间
~~~
(6)、空值处理
为了处理这种情况,MySQL提供了三大运算符:
**IS NULL:** 当列的值是NULL,此运算符返回true。
**IS NOT NULL:** 当列的值不为NULL,运算符返回true。
**:** 比较操作符(不同于=运算符),当比较的的两个值为NULL时返回true。
关于NULL的条件比较运算是比较特殊的.你不能使用= NULL或!= NULL在列中查找NULL值,在MySQL中,NULL值与任何其它值的比较(即使是NULL)永远返回false,即NULL = NULL返回false.
MySQL中处理NULL使用IS NULL和IS NOT NULL运算符。
~~~
>SELECT * FROM student WHERE fname != NULL; //返回NULL数据集
>SELECT * FROM student WHERE fname IS NOT NULL; //返回想要的数据
~~~
9、MySQL的正则表达式:Mysql支持REGEXP的正则表达式:>SELECT \* FROM tb\_name WHERE name REGEXP '^\[A-D\]' //找出以A-D为开头的name
模式描述^匹配输入字符串的开始位置。例如’^sw’可匹配swxxs或sw24dsf等$匹配输入字符串的结束位置。例如‘duan$’可匹配swduan或sssssduan等.匹配除 "\\n" 之外的任何单个字符。例如’[swd.an](http://swd.an)’可匹配swduan或swddan等\[...\]字符集合。匹配所包含的任意一个字符。例如, '\[a-z\]' 可以匹配字符a-z,\[0-9\]可匹配0-9。\[^...\]非字符集合。匹配除\[\]中之外的的任意字符。例如, '\[^abc\]' 可以匹配 "def" 等。p1|p2|p3匹配 p1 或 p2 或 p3。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。*匹配前面的子表达式零次或多次。例如,sw* 能匹配 "sw" 以及 "swsw"。\* 等价于{0,}。+匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zozo",但不能匹配 "z"。+ 等价于 {1,}。{n}n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。{n,m}m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。
注意,^有两个用法,一个是非,一个是文本的开始,用\[\]中表示非,否则是文本的开始。
使用的时候需要外面加一层\[\],例如\[\[:digit:\]\]
类说明\[:alnum:\]任意字母和数字(同\[a-zA-Z0-9\])\[:alpha:\]任意字母(同\[a-zA-Z\])\[:blank:\]空格和制表(同\[\\t\])\[:cntrl:\]ASCII控制字符(ASCII0到31和127)\[:digit:\]任意数字(同\[0-9\])\[:graph:\]和\[\[:print:\]\]相同,但不包含空格\[:lower:\]任意小写字母(同\[a-z\])\[:print:\]任意可打印字符\[:punct:\]即不在\[\[:alnum:\]\]又不在\[\[:cntrl:\]\]中的字符\[:space:\]包括空格在内的任意空白字符(同\[\\f\\n\\r\\t\\v\])\[:upper:\]任意大写字母(同\[A-Z\])\[:xdigit:\]任意16进制数字(同\[a-fA-F0-9\])
~~~
>SELECT * FROM student Where fname REGEXP 'swduan[[:digit:]]'; //可匹配swduan0-9
~~~
- stm32单片机
- arm体系结构和汇编
- arm交叉编译器安装
- gcc和cmake优化等级
- u-boot
- uboot简介
- uboot基础使用和命令操作
- uboot-spl编译和启动流程
- uboot-编译和启动流程
- uboot fdt设备树
- uboot驱动模型
- dm-gpio
- 内核移植
- linux patch
- 内核编译
- 驱动开发
- uboot传参到内核
- gpio pinctrl子系统
- 常用头文件和功能
- linux内核和内核编程
- 设备树教程
- 字符设备驱动
- 并发与竞争
- 阻塞和非阻塞
- Vpu/视频编解码
- I2C
- USB
- debugfs
- linux ethernet over usb
- 根文件系统构建
- buildroot
- ubuntu
- debia
- 嵌入式应用开发
- 热插拔事件管理
- hostapd创建热点
- netlink usb插拔
- mdev
- gpio使用
- 路由 功能配置 dhcp server nat
- linux获取cpu温度
- Qt编程
- 第三方库
- Jeston
- nano编译烧写
- jtop
- 数据库
- mysql
- 安装
- 常用sql操作
- mysql常用语句
- mysql常用命令