# 概论
自然语言处理(NLP)是计算机科学,人工智能,语言学关注计算机和人类(自然)语言之间的相互作用的领域。
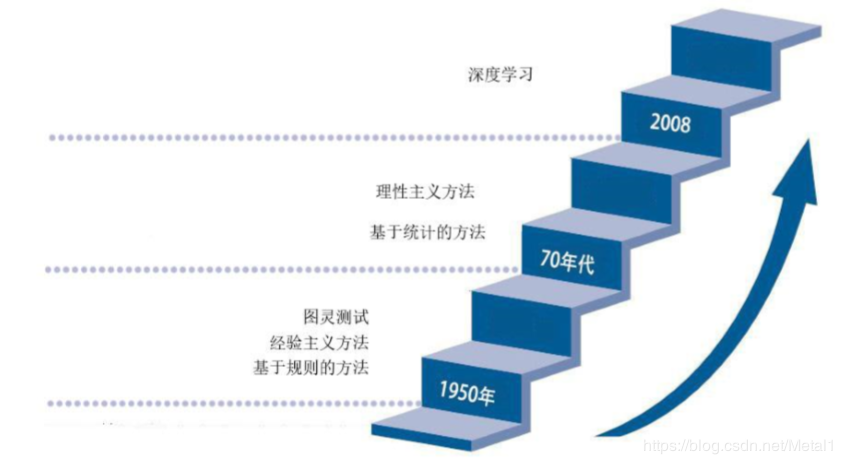
因此,梳理自然语言处理的发展历程对于我们更好地 了解自然语言处理这一学科有着重要的意义,历程大概分为三部分。
1. 基于规则
2. 基于统计
3. 基于深度学习
*****
## 开端
1950 年图灵提出了著名的“图灵测试”,这一般被认为是自然语言处理思想的开端, 20 世纪 50 年代到 70 年代自然语言处理主要采用基于规则的方法,研究人员们认为自然语 言处理的过程和人类学习认知一门语言的过程是类似的,所以大量的研究员基于这个观点来 进行研究,这时的自然语言处理停留在理性主义思潮阶段,以基于规则的方法为代表。但是 基于规则的方法具有不可避免的缺点,首先规则不可能覆盖所有语句,其次这种方法对开发 者的要求极高,开发者不仅要精通计算机还要精通语言学,因此,这一阶段虽然解决了一些 简单的问题,但是无法从根本上将自然语言理解实用化。
## 发展
70 年代以后随着互联网的高速发展,丰富的语料库成为现实以及硬件不断更新完善, 自然语言处理思潮由理性主义向经验主义过渡,基于统计的方法逐渐代替了基于规则的方 法。贾里尼克和他领导的 IBM 华生实验室是推动这一转变的关键,他们采用基于统计的方 法,将当时的语音识别率从 70%提升到 90%。在这一阶段,自然语言处理基于数学模型和统 计的方法取得了实质性的突破,从实验室走向实际应用。
## 而今
从 2008 年到现在,在图像识别和语音识别领域的成果激励下,人们也逐渐开始引入深 度学习来做自然语言处理研究,由最初的词向量到 2013 年 word2vec,将深度学习与自然语 言处理的结合推向了高潮,并在机器翻译、问答系统、阅读理解等领域取得了一定成功。深 度学习是一个多层的神经网络,从输入层开始经过逐层非线性的变化得到输出。从输入到输 出做端到端的训练。把输入到输出对的数据准备好,设计并训练一个神经网络,即可执行预 想的任务。RNN 已经是自然语言护理最常用的方法之一,GRU、LSTM 等模型相继引发了 一轮又一轮的热潮。
*****
此后,基于**双向自编码的预训练模型BERT**刷新了NLP各大任务,由此,掀起了预训练狂潮,其改良版本也如雨后春笋一般浮现。
1. ERINE (加入中文实体信息)
2. RoBERTa (加大语料及参数)
3. ALBERT (降低参数,加大语料)
4. distilBERT (采用模型蒸馏技术,以减小稍许)
...
当然,**基于自回归的预训练模型**也取得不错的成果。
1. XLNET
2. GPT-2
此外,对于**序列到序列任务**,微乳也推出了两种预训练方式
1. UniLM
2. Mass
