# 数据建模-数据集加载
*****
**以下内容均按照作者的个人思路去编排,如果有更好的想法等,则以自己的优先**
*****
## 利用**Open CV2**读取、加载数据集
> 个人猜测,比赛中“**数据集的加载与代码了解**”是合二为一的,所以首先得弄懂如何加载
*****
### **零、准备**
1. 提前下载好图片数据,并最好跟自己的代码文件放在**同一目录**下
> ①这里使用的数据集是来自Kaggle的Intel图像分类
> ②“Intel图像分类”数据集已分为Train、Test和Val,我们将仅使用训练数据集学习如何使用不同的库加载数据集【注:Train:训练集 Test:测试集 Val:验证集】
2. 了解深度学习模型加载自定义数据集的典型步骤
> ① 打开图像文件。文件的格式可以是JPEG、PNG、BMP等。
> ② 调整图像大小以匹配深度学习模型的输入层的输入大小。
> ③ 将图像像素转换为浮点数据类型。
> ④ 将图像标准化,使像素值在0到1之间。
> ⑤ 深度学习模型的图像数据应该是一个numpy数组或一个张量对象【张量:(人工智能领域:多维数组】。
3. 分析图片数据中包含哪些内容
> 易知图片数据中的每个类都是一个文件夹,其中包含该特定类的图像,如"buildings-建筑物图片"
*****
### **一、加载**【包含"深度学习模型加载自定义数据集的典型步骤"】
1. 导入所需的库
```
【适用于Tensorflow 1.X】:
import pandas as pd
import numpy as np
import os
import cv2
from matplotlib import pyplot as plt
import matplotlib.image as mpimg
%matplotlib inline
----------------------------------------------------------------------------------------------------------------------
【适用于Tensorflow 2.X】:
import pandas as pd
import numpy as np
import os
import cv2
from matplotlib import pyplot as plt
import matplotlib.image as mpimg
%matplotlib inline
```
2. 从其中一个文件夹中随机输出五张图像
~~~text
import random
plt.figure(figsize=(20,20)) #【创建自定义图像的宽与高】
img_folder=r'CV\Intel_Images\seg_train\seg_train\forest' #【自定义目录】
for i in range(5):
file = random.choice(os.listdir(img_folder)) #【在自定义目录里随机抽图,赋给file】
image_path= os.path.join(img_folder, file) #【将自定义目录的路径与file拼接】
img=mpimg.imread(image_path) #【读取自定义目录下的图像】
ax=plt.subplot(1,5,i+1) #【把显示界面分割成1*5的网格,其中,第一个参数是行数,第二个参数是列数,第三个参数表示图形的编号,之后赋予ax】
ax.title.set_text(file) #【ax的标题设置为抽取的图像名称】
plt.imshow(img) #【展示】
~~~
**如图**
3. 设置用于加载数据集的图像维度和源文件夹
~~~text
IMG_WIDTH=200 #【设置图像宽度为200】
IMG_HEIGHT=200 #【设置图像高度为200】
img_folder=r'CV\Intel_Images\seg_train\seg_train\' #【图像路径设置】
~~~
*****
### **二、设置**
从文件夹中的图像创建图像数据和标签
~~~text
def create_dataset(img_folder): #【定义 create_dataset函数(即创建图像数据)】
img_data_array=[] #【图像数据用数组保存】
class_name=[] #【类名用数组保存】
for dir1 in os.listdir(img_folder): #【返回指定(这里是'img_folder')的文件夹包含的文件或文件夹的名字的文件夹为dir1】
for file in os.listdir(os.path.join(img_folder, dir1)): #【返回指定(这里是'img_folder'和'dir1'拼接在一起)的文件夹包含的文件或文件夹的名字的文件夹为file】
image_path= os.path.join(img_folder, dir1, file) #【将'img_folder'、'dir1'、'file'目录拼接在一起,赋予image_path】
image= cv2.imread( image_path, cv2.COLOR_BGR2RGB) #【读取'image_path'里的图片,并将其由BGR模式转为RGB模式】
image=cv2.resize(image, (IMG_HEIGHT, IMG_WIDTH),interpolation = cv2.INTER_AREA) #【将图像进行缩放,读取'image'里的内容,高与宽为之前设定的图像维度的值,利用'像素区域关系进行重采样’进行插值】
image=np.array(image) #【将image的数据存储到数组中】
image = image.astype('float32') #【将数据类型强制转换为float32】
image /= 255 #【将图像数组归一化,使值在0和1之间,这有助于更快地收敛。】
img_data_array.append(image) #【呈现image数组中的数据】
class_name.append(dir1) #【呈现dir1的类名】
return img_data_array, class_name #【返回'img_data_array','claa_name'】
img_data, class_name =create_dataset(r'CV\Intel_Images\seg_train\seg_train') #【提取图像数组和类名】
~~~
知识补充:
> * 插值:利用已知邻近像素点的灰度值(或rgb图像中的三色值)来产生未知像素点的灰度值,以便由原始图像再生出具有更高分辨率的图像。
> * 计算机里存储图片是按照’先行后列‘存储,也符合数组的规律形式
*****
### **三、划分**
选取训练数据集、测试数据集
```
# -*- coding: utf-8 -*-
"""
将数据集划分为训练集,验证集,测试集
"""
import os
import random
import shutil
# 创建保存图像的文件夹
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
random.seed(1) # 随机种子
# 1.确定原图像数据集路径
dataset_dir = "D:\Source Code\Python\Conda\AI\exampls\seg_train\seg_train" ##原始数据集路径
# 2.确定数据集划分后保存的路径
split_dir = "D:/Source Code/Python/Conda/AI/exampls/test" ##划分后保存路径【!一定是反斜杠!】
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "val")
test_dir = os.path.join(split_dir, "test")
# 3.确定将数据集划分为训练集,验证集,测试集的比例
train_pct = 0.9
valid_pct = 0.1
test_pct = 0
# 4.划分
for root, dirs, files in os.walk(dataset_dir):
for sub_dir in dirs: # 遍历0,1,2,3,4,5...9文件夹
imgs = os.listdir(os.path.join(root, sub_dir)) # 展示目标文件夹下所有的文件名
imgs = list(filter(lambda x: x.endswith('.jpg'), imgs)) # 取到所有以.jpg结尾的文件,如果改了图片格式,这里需要修改
random.shuffle(imgs) # 乱序图片路径
img_count = len(imgs) # 计算图片数量
train_point = int(img_count * train_pct) # 0:train_pct
valid_point = int(img_count * (train_pct + valid_pct)) # train_pct:valid_pct
for i in range(img_count):
if i < train_point: # 保存0-train_point的图片到训练集
out_dir = os.path.join(train_dir, sub_dir)
elif i < valid_point: # 保存train_point-valid_point的图片到验证集
out_dir = os.path.join(valid_dir, sub_dir)
else: # 保存valid_point-结束的图片到测试集
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir) # 创建文件夹
target_path = os.path.join(out_dir, imgs[i]) # 指定目标保存路径
src_path = os.path.join(dataset_dir, sub_dir, imgs[i]) #指定目标原图像路径
shutil.copy(src_path, target_path) # 复制图片
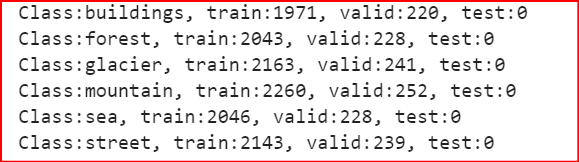
print('Class:{}, train:{}, valid:{}, test:{}'.format(sub_dir, train_point, valid_point-train_point,
img_count-valid_point))
```
结果为: